Hot Chips 2016: Exynos M1 Architecture Disclosed
by Joshua Ho on August 25, 2016 8:00 AM EST- Posted in
- Mobile
- Samsung
- Hot Chips
- Exynos
- LSI
- Trade Shows
- Exynos 8890
- Exynos M1

While we can always do black-box testing to try and get a handle for what a CPU core looks like, there’s really only so much you can do given limited time and resources. In order to better understand what an architecture really looks like a vendor disclosure is often going to be as good as it gets for publicly available information. The Exynos M1 CPU architecture is Samsung’s first step into a custom CPU architecture for an mobile SoC. Custom CPU architectures are hardly a trivial undertaking, so it’s unlikely that a company would make the investment solely for a marketing bullet point.

With that said, Samsung has provided some background for the Exynos M1, claiming that the design process started about 3 years ago in 2013 around the time of the launch of the Galaxy S4. Given the issues that we saw with Cortex A15 in the Exynos 5410, it's not entirely unsurprising that this could have been the catalyst for a custom CPU design. However, this is just idle speculation and I don't claim to have any knowledge of what actually led to Exynos M1.
At a high level, Samsung pointed out that the Exynos M1 is differentiated from other ARM CPU designs by advanced branch prediction, roughly four instructions decoded per cycle, as well as the ability to dispatch and retire four instructions per cycle. As the big core in the Exynos 8890, it obviously is an out of order design, and there are some additional claims of multistride/stream prefetching and improved cache design.
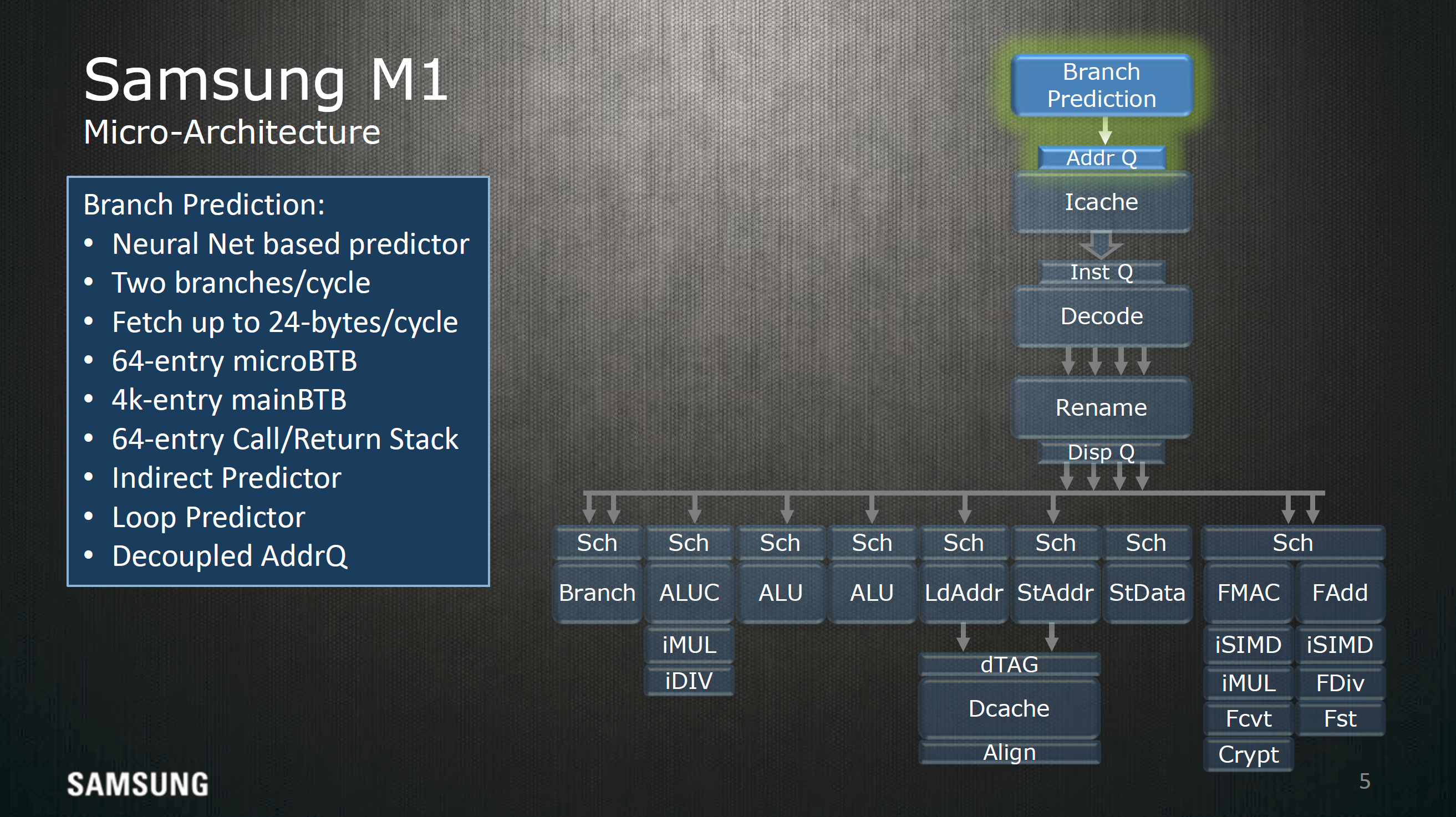
Starting with branch prediction, the major highlight point here is that the branch predictor uses a perceptron of sorts to reduce the rate at which branches miss. If you understand how pipelining works, it takes a significant amount of time to reload saved state and invalidate the execution that occurred after an incorrect branch. I’m no expert here but it looks like this branch predictor also has the ability to do multiple branch predictions at the same time, either as a sort of multi-level branch predictor or handling multiple successive branches. Perceptron branch prediction isn't exactly new in academia or in real-world CPUs, but it's interesting to see that this is specifically called out when most companies are reluctant to disclose such matters.
