Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTPerformance Targets: What Are The Numbers?
Naturally all this talk about performance and efficiency needs to substantiated with some concrete numbers. In the context of today’s announcement, most performance figures disclosed by Arm were relative improvements compared to the A72 Cosmos platform, which might not be the most relevant data-point in terms of trying to actually place the N1 in the competitive landscape, however we also have some more concrete absolute figures we’ll try to put some more context behind shortly.

The comparison to the A72 at the same frequency as well as a similarly configured system with SLC configuration, the new N1 outright smashes its predecessor platform / microarchitecture. The figures here represent single-threaded performance in SPEC. In integer workloads we see PPC (performance per clock) and absolute performance gains from 60 to 70%. The floating point benchmarks are even more impressive with gains ranging from 100 to 120%. The data-points represent modelled and emulated performance estimates, the actual real-life performance improvements will higher due other SoC-level improvements as well as software improvements that aren’t available in existing actual A72 silicon products.

Arm again iterates the very large compute performance improvement compared to existing solutions, achieving beyond 2x performance boosts in vector workloads. Naturally, the N1’s ARMv8.2 ISA implementation also means that it supports 8-bit dot product as well as FP16 half-precision instructions which are particularly well fitted for machine-learning workloads, achieving performance boosts near 5x the predecessor platform.
Overall, Arm’s comparison to the A72 makes sense in the context that this is to its predecessor, however we have to keep in mind that the Cortex A72 was a core that was first introduced back in 2015 with first silicon products being released late that year as well as 2016, while the new Neoverse N1 in all likelihood isn’t something which we’ll be seeing in products for another 12-18 months, resulting in a ~3-4 year time span between the two products.
Arm did also divulge absolute SPEC numbers, and here we can have some more interesting analysis to competing platforms:

For a Neoverse N1 64-core hyperscale reference design running at about 2.6GHz, Arm proclaims single-threaded SPECint2006 Speed score of ~37 while reaching an estimated multi-threaded scores of 1310. The figures here are achieved in a quite low whole-server TDP of only 105W. The figures weren’t run actual silicon but rather estimated on Arm’s server farm in an emulation environment with RTL.
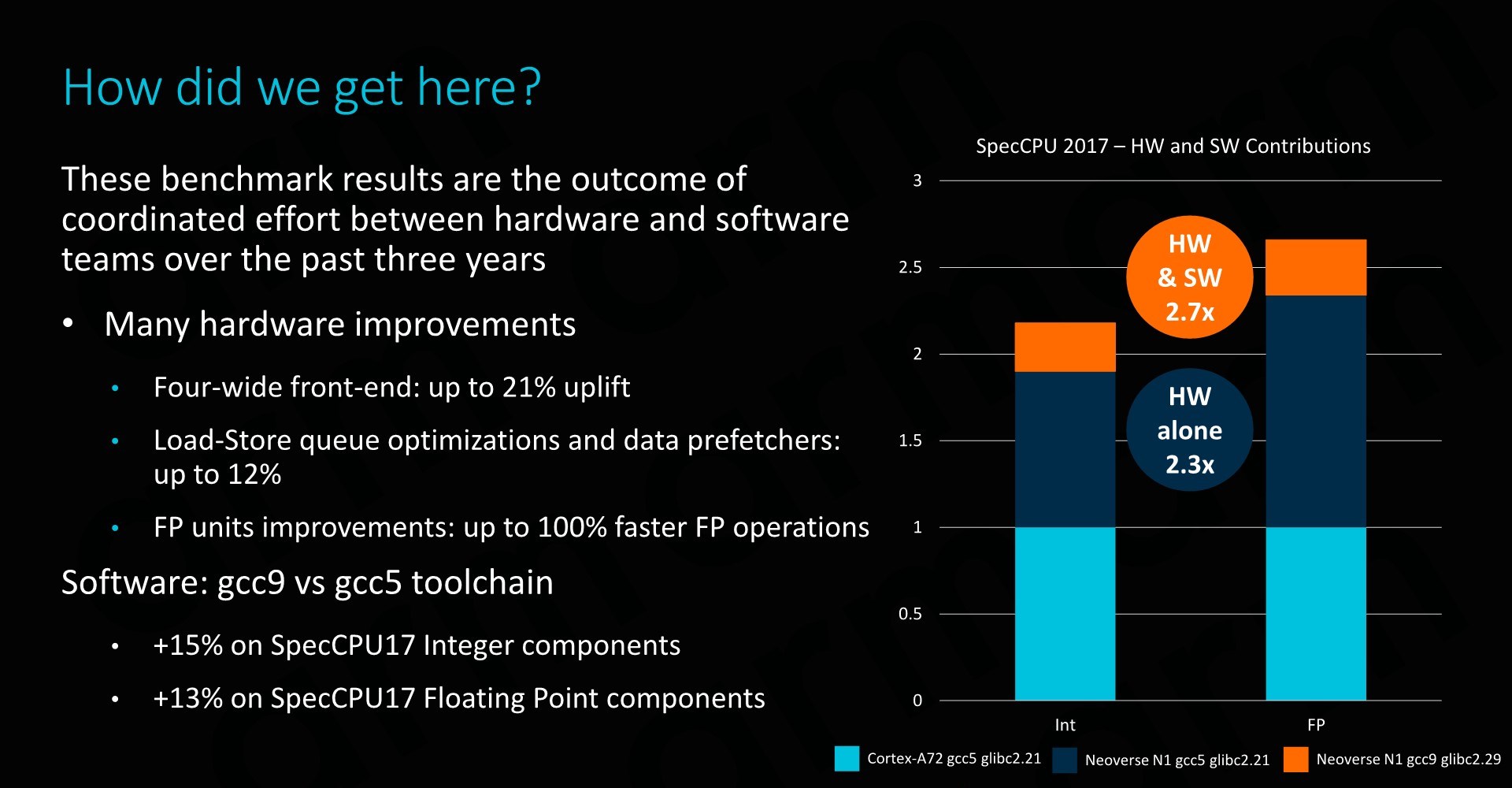
