Talking TDP, Turbo and Overclocking: An Interview with Intel Fellow Guy Therien
by Dr. Ian Cutress on July 25, 2019 9:00 AM EST
One of the most misunderstood basic technical points over the past decade is related to power consumption and how different CPUs react differently to load. The basic premise is that when there is extra power budget available, individual cores can raise their frequency and voltage to maximize performance on short time scales, scaling back when more cores are needed. The confusion comes from how this works, intertwined with how TDP relates to power consumption. After some interesting personal discussions at Computex, Intel Fellow Guy Therien, the Chief Architect of Intel’s Client Performance Segmentation agreed to go on the record about how Intel has defined and adapted its explanation of TDP and Turbo, as well as speak to Intel’s new Performance Maximizer overclocking tool. We also cover Intel’s approach to the enthusiast market.
To put this into perspective: I have a lot of conversations at Computex that are off the record, away from a respective company’s presentation area. These could be casual chats with my direct PR contacts, about upcoming details or feedback on press activities, or they could be deeper behind-the-scenes conversations with engineers. This is the normal way of things – most of what we end up doing at a trade show never makes it to publication, but aids us in delivering future content by understanding scheduling, process, and concept, even if we can’t report on direct events. It has always been my goal to go behind the black box of how these companies work to understand the inner dealings and workings, if only to understand how decisions are made and what directions can be pointed to next.
Several of those chats this year at Computex happened with Intel, mostly around its demonstrations about its new 10nm Ice Lake '10th Gen Core' processors, as well as the Core i9-9900KS and Intel’s new automatic overclocking Performance Maximizer tool. Now back in November, when I published a deep dive into why Intel’s TDP and turbo values can be somewhat misleading to the majority of users, Intel Fellow Guy Therien reached out to me at the time to help clarify a few things. We had a few disagreements about the interpretation of the values, and this discussion came about again based on Intel’s Computex announcements. Guy and I had some deep interesting discussions, some of which were purely from a philosophical standpoint of user experience.
Based on those discussions, Intel invited me to talk to Guy on the record about a number of those points to assist in clarification. For the record, I like talking to Guy – like any good engineer, he is blunt and to the point, and is happy to have a heated debate about individual topics. That doesn’t mean I went easy on him.
 |
 |
| Dr. Ian Cutress Senior Editor, AnandTech |
Guy Therien Corporate Fellow, Intel |
Guy Therien is one of those long time Intel ‘lifer’ engineers that seem to stick around for decades. He’s been at the company since February 1993, moving up through the various platform engineering roles until he was made a corporate fellow in January 2018. He holds 25 US patents, almost exclusively in the fields of processor performance states, power management, thermal management, thread migration, and power budget allocation. Guy has been with Intel as it has adapted its use of TDP on processors, and one of his most recent projects has been identifying how TDP and turbo should be implemented and interpreted by the OEMs and the motherboard partners. Because we are now in a situation where casual users are seeing power consumption breach that TDP number on the box, even at long time scales, it is now more than the OEMs that need to understand how Intel is defining its specifications. Guy currently holds the position of Corporate Fellow and Chief Architect for Perfromance Segmentation in the Client Computing Group at Intel, contributing to Intel's Technical Leadership Pipeline.

Community
Ian Cutress: When we spoke at Computex, one of the topics we touched on was about Intel’s relationship with the enthusiast community and how it has evolved over the last 10 to 15 years. We’ve gone through the good-old days of high-performance, and pushing overclocks, to now where we’ve had several generations of similar products. Now we’re back into a full on x86 war between Intel and AMD. From your perspective, as a Chief Architect within Intel, how does Intel approach the community with relation to its product stack these days?
Guy Therien: So you know historically an interesting thing has happened - we had lots of products across our entire SKU line and they were used for different purposes by different people. But then we found there was a certain subset of those people, what we now call the overclockers and the enthusiasts, who wanted to get more out of the products. As you know, part of being a large corporation is that when making millions and millions of products there are certain requirements that we have to enforce to ensure that our folks who aren’t enthusiasts (i.e., the majority of Intel's customer base) get what they expect out of our products in terms of performance and reliability, wear life and things like that.