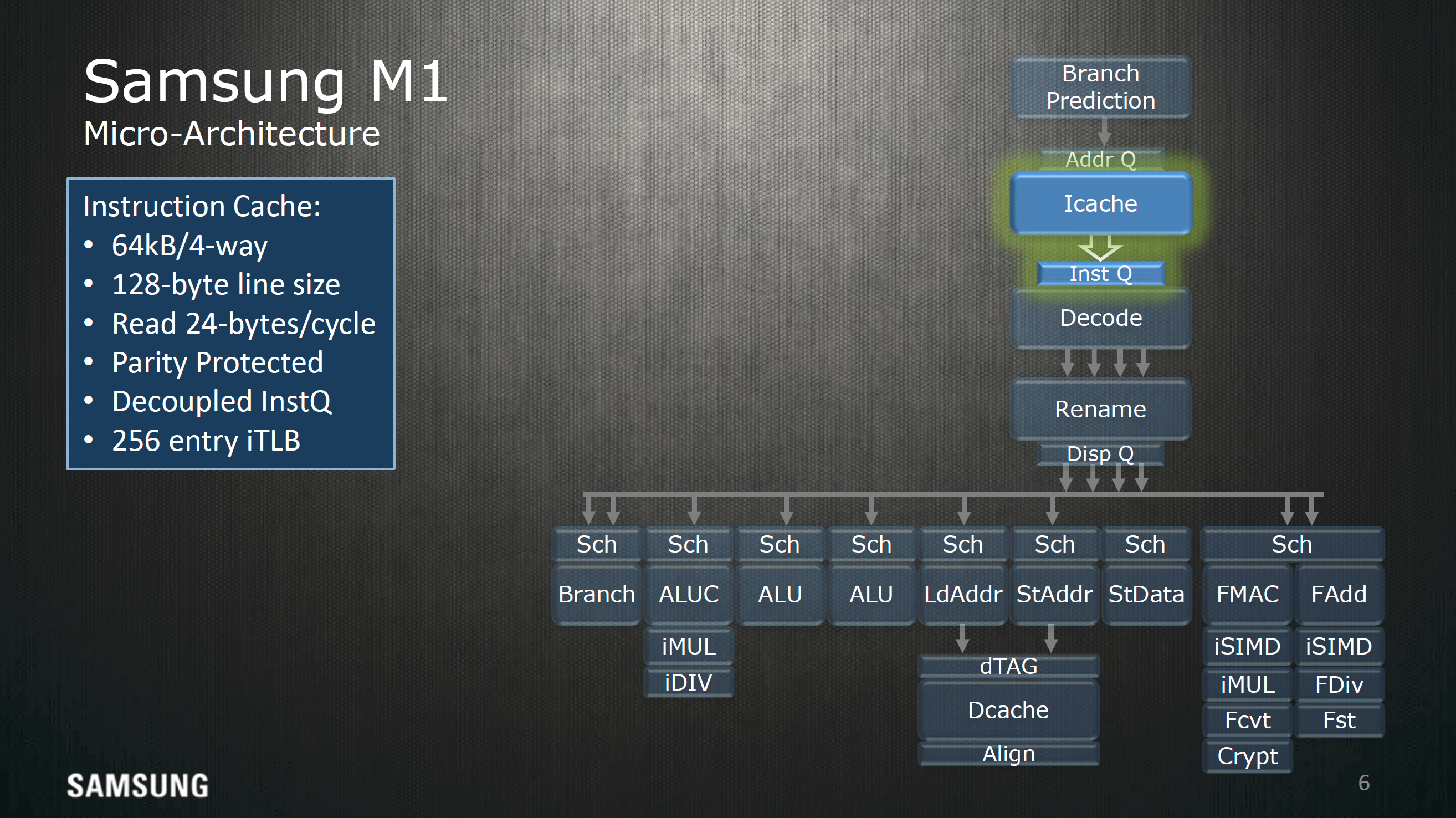
Moving past branch prediction we can see some elements of how the cache is set up for the L1 I$, namely 64 KB split into four sets with 128-byte line sizes for 128 cache lines per set, with a 256 entry TLB dedicated to faster virtual address translation for instructions. The cache can read out 24 bytes per cycle or 6 instructions if the program isn’t using Thumb instruction encoding.
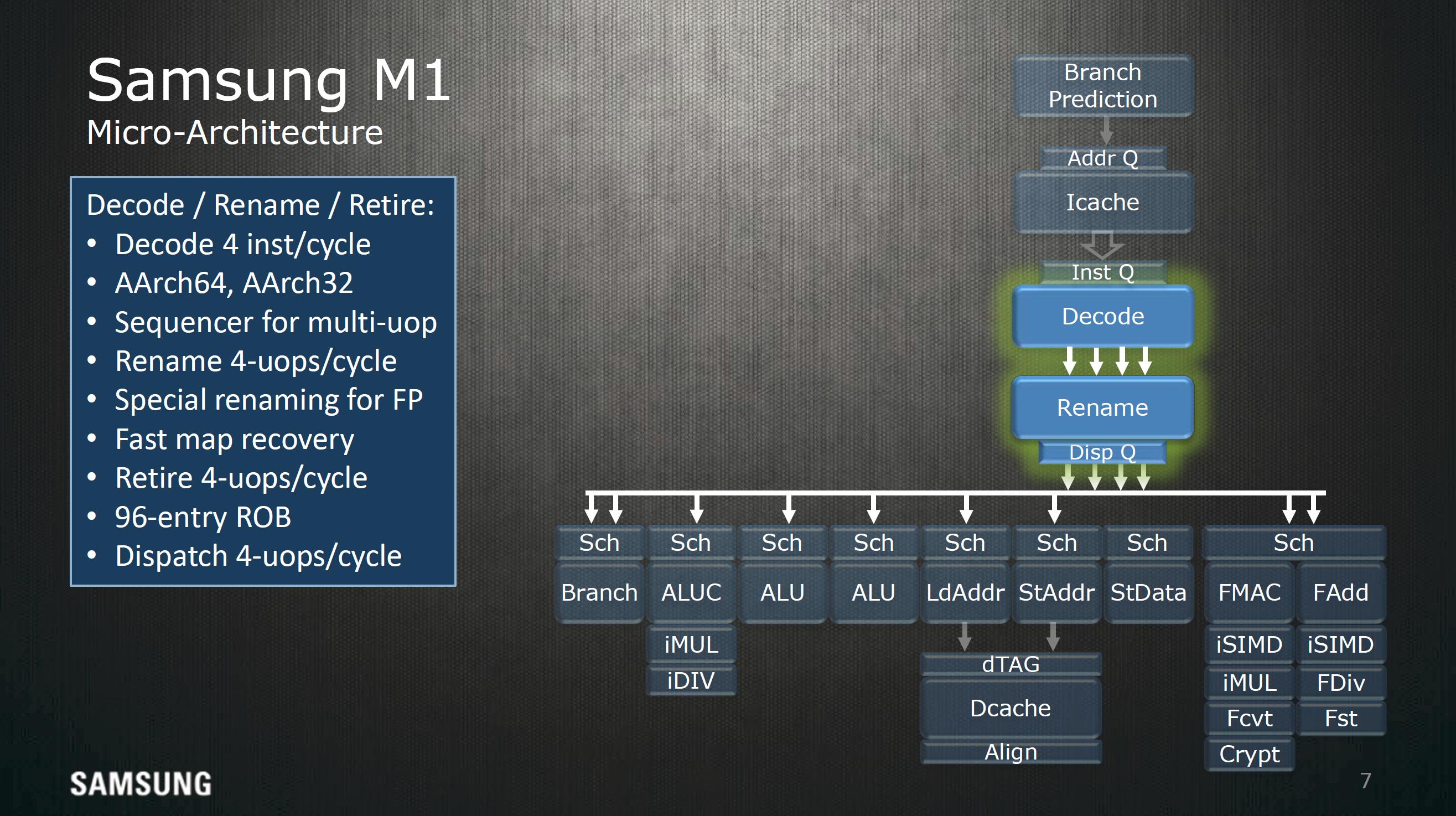
On the instruction side we find decode, rename, and retire stages, register rename logic. The decode stage can handle up to 4 instructions per clock while the retire, and dispatch systems are all capable of handling four instructions every cycle, so best case throughput is going to be four instructions per cycle assuming the best-case scenario that the ARM instruction is a single micro-operation.