Arm made a big note that among the many efforts to improve performance for the Arm ecosystem isn’t only offering better hardware, but also better software. Over the last few years Arm has put a lot of effort into improving open-source tools and compilers, such as GCC. Comparing the latest GCC9 version to GCC5, we’re seeing improvements of 15-13% in integer and floating-point workloads. It’s to be noted that the optimisations made here are real-world use-case improvements, and not targeted changes that are meant to improve SPEC scores.
In order to put context around Arm’s numbers, I went ahead and compiled a set of binaries with GCC8 and had Ian run it on Intel’s and AMD’s latest and greatest, an Xeon W-3172X as well as a AMD Epyc 7601. It’s to be noted that the compiler flags weren’t exactly the same – both AnandTech’s and Arm’s builds were running under –Ofast, however Arm also added some minor flags which I hadn’t had the chance and time to cross-check, as well as enabling LTO. I’m not too concerned about the flag variations, however LTO will give Arm a 2-3% performance advantage over our internal numbers. It’s also to be noted that Arm’s single-threaded figures are marked as “Peak” scores, meaning each individual workload was run with the best performing compiler flags, while our internal figures are “Base” scores, meaning we’re running the same flags across all binaries and tests.
Edit: 25/02/2019: Arm have reached out to clarify that the performance scores were in fact Base runs and without LTO - the slides in question were mixing things up. Thus we have proper apples-to-apples comparisons in our numbers versus Arm's internal numbers.
As always we have to disclose that the below figures are merely internal estimates as they’re not official SPEC submissions. SPEC CPU 2006 has also been deprecated in favour of SPEC CPU 2017. Arm stated that they’ve shared SPEC CPU 2006 figures as that’s still the industry standard at the moment which gives users and customers the best context, and in the coming year or so they’ll switch over to also sharing SPEC CPU 2017 numbers. As for us at AnandTech, I’ve prepared SPEC CPU 2017 and Ian and I will be adopting it in our benchmark suites for PC/server CPUs as well as mobile SoCs in the coming weeks and months.
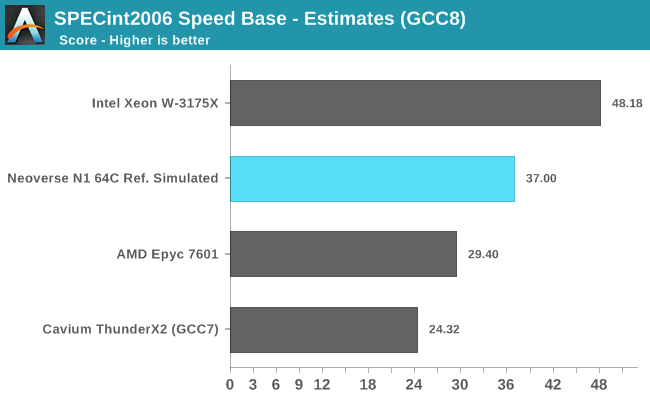
In terms of single-threaded performance, the N1 looks to be outright outstanding. With an estimated score of 37, it would beat the most recent and best-performing Arm server CPU, Cavium’s ThunderX2, by a significant margin. It’s to be noted that the real-world performance difference would be smaller than depicted in the above figures: GCC8 notably improved loop vectorisation in 456.hmmer which will give it a 1-2% overall score boost, and of course we have to take into account 2-3% difference due to Arm’s different compiler flags.