So as a result of those requirements for our product quality, we put some controls and limits on the performance of parts even though they may actually be possible to momentarily achieve higher performance. Enthusiasts of today are willing to take risks, and maybe don’t consider wear performance that is targeted for the general population, and so they started, you know, doing overclocking and modifying the operation of the processor outside of Intel’s standard control set, using controls that are outside of the operation of the processor itself, things like BCLK and upping memory speeds and clock speeds. For a long time, we thought "hey that's going to be bad" and wear the CPU out and you know there was some internal concerns with regards to the people doing this. I would say back in the old days there was a general relief the folks who were doing this were somehow not wearing the CPUs out. But over time an interesting transition happened where we realized that there was a large portion of folks that really wanted to do this. All the things kind of add together over time to create these products.
So the idea actually morphed from trying to keep folks from changing their external clocks to drive those controls internal to the processor to make them more uniform in a number of ways. Now of course as you know we have internal controls and an overclocking ability and so if you’re willing to accept the risks of modifying the default beyond the standard ratios that come with the K SKU processors, you can unlock the multiplier and you can set the ratios programmatically, and actually program the ratios to increase their performance. Of course there is sometimes a downside to that which means it won't last as long.
So if you maybe think about the enthusiast community today, how our view has evolved: it went from looking us looking at them as maybe a challenge to our product quality, to actually being an asset. You know we make a lot of products, and we really want to keep the maximum capability of the products shining through and then by opening up and embracing these controls in a public way, we were able to provide additional performance to the folks who really need it or want it.

Ian Cutress: So we've had Intel do lots of promotional materials in the past few years with regards to enthusiasts. What would you say is the state of the relationship with enthusiasts today inside Intel? How does Intel view enthusiasts today? How strong is the drive to pushing performance hardware into the hands of these enthusiasts?
Guy Therien: Well certainly the enthusiast crowd is a significant focus that we go after – you’ve heard about our creator PC effort, and our entire K SKU line is orientated towards both those folks that are enthusiasts that are consumers but also what you might call the professional enthusiasts that really need to eke out every bit of performance in their business. So today now we are fully behind the enthusiast side with overclocking products and continuously pushing additional overclocking knobs into our products. This is as well as maximizing the performance you have seen in the 9900K, and the 9900KS, what we call ‘thin-bin’ stuff, in fact in some cases you know there are specialized or lower volume parts sold through an auction process, for people to eke more performance out of the highest core count processors. So it's a very strong and direct recognition of the focus being made and trying to make products that cater to enthusiast needs by understanding them and coming up with thin-bin products to support them.
Ian Cutress: So would you say that Intel approaches enthusiasts and overclockers as different groups?
Guy Therien: There are those we call overclockers who are folks that are going to be executing and working outside the spec(ification). We embrace out-of-spec [operation] if you accept it the inherent risks. Enthusiasts by contrast are folks that need performance and we try to maximize ‘in-spec’ performance for enthusiasts. Certainly there is a strong crossover and there are enthusiasts willing to accept the risks of overclocking, so there’s definitely a blend between the two of them. But we are also focused on ‘in-spec’ operations as well as the ability to go out-of-spec. Personally I try to maximize the performance ‘in-spec’, like the i9-9900KS, like the W-3175X, but you can go out-of-spec and get even more.

Intel Performance Maximizer
Ian Cutress: One of the things we discussed at Computex was regarding Intel's new Performance Maximizer tool, and the ability to drive out of spec performance. This new tool reboots the PC into a custom UEFI mode, tests the processor, and provides an overclock. Intel wants to make it available to people who may not necessarily be ok with how these overclocking tools work. I know you have been doing a lot of work in respect to this tool - can you talk me through the thinking internally how Intel has moved from the ‘staying in spec’ attitude, to then designing the previous tool Intel XTU, to now having the Intel Performance Maximizer (IPM) tool and the groups of people that is targeted to?
Guy Therien: So to give a bit of background to this. My history is in software, and then I segued into power management and ultimately processor-OS interactions to control processor features so I was one of the folks responsible for Speed Step, and hardware P-states was my project too. Then over time while looking at enhancing turbo, I started investigating what additionally we could do. That's when I started looking at how not all cores in the package are created equal, and I started looking at how some cores have the same voltage but yield a higher frequency at that voltage. This ultimately led down a path to Turbo Boost Max, but along the way I had to learn a lot about manufacturing and about reliability. That ultimately led one day to discussions with companies that are overclocking business systems – they buy processors from us and they test them and absorb the warranty themselves and sell their systems to financial services customers and support them.