Other areas of interest include the disclosure of a 96 entry reorder buffer, which defines how many instructions can be in-flight at any given time. Generally speaking more entries is better for extracting ILP here, but it’s important to understand that there are some significant levels of diminishing returns in going deeper, so doubling the reorder buffer doesn’t really mean that you’re going to get double the performance or anything like that. With that said, Cyclone’s reorder buffer size is 192 entries and the Cortex A72 has 128 entries, so the size of this buffer is not really anything special and is likely a bit smaller in order to cut down on power consumption.
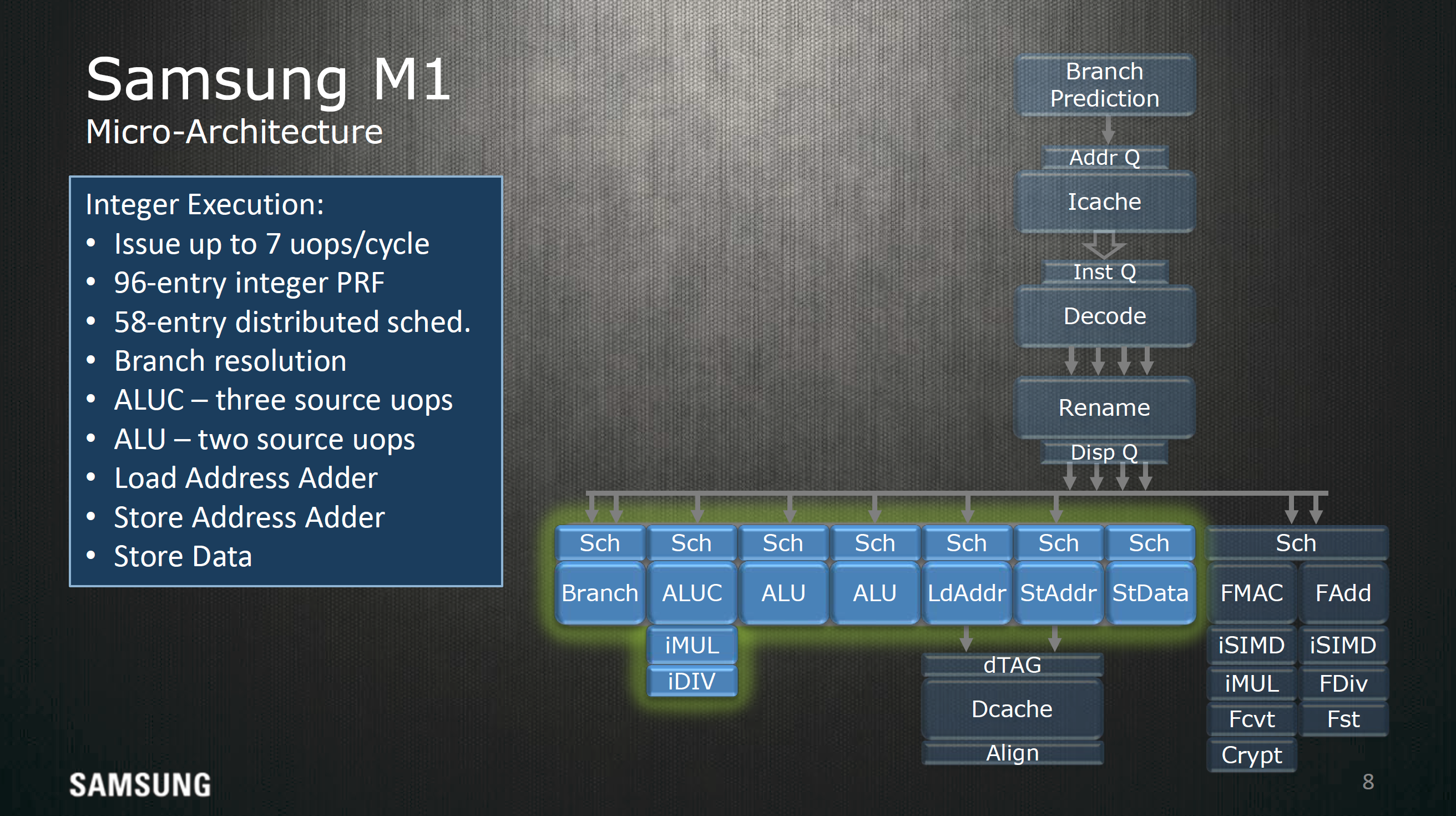
For integer execution the Exynos M1 has seven execution ports, with most execution pipelines getting their own dedicated schedulers. It's to be noted that the branch monitor is able to be fed 2 µops per cycle. On the floating point side it looks like almost everything shares a single 32 entry scheduler, which can do a floating point multiply-accumulate operation every 5 cycles and a floating point multiplication every 4 cycles. Floating point addition is a 3 cycle operation.