Intel’s W-3175X is hardly the most representative hyperscaler CPU, however it gives context as to what Intel’s top-end single-threaded performance in their best multi-core CPUs is. As a reminder, the W-3175X has a single-threaded boost clock of 4.5GHz, significantly above what we see in server SKUs such as the Xeon 8180. AMD’s Epyc 7601 is a more representative data-point against what a hyperscale design such as the N1 would compete against, again as a reminder this is a 3.2GHz single-threaded boost clock on the part of AMD’s first generation Zen core.
What surprised me the most about Arm’s quoted ST score of ~37 is that it’s significantly higher than what we measure on the Cortex A76, which scores in at about ~26 on actual hardware. Software and compiler considerations aside, one of the explanations for this huge 42% performance discrepancy could be the N1’s much better memory and cache system. Here the full system bandwidth is 6x higher than on mobile SoCs, and naturally in a single-threaded workload the thread would have full access to the Neoverse’s N1 64MB SLC cache, a whopping 16x bigger than the L3 in current mobile Cortex A76 designs. If the performance difference is indeed explained by the memory subsystem, it just gives to explain just how important it is to the performance scaling of a core.
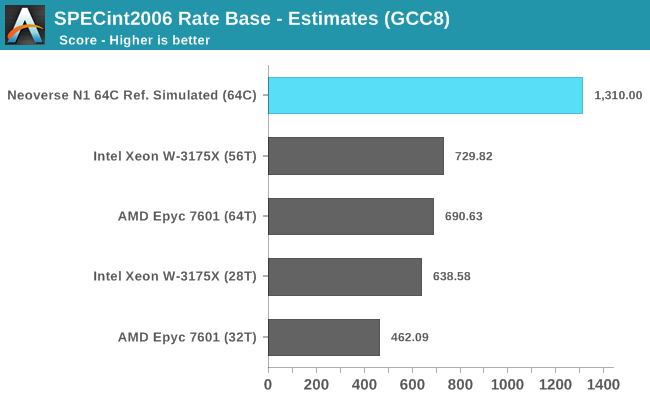
Switching over to multi-threaded workloads represented by SPECrate2006, we have to note that this is a best-case scaling scenario for all platforms as there is no serialisation or inter-thread communication, as the test suite simply runs multiple processes in parallel. Even with this in mind, Arm’s projected results for a N1 64 core design are just outright impressive considering the fact that we’re talking about TDPs much smaller than any of AMD and Intel’s solutions, creating a performance and efficiency gap that I have a hard time seeing the x86 solutions being able to compete against.
We have to remember that we’re comparing a 64 core platform against AMD and Intel’s current 32/28 core platforms. A more fair comparison would be AMD’s upcoming Rome with 64 CPU cores, here even if AMD manages to outright double multi-threaded performance and match Arm’s projected MT numbers, I don’t see them be able to at the same time lower the TDP to match Arm’s estimated 105W target (The Epyc 7601 has a TDP of 180W, Rome details haven’t been announced yet).
SPEC’s Rate benchmarking scoring scales linearly with the instance count. In this case, if we divide Arm’s 1310 figure by the 64 cores of the system, we get a per-instance score of around ~20.5, which seems much more realistic and in-line with the Cortex A76 results we measure on current mobile devices.
Arm’s performance predictions for the Cortex A76 were quite spot on to what we measured on actual devices. We thus are more inclined to give Arm credence and the benefit of the doubt in regards to today’s projected Neoverse N1 scores. The figures do make sense, and are in line with what we saw the microarchitecture able to achieve in mobile.
Naturally we shouldn’t come to any conclusion until we actually have the actual hardware in our hands, but the presented figures are certainly promising if they can be realised by vendors implementing Neoverse N1 systems.