So through all that effort, we also came across an interesting problem that was happening on the server side. When we sell our parts, in respect to our internal tools, we do modelling to detemine how long they expected to last. There is a mathematical wear out expression that is our spec. That spec is based upon projected wear of the CPU, and how long we think typical parts or worst case (or most used) parts will spend in turbo. Our internal datasheets specify the percentage of the parts are projected to last a certain amount of time with what workload. So our users understand that, they'll buy our parts (we’re talking the really high-end server folks), and they’ll say that they understand that there is a limit on how long they will last when used under the conditions Intel have specified – but that they won’t be using it under those conditions. They ask us that if they put it in turbo and leave it in turbo, 24 hours a day, 7 days a week, how long will it last? They look at us, they understand what we sell and at what price, but they ask us how long our products last under their specific conditions. When this first started happening, we said we didn’t know, but we would try and figure it out.
So an effort went underway to try to measure the wear of these systems. Just to be clear, all systems slowly wear out and become slower / need a higher voltage for the same frequency over time. What we do, as what everyone in the industry does, is add some voltage, a wear-out margin, to ensure that the part continues to operate in spec over a specific lifetime of the part. So you can measure how much voltage the parts need as they wear out over time, and hopefully figure out when parts are wearing out (if they wear out at all, as some don’t wear out very much at all). They wanted to know if we could assess this offline and give them an indicator of when a part was going to wear out. It turned out that there was a long effort to try to do this. As server availability has to be up like 99.999% of the time, ultimately the project was unsuccessful. We had false positives and false negatives and we couldn’t tell them exactly when each specific part was going to wear out, and when we did tell them it wasn’t going to wear out, it eventually did. So it’s a very difficult task, right? So I learned about this effort, and one of the revelations that the team had was in order to improve their accuracy they couldn’t take measures while an OS was running, because of the variability caused by the OS, due to interrupts and other background processes, so they learned to do the measurements in an environment offline outside the OS.
So we took that conclusion, and we looked at a lot of other utilities that said they had auto overclocking features and auto tuning capabilities. A lot of these utilities weren’t very successful, mainly due to the variability of the runtime while inside the OS, and also because they often tilt things to the max, which over time due to wear means the settings are not applicable / don't work any more. These utilities never go back and evaluate the situation again to see if they should back off a little bit, or add a little bit more voltage, or something, in order to keep the system operating. So without real data that said that a lot of folks that buy the top CPU don’t overclock, we suspected that it was indeed true. We assumed that the large portion of these customers who buy our highest end products want the maximum performance but don’t overlock even though they have the ability with the K SKU. So the idea was, from looking at what we can do manually with complicated tools like XTU or the BIOS, where you have to adjust many parameters to overclock, we saw that the internal capability of most processors was on average greatly above the specification. It’s not like it was one or two bins above the spec, it was often at times four or five bins. So we thought we should provide a way for folks who buy the best to be able to get a little bit more performance out of the part that they bought.
Now because there is some variability in the parts, and among the millions of parts that we create there are some that are much much better than others in terms of their maximum capability. But certainly the majority of them, the lion’s share of them, can achieve at least several bins (1 bin = 100 MHz) above specification without much risk to daily operation.
The result of all this was that we thought about why people who buy the top processors, the K processors, don’t overclock. Because it can be kind of scary, right? With all these settings, such as raising current limits, raising voltages, changing power, and how all these settings interact, and what about memory overclocking and so forth. So we took a more simplistic approach for the user, just focusing on ratio overclocking, providing a way that is easy for the end user to do in a few clicks with our new Intel Performance Maximizer (IPM) tool. If the user accepts the terms [of use], it becomes a very easy experience. So for many of the folks who have bought the best parts, it now becomes pretty easy to get a little bit more performance, up to the tune of 10-15%, which will depend on the quality of the processor, but that’s the path to it.

Ultimately this IPM tool is aimed towards anyone who is buying a K processor, and happy with accepting a small amount of risk when executing out of spec in exchange for more performance out of the product that they have already purchased.
Ian Cutress: What is Intel’s stance towards overclocking on laptops, compared to desktops and workstations? Or are these kinds of devices seen as independently internally, for the types of users that might be interested in maximizing performance of their hardware in the different market segments.
Guy Therien: Regardless of device, if you’re buying the top end SKU that is unlocked, we want to let these folks know that they can get a bit more performance out in an easy and simple way with the IPM tool in desktop processors, as long as they accept the risk.
Ian Cutress: You mentioned other overclocking tools that already exist, and that Intel is unique in that you have the ability to optimize overclocks outside the OS. We do see tools from the likes of Asus, MSI, ASRock and other major Intel partners, who have been building tools over the best part of the last 10 years. What can IPM bring to the table that these guys can’t?