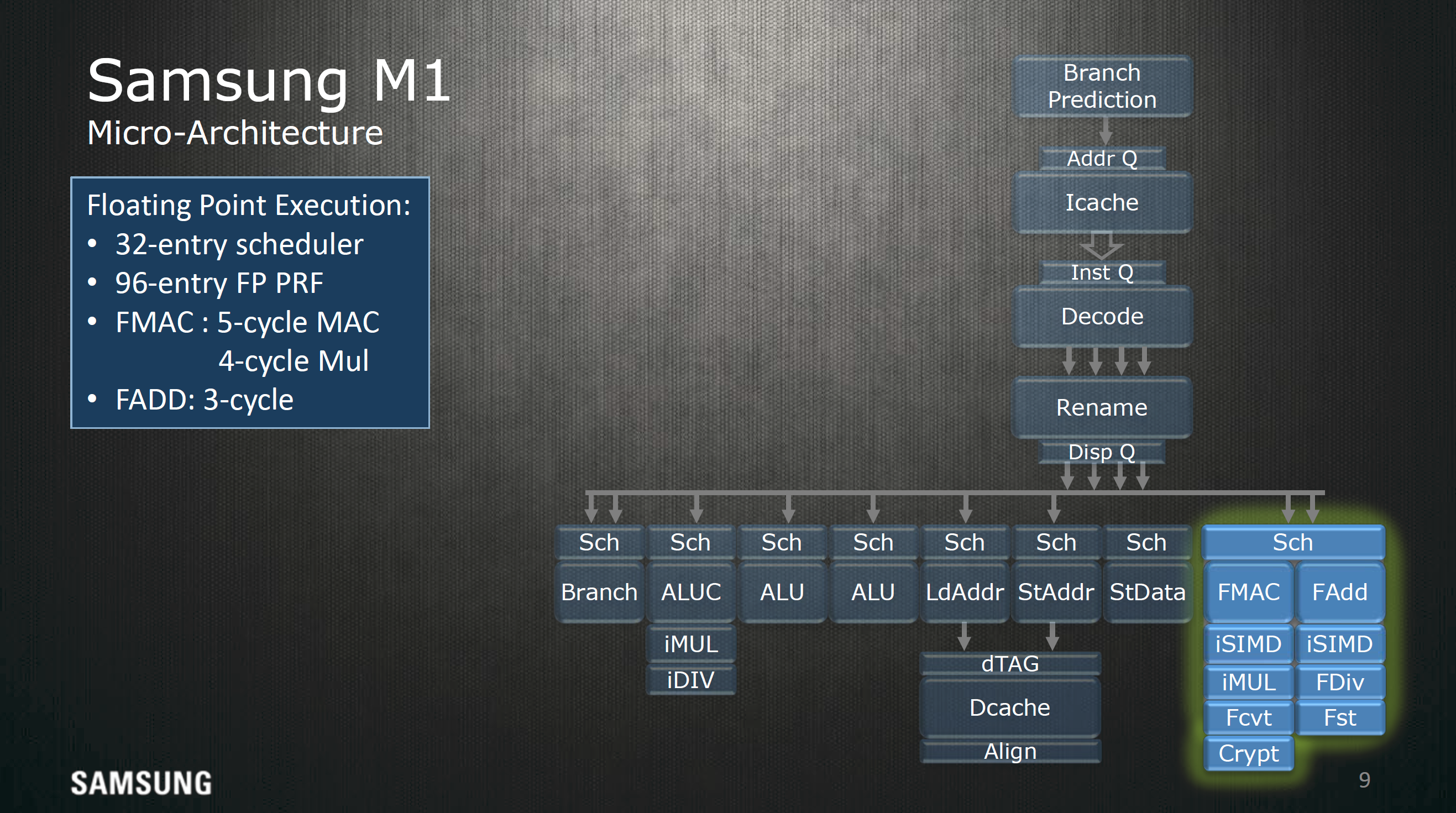
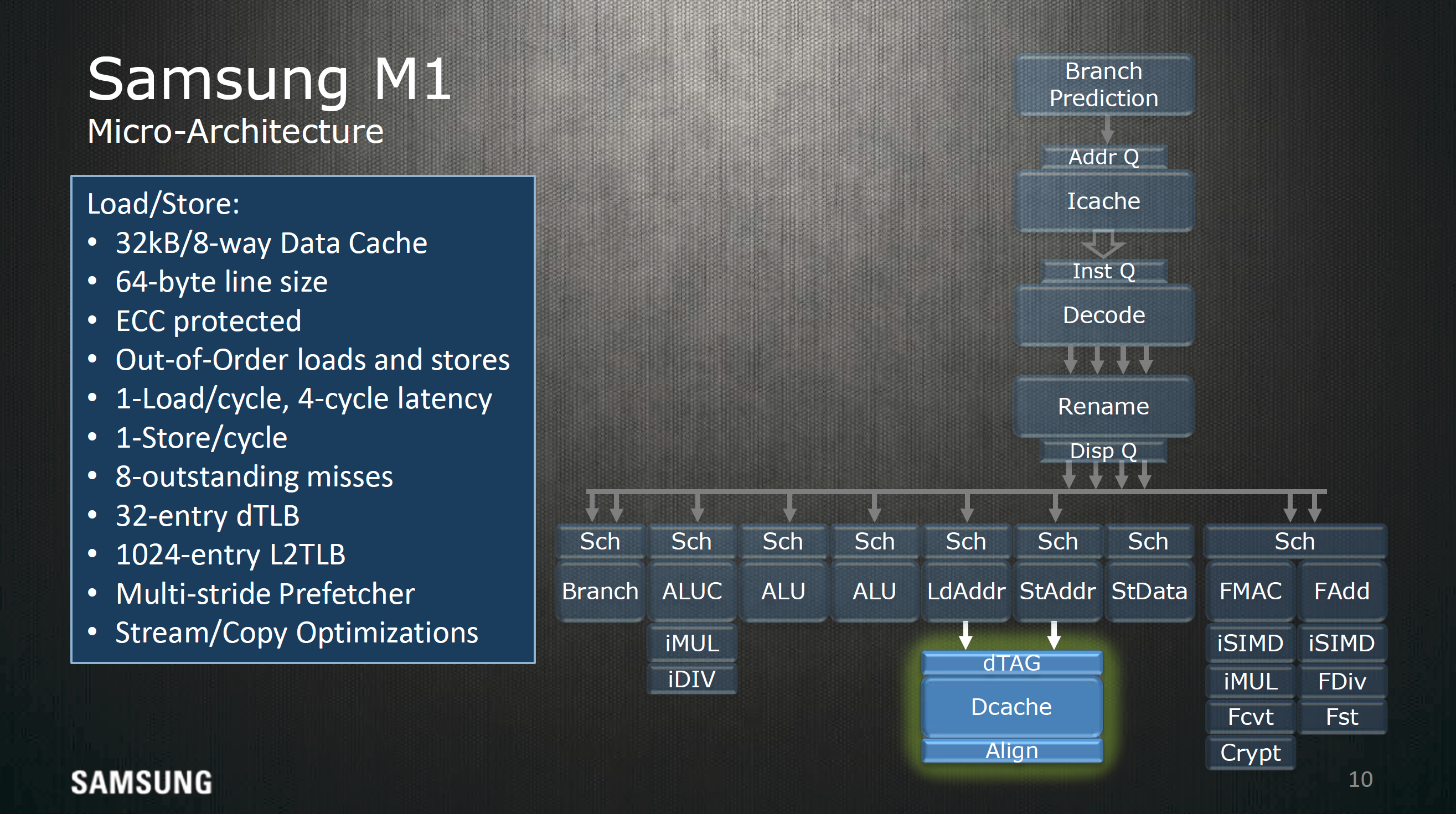
For loads and stores, a 32 KB, 8-way set associative cache with 64 byte line size is used as well as a 32 entry dTLB and 1024 entry L2 dTLB to hold address translations and the associated data for any given address, and allows out of order loads and stores to reduce visible memory latency. Up to 8 outstanding cache misses for loads can be held at any given time, which reduces the likelihood of stalling, and there are additional optimizations for prefetching as well as optimizations for other types of memory traffic.
