The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeep Learning, GPUs, and NVIDIA: A Brief Overview
To get terminology straight, ‘machine learning,’ or the even more generic term ‘AI’ is sometimes used interchangeably for ‘deep learning.’ Technically, they each refer to different things, with ML being a subset of AI, and DL being a subset of ML.
Picture from Intel
DL acquires its name from ‘deep neural networks,’ which are ultimately designed to recognize patterns in data, produce a related prediction, receive feedback on the prediction’s accuracy, and then adjust itself based on the feedback. When the feedback is based on an expected known output, this is ‘supervised learning.’ The computations occur on ‘nodes’, which are organized into ‘layers’: the original input data is first handled by the ‘input layer’ and the ‘output layer’ pushes out data that represents the model’s prediction. Any layers between those two are referred to as ‘hidden layers,’ of which deep neural networks have many hidden layers; originally, ‘deep’ meant having more than one hidden layer.
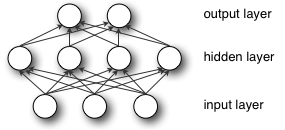
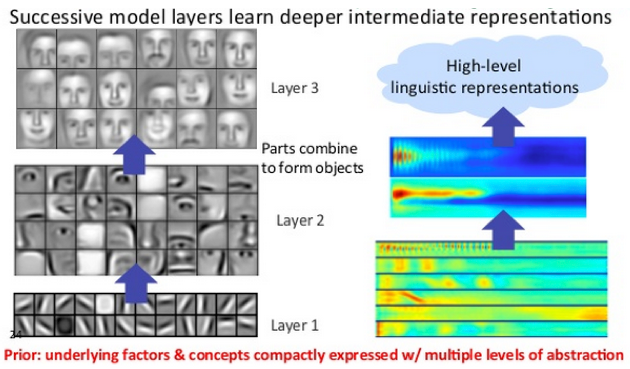
Images from DeepLearning4J
These hidden layers can operate in a hierarchy of increasing abstraction so that they can extract and distinguish non-linear features even from complicated input data. A standard example is in image recognition, where initial layers look for certain edges or shapes, which inform later layers that look for noses and eyes, and layers after that might look for faces. The final layers combine all this data to make a classification.
As input data progresses forward through the model, calculations include special internal parameters (weights). At the end, a loss function is produced, representing the error between the model’s prediction and the correct value. This error information is then used in running the model in reverse to calculate weight adjustments that will improve the model’s prediction. The weights are then updated. This sequence of a forward and backward pass (or backpropagation) comprises a single training iteration.
For inferencing, the process naturally excludes a backward pass and ultimately requires less computational intensity than training the model in the first place. In that sense, inferencing also has less need for higher precisions like FP32, and models can be appropriately pruned and optimized for deployment on particular devices. However, inferencing devices become much more sensitive to latency, cost, and power consumption, especially if on the edge.
Convolutional neural networks (CNNs or convnets) and recurrent neural networks are two important subtypes of (deep) neural networks, and the previous example with image recognition would be seen as a CNN. The convolutions themselves are an operation where input data and convolutional kernel are combined to form a feature map of some kind, transforming or filtering the original data to extract features. CNNs typically are ‘feedforward’, in the sense that data flows through the layers without looping. For RNNs (and variants like LSTM and GRU), there exists a separate weight that loops back to itself after every calculation, giving the net a sense of ‘memory.’ This allows the net to make time-aware predictions, useful in scenarios like text analysis, where a network would need to remember all the previous words with respect to the current one.
As much of deep learning math could be boiled down to linear algebra, certain operations can be re-written into GPU-friendlier matrix-matrix multiplications. When NVIDIA first developed and released cuDNN, one of the marquee implementations was accelerating convolutions based on lowering them into matrix multiplications. Among the cuDNN developments over the years is the 'precomputed implicit GEMM' convolution algorithm, which so happens to be the only algorithm that triggers convolution acceleration by tensor cores.
A Deep Learning Renaissance: (NVIDIA) GPUs Ascendant
Particularly for training, GPUs have become the DL accelerator-of-choice as most of these computations are essentially floating-point calculations in parallel, namely lots of matrix multiplications, with optimal performance requiring large amounts of memory bandwidth and size. These requirements neatly line up with the needs of HPC (and to a lesser extent, professional visualization), where GPUs need high precision floating point computation, large amounts of VRAM, and parallel compute capability.