Guy Therien: So, the first is simplicity and ease of use. It’s our belief that a lot of the tools that are out there are overwhelming to the majority of users, and that there’s just a small portion of users who are willing to try to understand and learn all the nuances of the tools.
The second one is the level of reliability that comes with not pushing all the way to the edge and having some margins. IPM selects 100 MHz lower than the peak passing frequency. It’s a tool that allows users to continuously operate without any fear by pushing the overclocking up too high. With IPM, we believe that it is certainly more stable than the other tools – we bring a level of reliability that other tools do not, by adding margins and not pushing it all the way to each processor's limits.
Another feature of IPM is that when the other utilities are used, they are setting a series of parameters like frequency and voltage, and then go stress test it to see if it works. If it hangs, they back off and try it again, then back off and try it again, and who knows what individual choices the user has on the level of the stress test. I mean sure, there has always been some auto tuning in the third party applications, but it always comes down to the stress test – some users say Prime95 is a good stress test, but from our side of the fence we need to cover a wide range of stresses for all the things that might go wrong when increasing the speed beyond spec. So IPM has a special set of tests that it runs that we have internally architected to provide what we feel is a good set of coverage for all of the corner cases across the entire system that might be impacted by high frequency, such as both critical and non-critical compute paths. So with our intense testing, plus the additional margin we provide, you know that the system should be at a very high performance with a good amount of stability. Because we know the processor like we do, no-one else can match how we test.
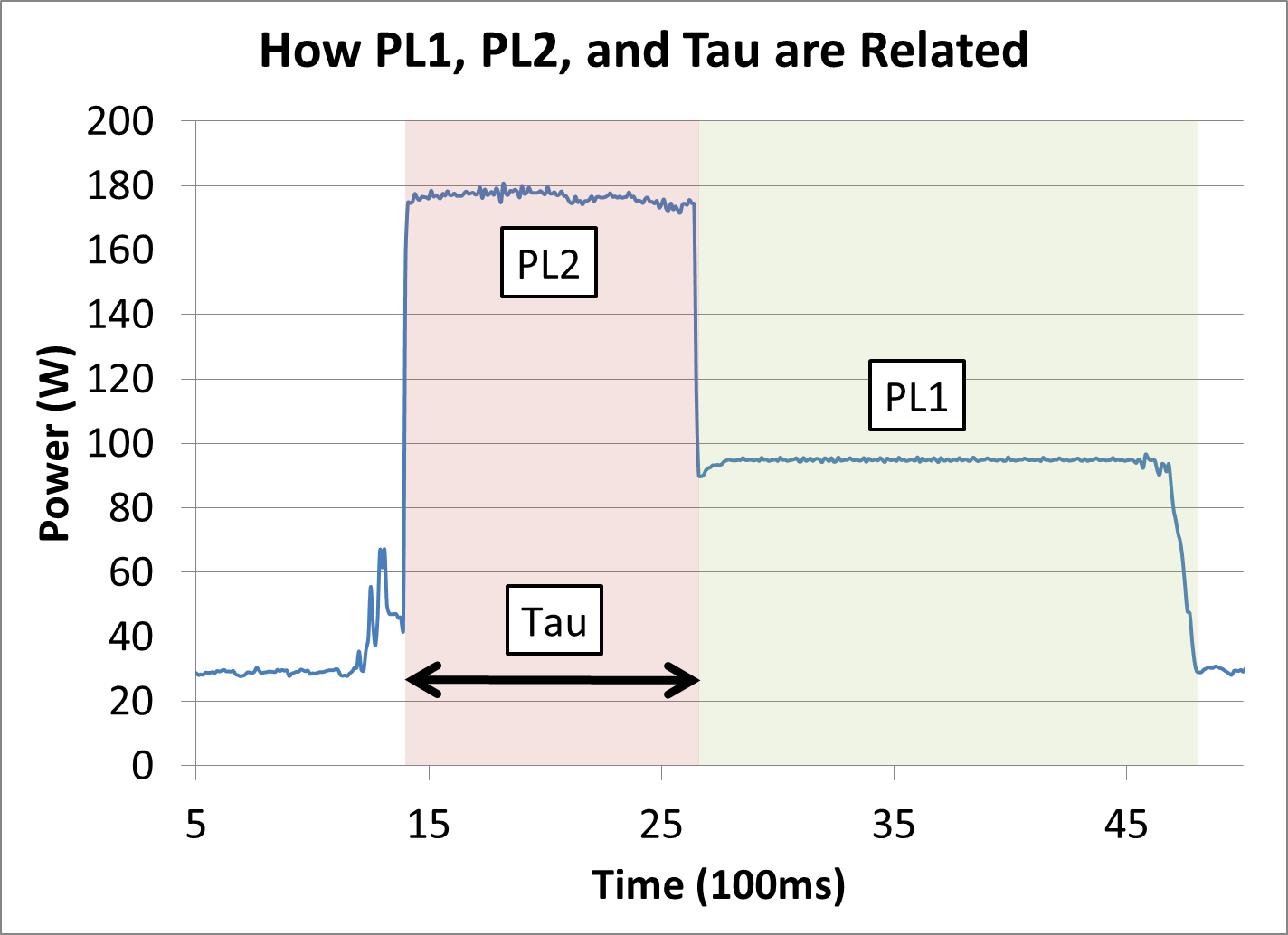
TDP and Turbo: What They Mean and How We Should Test
Ian Cutress: IPM is directed at people that wish to overclock, or to get the maximum out of their processor. But most enthusiasts just want to use an off the shelf processor and still have the best performance – in this mind they rely on specifications such as Intel’s TDP ratings and the turbo frequencies. Can you explain Intel’s relationship with how it defines TDP and Turbo, and the reasons why behind those definitions?