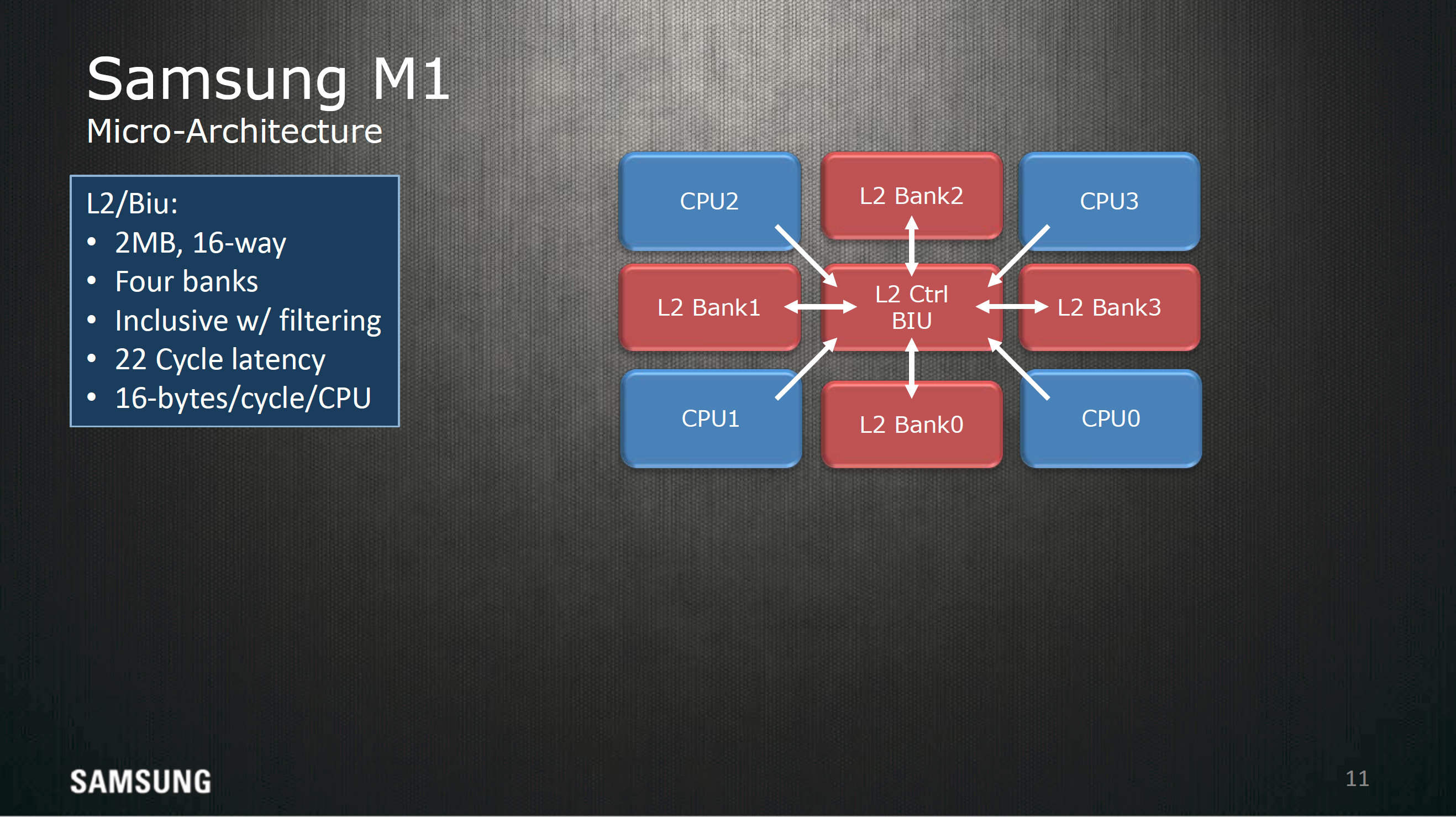
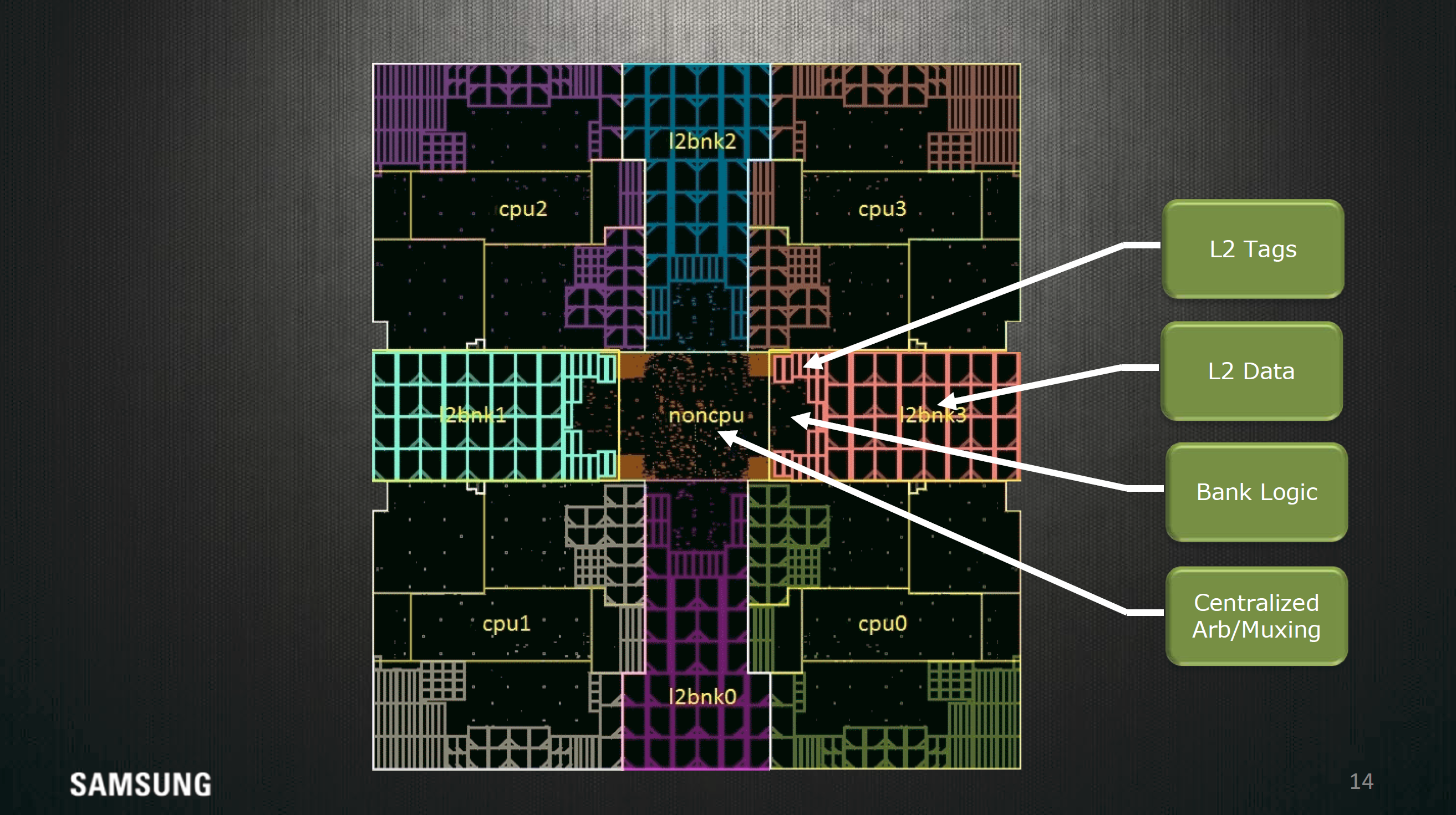
The L2 cache here is 2MB shared across all cores split into 16 sets. This memory is also split into 4 banks and has a 22 cycle latency and has enough throughput to fill two AArch64 registers every cycle, and if you look at the actual floorplan this diagram is fairly indicative of how it actually looks on the die.