Perhaps most importantly, is the underlying API and frameworks needed to utilize graphics hardware in this manner. For this, NVIDIA’s CUDA had come at the right time, just as deep learning started to regain interest, and was an easy launching point for further development:
- Release of CUDA & cuBLAS (2006/2007), and Tesla product line (2007)
- High-profile publications and achievements
- 2009, “Large-scale Deep Unsupervised Learning using Graphics Processors”
- 2012, AlexNet tops ILSVRC2012, running on cuda-convnet with two GTX 580s
- Release of cuDNN, integrated with Caffe dev branch (2014), later integrated by other DL frameworks
The development of CUDA and NVIDIA’s compute business coincided with research advances in machine learning, which had only just re-emerged as ‘deep learning’ around 2006. GPU accelerated neural network models provided orders-of-magnitude speed-ups over CPUs, and in turn re-popularized deep learning into the buzzword it is today. Meanwhile, NVIDIA’s graphics competitor at the time, ATI, was being acquired by AMD in 2006; OpenCL 1.0 itself only arrived in 2009, the same year AMD spun off their fabs as GlobalFoundries.
With DL researchers and academics successfully using CUDA to train neural network models faster, it was only a matter of time before NVIDIA released their cuDNN library of optimized deep learning primitives, of which there was ample precedent with the HPC-focused BLAS (Basic Linear Algebra Subroutines) and corresponding cuBLAS. So cuDNN abstracted away the need for researchers to create and optimize CUDA code for DL performance. As for AMD’s equivalent to cuDNN, MIOpen was only released last year under the ROCm umbrella, though currently is only publicly enabled in Caffe.
So in that sense, NVIDIA GPUs have become the reference implementation with respect to deep learning on GPUs, though the underlying hardware of both vendors are both suitable for DL acceleration.








65 Comments
View All Comments
SirPerro - Thursday, July 5, 2018 - link
The fancy girls with the macbook in starbucks are not exactly the target demographics for a deep learning desktop card. Or if they are, their laptop plays no part in that.This card is meant for professionals who can spend more than its price in google cloud training neural networks. For everyone else it makes absolutely no sense.
tipoo - Tuesday, July 3, 2018 - link
That Vega 56/64 in the iMac Pro pitched for deep learning also looks pretty underwhelming...Demiurge - Wednesday, July 4, 2018 - link
First of all, who "pitched" a iMac Pro for Deep Learning? Why would Apple put a $3k GPU in a model that is typically selling for $4-5k?Second, what model are you training on Vega that isn't sufficient with 2-4x the FP16/FP8/INT8 throughput of a 1080 Ti? How is that underwhelming?
mode_13h - Wednesday, July 4, 2018 - link
The GP102 in the 1080 Ti and Titan Xp doesn't support double-rate fp16. Just 4x int8 dot product, AFAIK, which you can't really use for training.Demiurge - Friday, July 6, 2018 - link
My point exactly since Vega does support double-rate FP16, among other things that the consumer GPU's typically don't support.As for the DP4A instruction, it is very much used in training.
INT8 datatype support is becoming more important, as is FP8 for reducing training time. Two more features Vega supports free of additional charge.
mode_13h - Friday, July 6, 2018 - link
If 8-bit int were acceptable for training, then why would anyone bother with fp16?Vega 10 doesn't have meaningful packed 8-bit support of any kind. It has only a couple such instructions that are intended for video compression. Vega 20 will change that, even adding support for packed 4-bit. But your comment seems oriented towards the current Vega.
Demiurge - Sunday, July 8, 2018 - link
Here's some reading (read the first line of the conclusion of the paper: Dettmers, 8-Bit Approximations for Parallelism in Deep Learning, ICLR 2016 https://arxiv.org/pdf/1511.04561.pdf):https://www.xilinx.com/support/documentation/white...
We shall disagree on "Vega 10 does not have meaningful packed 8-bit support". I'll let someone else argue with you, but I know what you mean. I don't agree, but I think I understand where you are coming from.
mode_13h - Monday, July 9, 2018 - link
Aww... don't pick a fight, then walk away!Here's the current Vega ISA doc. The only 8-bit packed arithmetic I see is unweighted blending and sum of absolute differences. AFAIK, this is not a useful degree of functionality for deep learning. If I'm wrong, show me.
http://developer.amd.com/wordpress/media/2013/12/V...
As for your first link, that deals with a *custom* 8-bit datatype, from what I can tell - not the int8 supported by Nvidia's DP4A or Vega 20 (from what we know).