101 Comments
View All Comments
lightningz71 - Thursday, February 21, 2019 - link
This is one I can answer. My computer engineering professors fielded this exact question. Essentially, when profiling code that was being used in modern software, the major CPU vendors realized that a small portion of the x86 instructions were rarely used. So rarely, in fact, that it was an absolute waste of silicone to try to implement them in hardware as it would be so rarely used. Add in that a lot of those instruction are not executed in isolation, but have some sort of dependency on fetching a piece of data, or waiting on the resolution of multiple intermediary steps during their execution, that going with full hardware implementations would not have resulted in a major boost in their performance. Instead, they elected to implement them in micro-code and execute them on the highly tuned circuits that they used to implement the more common instructions in the back end. So, while you loose some performance having to load and run the microcode sequences, its actually executing those simplified sub-instructions very rapidly, and can do other things while waiting for various tasks to complete.so, while there is a case to be made that a full, tuned and optimized hardware implementation of the more complex instructions can be done, and perform more quickly than the micro-code sequences, the actual speedup for the overall performance of the systems in question would be minimal because of how rarely those actual instructions are used in practice. You're talking about shaving off a few tens of cycles per instance on a processor that is running at around 4Ghz these days. The real performance impact would be minimal, but the development cost and circuit budget consumed would be significant for not much gain.
FunBunny2 - Thursday, February 21, 2019 - link
"Essentially, when profiling code that was being used in modern software, the major CPU vendors realized that a small portion of the x86 instructions were rarely used. "not to do too much what-about-ism, but IBM was doing that with COBOL applications, in real time monitoring (allowance to do so was embedded in the lease agreement), at least as early as the 360.
naturally, I didn't remember that lower brain stem memory until reading your comment. my shame. (:
but... I do wonder about all those 'extensions' to the original 8086 instruction set. weren't they created to support 'necessary' functions? here: https://en.wikichip.org/wiki/x86/extensions
or are they, too, not used enough?
Wilco1 - Thursday, February 21, 2019 - link
Well when did you last use MMX? Or x87 floating point? There are large numbers of instructions which are hardly ever used.FunBunny2 - Thursday, February 21, 2019 - link
HLL coders don't, at least directly. but I'm old enough to remember when adding a '87 (before FP was moved to the '86) put a rocket under 1-2-3.Wilco1 - Thursday, February 21, 2019 - link
The point is both have been superceded by all the SSE variants which itself is now being replaced by AVX. Intel has posted patches to change HLL MMX intrinsics to use SSE instructions instead of MMX.zmatt - Wednesday, February 27, 2019 - link
Usually you don't invoke those yourself. The compiler does.nevcairiel - Wednesday, February 20, 2019 - link
The desktop and notebook market will face adoption problems simply from having your software run (fast). Of course they can use emulation layers, but that once again costs you efficiency/performance.Mobile was an entirely new space, so no pre-existing software to really worry about, and servers are a far more managed space so that software is often more readily available in the variants you need. Desktop usages on the other hand are full of legacy software that has to work.
ZolaIII - Wednesday, February 20, 2019 - link
In it's core (integer base instruction set) it is more efficient but that doesn't mean much nowadays. Main factor is design of actual core as such.ballsystemlord - Wednesday, February 20, 2019 - link
But, and here's the kicker, the binary nature of proprietary SW means that switching arches will require many fixes to programs and many more will never be ported. Emulation, which is slow for CPU arches, is the only way that such SW could continue to exist.Gee, Stallman was wright!
wumpus - Thursday, February 21, 2019 - link
Put it this way: the effective means to convert a "CISC" architecture to internally* "RISCY" operation could be included on a CPU core effectively in the mid 1990s. This pipeline step is sufficiently small to make no difference nowadays (although Sandy Bridge and later use caches to store pre-decoded micro-ops). The RISC/CISC wars died a long time ago, and now we only have Intel vs. ARM vs. AMD (and don't forget IBM).* (Internally RISC). Oddly enough, the more "internally RISCy" a 1990s-era chip was the less successful it was. The AMD K5 was internally a 29k derivative (a real RISC) and failed miserably. Supposedly IBM had a PowerPC/X86 hybrid that never made it out of the lab. Transmeta did its translation in software, but fell into the "single device power trap". Nextgen was probably more successful than all of these (especially in convincing AMD to buy them and producing the mighty Athlon), and had the ability to execute native code (supposedly. I don't think anyone ever did. Presumably involved 80 bit instructions). Pentium Pro, K6, Pentiums 2&3, Athlon all executed "native microcodes" but don't appear to slavishly copy RISC dogma.