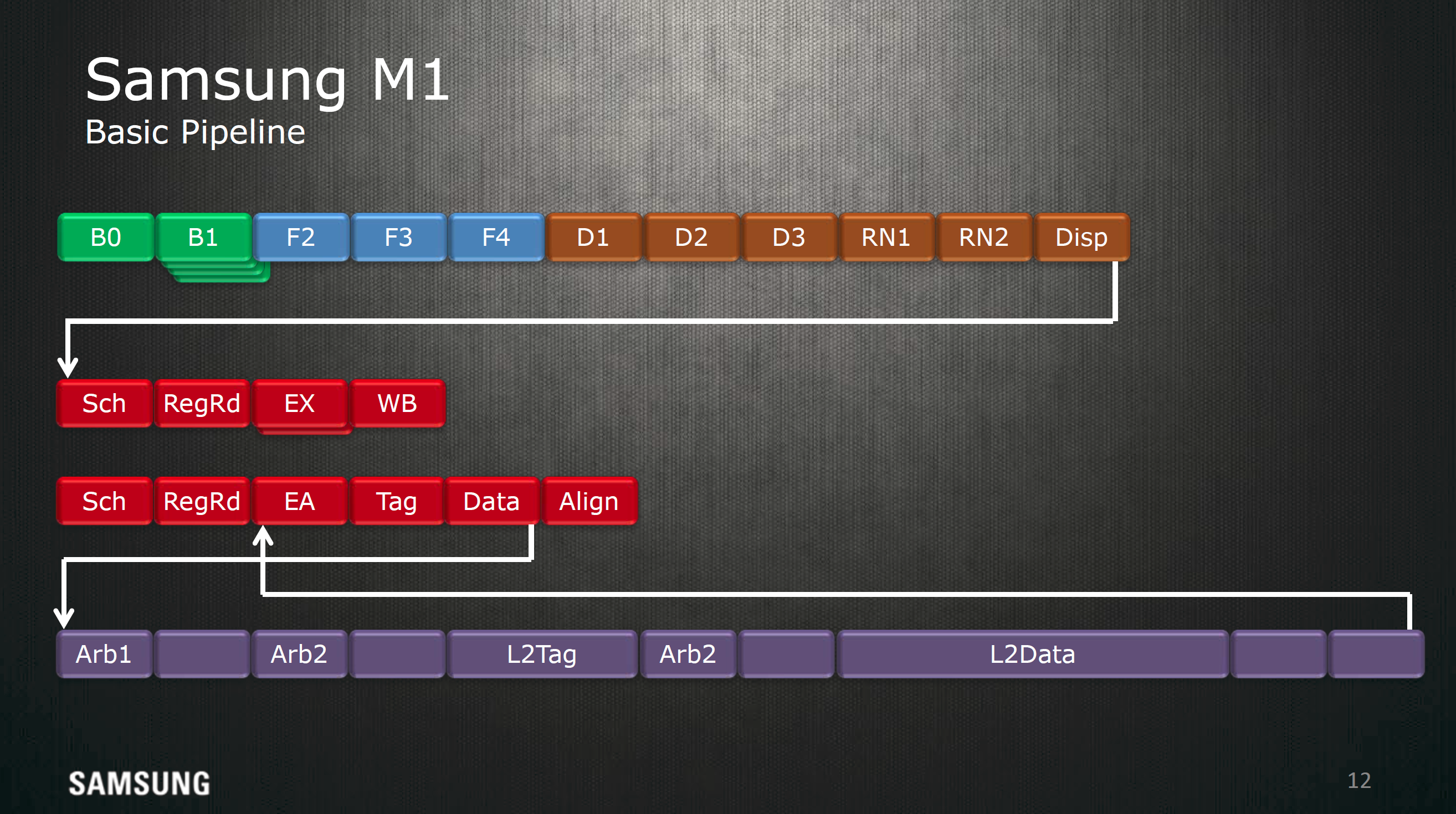
Samsung also highlighted the pipeline of the Exynos M1 CPU at a high level. If you're familiar with how CPUs work you'll be able to see how the basic stages of instruction fetch, decode, execution, memory read/write, and writeback are all present here. Of course, due to the out of order nature of this CPU there are also register rename, dispatch, and scheduling stages.