Finally, your second link appears to deal *exclusively* with inference. Just like I said.
Nate Oh - Tuesday, July 10, 2018 - link
AMD says in the Vega whitepaper that INT8 SAD is applicable to several machine learning applications. It’s not new to Vega though. Various types of INT8 SAD dates back to earlier versions of GCN, and Kepler/Maxwell have single cycle packed INT8 SAD anyhow. But technically, according to AMD it is a useful degree of functionality.The real caveat to this is real-world DL performance has never been about raw operations per seconds, new instructions or not. This is one of the main points I wanted to convey with the article. (And to ward off any concerns, DeepBench does not fall under that because A) it uses DL kernels representative of DL applications and B) results are all in microseconds that are converted to TFLOPS using the kernel dimensions; TFLOPS is much is easier to present as a measure of performance.)
These instructions are only as good as their DL support. Even with ROCm/HIP/etc, Vega isn’t a drop-in replacement for a 1080 Ti, where you expect the hardware advantage to ‘just work’ in training. You have to port the model and retune with ROCm/MIOpen, HIP or OpenCL, etc., troubleshoot and make sure the hardware features you want to use is actually supported in MIOpen (if MIOpen support is even production-ready in your framework of choice), and the list goes on. Tuning guides for AMD architectures are not yet filled out on their ROCm documentation, and I couldn’t find out if packed INT8 xSAD is well-integrated as some DL primitive in MIOpen. MIOpen also still doesn’t support FP16 for RNNs, or training with CNNs, so no Rapid Packed Math there. Unless you implement these things yourself. I hope you know your GCN assembly.
What I’m trying to say is that for DL hardware (especially GPUs), software support and ecosystem are basically more important right now. If you’re more focused on the DL and not on the GPU side, then you’re more interested in the models and neural networking, less interested in low-level GPU tuning for a new architecture, only familiar with the CUDA ecosystem, and less willing to be a ROCm adventurer without immediate results that you need to publish or use.
So it’s true that Vega brings features to consumer GPUs that they don’t usually support, but using them for DL is not trivial. It’s easy to just say that it’ll work; I can tell you that sitting back in my chair I am super curious about Radeon SSG and DL’s perennial main memory bandwidth/size issue, but somebody has to go develop that implementation.
Which is a long way of stating, Vega doesn’t have packed 8-bit support as influential as Demiurge has claimed.
Links/References
https://radeon.com/_downloads/vega-whitepaper-11.6...
https://www.amd.com/Documents/GCN_Architecture_whi... (SAD for pixel shaders introduced)
http://rocm-documentation.readthedocs.io/en/latest...
http://rocm-documentation.readthedocs.io/en/latest...
https://www.hotchips.org/wp-content/uploads/hc_arc...
https://devtalk.nvidia.com/default/topic/966491/te...
mode_13h - Tuesday, July 10, 2018 - link
> AMD says in the Vega whitepaper that INT8 SAD is applicable to several machine learning applications."The NCU also supports a set of 8-bit integer SAD (Sum of Absolute Differences) operations. These operations are important for a wide range of video and image processing algorithms, including image classification for machine learning, motion detection, gesture recognition, stereo depth extraction, and computer vision."
Eh, I still don't think they mean deep learning. Probably, they're referring to some classical image processing techniques, or maybe preprocessing prior to feeding a CNN. Ideally, you might ask them for examples of where it's used, or maybe at least paper citations (which are conspicuously absent from that part of their whitepaper). But I know this was an ambitious article, so maybe it's something to keep in mind for your coverage of Vega 20.
> results are all in microseconds that are converted to TFLOPS using the kernel dimensions
Dude, that's messed up. At the very least, it shouldn't be TFLOPS unless you're actually using floating-point arithmetic. And if you're using a framework that optimizes your model (such as TensorRT, I think), I wouldn't report end performance as if it were actually using the unoptimized kernel.
> Tuning guides for AMD architectures are not yet filled out on their ROCm documentation, and I couldn’t find out if packed INT8 xSAD is well-integrated as some DL primitive in MIOpen.
Well, "Open" means open source, in this case. One could try and have a look. That said, it's a huge article and nobody could've reasonably expected you to do more. It'd be more digestible if broken into a couple installments, actually.
Anyway, the rough state of MIOpen is actually one of the main reasons we don't currently use AMD. I hope the situation changes by the time Vega 20 launches.
Anyhow, thanks for the comprehensive reply, not to mention the article. There are still a few parts I need to go back & read!