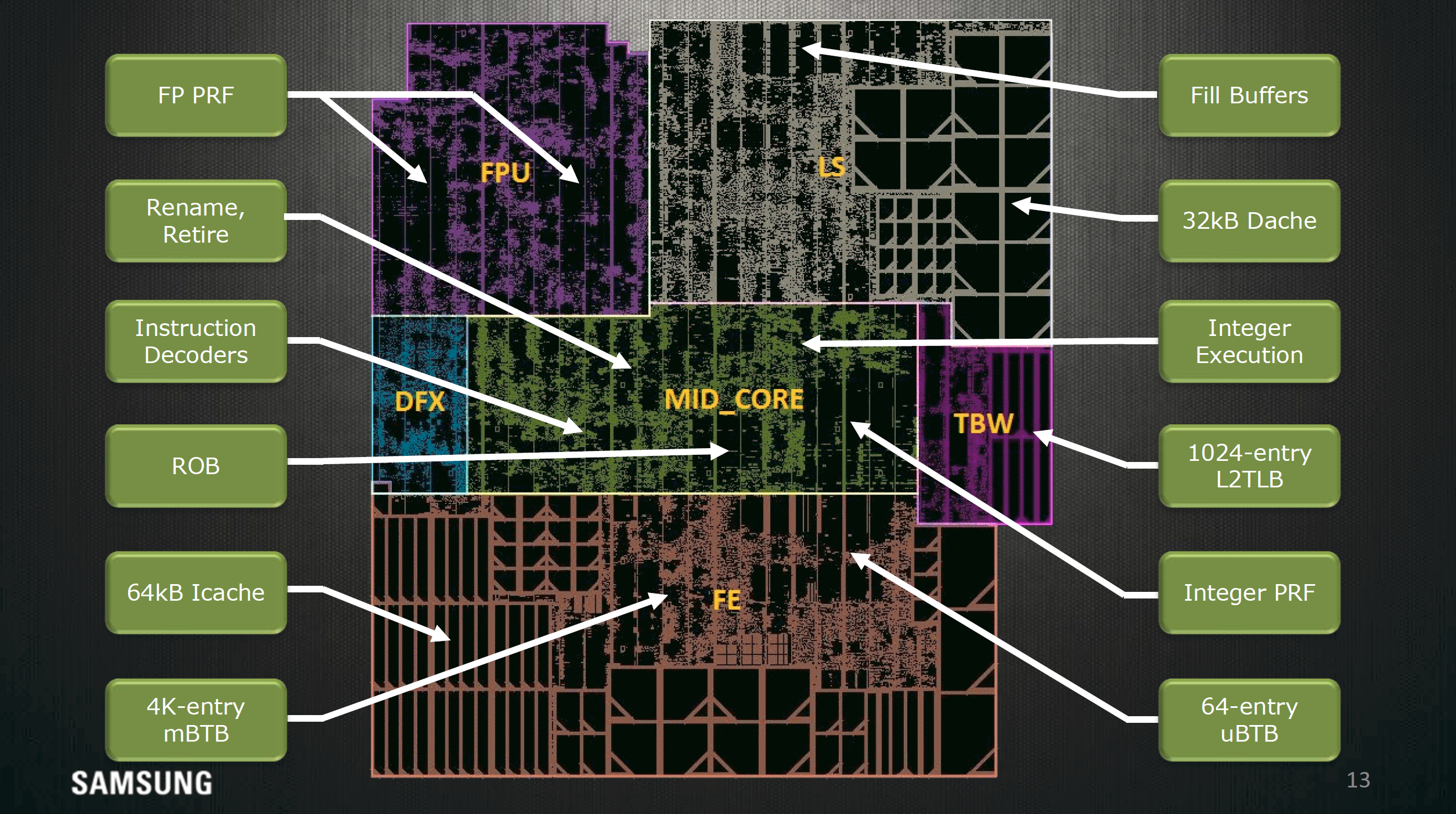
It's fairly rare to see this kind of in-depth floorplanning shots from the designers themselves, so this slide alone is interesting to see. I don't have a ton to comment on here but it's interesting to see the distances of all the components of the CPU from the center of the core where most of the execution is happening.
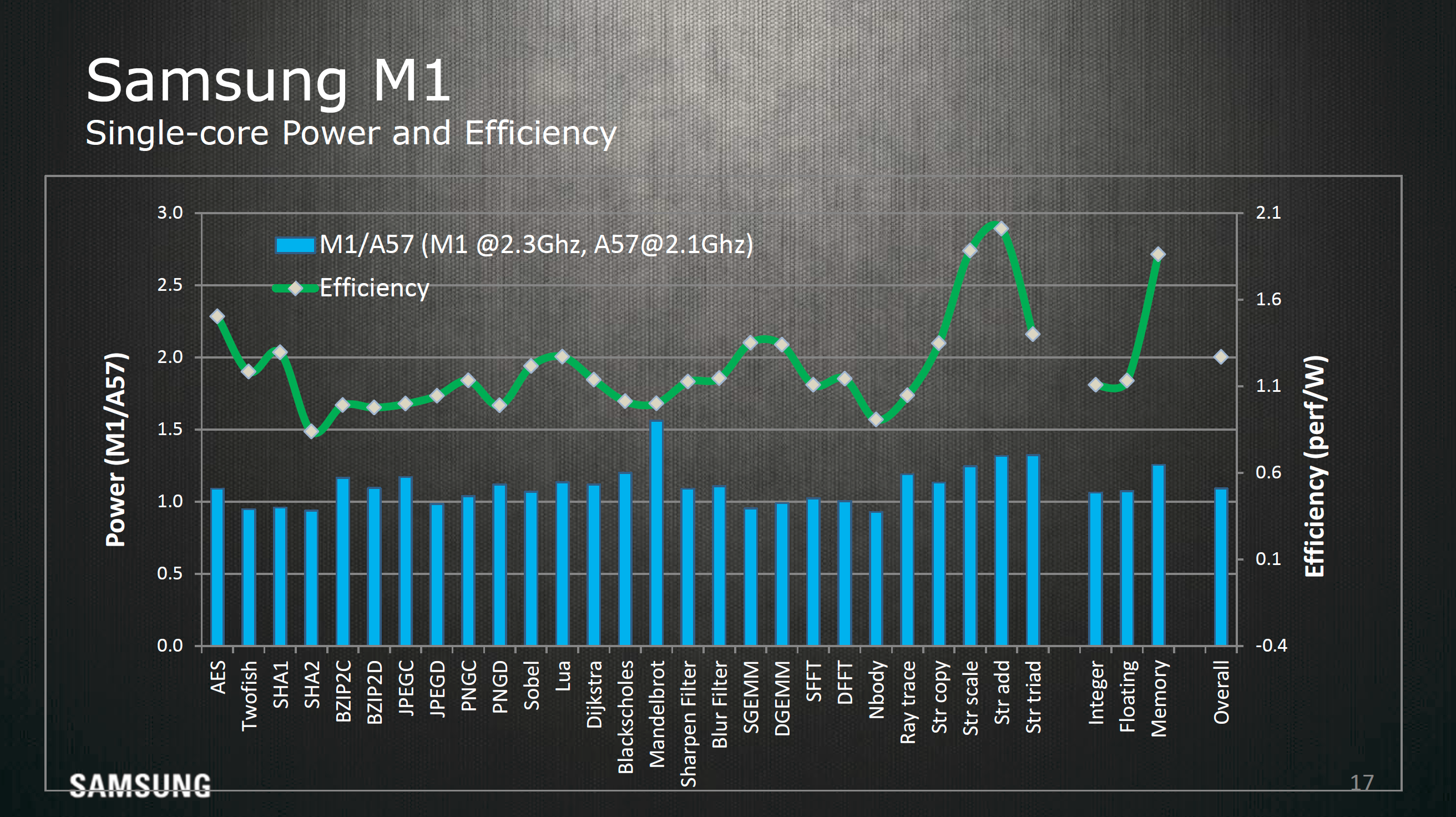
Overall, for Systems LSI's first mobile CPU architecture it's impressive just how quickly they turned out a solid design in three years from inception to execution. It'll be interesting to see what they do next once this design division really starts to hit its stride. CPU architectures are pipelined to some extent, so even if it takes three years to design one, if the mobile space as a whole is anything to go by then it's likely that we'll be seeing new implementations and designs from this group in the next year or two. Given the improvements we've seen from the Exynos 5420 to 7420 it isn't entirely out of question that we could see much more aggressive execution here in the near future, but without a crystal ball it's hard to say until it happens.








29 Comments
View All Comments
jayfang - Thursday, August 25, 2016 - link
So if I'm reading this (tricky) graph right, overall a M1 uses more power than A57 110% but is more efficient 120%. That puts it in a bracket of about same perf, but worse power than A72. Also no talk of die size?How much did this effort cost them, because so far the ROI is questionable.
Meteor2 - Friday, August 26, 2016 - link
Indeed. But it's a work in progress -- they must feel that there's more to come.name99 - Thursday, August 25, 2016 - link
" I’m no expert here but it looks like this branch predictor also has the ability to do multiple branch predictions at the same time, either as a sort of multi-level branch predictor or handling multiple successive branches. Perceptron branch prediction isn't exactly new in academia or in real-world CPUs, but it's interesting to see that this is specifically called out when most companies are reluctant to disclose such matters."The usual situation with branch prediction (on modern high-end CPUs) is that the fetch engine predicts
- the next address of interest AND
- how far along from that next address to load instructions.
Instruction load ends at the smallest of
- the end of the cache line OR
- the maximum width of the bus from the I-cache into the I-queue (which Samsung tells us is 6 instructions) OR
- the next branch point (which is known because those instructions were tagged as such when the line was first pulled into the I-cache)
NOW suppose that the third case holds AND that the predictor predicts that this next branch point is NOT taken. Then it is obviously reasonable to extend this fetch through that branch and on till either the first two conditions hold, or yet another branch point is encountered.
This is the simplest way to extend branch prediction to utilize two predictions per cycle, and is certainly good enough for a two-wide machine. I am sure that's what Samsung is doing.
(IBM does this already with POWER8 if not earlier. My guess is that Apple also already do it. It makes more sense to do this the wider your CPU becomes.)
As for perceptrons:
- It's not clear that they are the absolute best possible. The last time a competition was held against various predictors (given a fixed transistor budget, etc) the winner was the TAGE predictor. I've seen various vague hints that current Intel uses TAGE-like predictors, and A9 has branch accuracy comparable to Intel, suggesting Apple also use it.
https://hal.inria.fr/hal-00639193/document
Samsung is not alone here. Zen also uses Perceptron, and it will be interesting once it is released to see how it compares with Intel on interpreters and similar code that subjects predictors to extreme stress.
Eden-K121D - Friday, August 26, 2016 - link
A hybrid approach would have been much bettername99 - Thursday, August 25, 2016 - link
More interesting is what is omitted.There appears not to be a decoded-operations cache, just a loop buffer. Such a cache does not increase performance directly, but does allow for substantial (maybe 20%) power reduction.
I'm also guessing they're not doing memory speculation (ie executing loads even when there are prior stores with unresolved addresses). Such speculation is surprisingly worthwhile in terms of performance boost, but requires extra machinery to recover when the speculation goes wrong. Intel added it a while ago, and we know Apple does it based on a lawsuit by UW-Madison (which also sued Intel but settled before trial --- presumably when Samsung adds this they'll first pay UW-Madison, but it's Samsung so who knows :-) ).
And as always, more and more of the performance is driven by details that are not captured in the numbers that are released. What's the quality of the prefetchers, and the branch predictors? What's the quality of the memory controller? What algorithms are used to decide on which cache lines to replace? etc etc
In terms of sophistication it looks to me just slightly beyond Apple's Swift (though obviously running at higher frequency). It obviously is 4 wide rather than 3 wide, and adds the 64-bit ISA, but those are fairly mechanical additions.
That's not a criticism --- everyone has to start somewhere --- but I think it calibrates the extent of the achievement, and the extent of the gap remaining. What will be interesting will be to see whether they add sophistication as fast as Apple did. (Most obviously: clustering of two 3-wide units in Cyclone, fixing up random weak spots in branch prediction, the multipliers, the FPUs, the caches in Typhoon, dramatically improved memory controller in Twister).
MrCommunistGen - Thursday, August 25, 2016 - link
name99: I really appreciate your analysis.For those of us who aren't completely immersed in the intricacies of mobile CPU architecture the additional insight is really interesting. We've all seen how M1 performs compared to A72 and S820. Seeing block diagrams and a description of M1 (in the original article) is interesting, but without the added context of how it compares to other architectures this interest was - at least to me - more academic.
You've added to the topic and in doing so I feel you've bettered my understanding of the subject.
saratoga4 - Thursday, August 25, 2016 - link
> which can do a floating point multiply-accumulate operation every 5 cyclesAre you sure that is every 5 cycles and not 5 cycle latency? I think the FP unit would be pipelined.
Andrei Frumusanu - Thursday, August 25, 2016 - link
Correct it's 1 MAC per cycle with 5 cycle latency.darkich - Friday, August 26, 2016 - link
I have a question for Joshua and Andrei, not keeping high hopes I'll get the answer but still.. Which design you like better, the M1 or Cortex A73?