Guy Therien: I was responsible a few years ago for refining the language to make sure we had descriptive terms across the corporation for what TDP is and what Turbo is. This was based upon a number of folks getting together and talking about how we tested our parts and what we were actually enforcing in terms of TDP.
TDP is an average power dissipation at a maximum junction temperature operating condition limit, specified in Intel’s engineering datasheet for that processor, for which the processor is validated during manufacturing and when executing an associated Intel-specified high complexity workload at that frequency. What that means is when we quote a base frequency, we think about a worst case environment and a real world high-complexity workload that a user would put on the platform – when the part is run at a certain temperature, we promise that every part you will get will achieve that base frequency within the TDP power. So that’s what it is – it allows our customers, our ODM customers, and the manufacturers, to know how much thermal capability and power delivery capability to implement in their systems so that they will get the base frequency, which we may have historically called our ‘marked’ frequency.
For that reference workload – we also have to deal with the complexity of that workload. If you take two workloads, such as a simple 100% 'no work but keeping everything powered' spin loop that causes turbo, and a 100% complex workload, the difference in power consumption between the two might be many 10s of watts. If we define a power virus as something that causes every transistor and every gate to toggle on every clock, the n consider the absolute worst case power virus - our TDP workload isn’t that. We define TDP with a workload that is a percentage of that worst case scenario (a high percentage, but not 100%), because you rarely get close to the absolute worst case power virus under real world conditions (even with video rendering). This percentage might change based on the processor generation, based on each processor capabilities, how likely various parts of the processor are likely to be used as workloads evolve. We can adjust our workload to match anywhere from that basic spin loop to the power virus and all between, or even two sets of workloads simultaneously. We’ve got to do all this analysis to try and figure out what we think in any given generation is a typical worst-case workload, especially with all the software applications out there. For example, a game streamer might be running 87% of our expected workload or something like that, so they can take advantage of lower power consumption at base frequency or get frequency above the base into the turbo range – maybe even the maximum turbo frequency for a long period of time.
There’s also the natural variability of the manufacturing of the parts. Some silicon is luckier than other silicon. Remember that when we specify TDP, it’s for all the parts you will ever buy. So if you are an OEM, and you are buying a million CPUs, we specify that every part you buy, not one of them will exceed our ratings. But due to the variability in manufacturing, often at times the parts that you get are nowhere close to that worst case scenario. Sometimes we make the parts to a specific bin, and sometimes we down-bin the parts, for reasons such as demand or requests. This is why there are third-party companies that come in, buy a bunch of parts, test them, work out which ones work the best, and resell the fastest parts. For them, it’s just taking advantage of the natural manufacturing variation.
Ian Cutress: So what I’m hearing is that when Intel releases a new part, I would need 10+ samples so can check the variability myself?
Guy Therien: When it comes to press samples, I’m not in charge of that! (laughs) But what we can say at Intel is that over time as we create more processors, we understand and improve the manufacturing process. We can look at the leakage of a processor and see where it is in the projected range of all the millions of parts we have manufactured. Our data is usually really tight, even if initially there might be some predictions as a part becomes more mature. With some early parts, particularly things like engineering samples which aren’t sold to end-users anyway, we’re still tweaking the process and getting it ready. But when we’re ready to provide CPUs to press for review, they’re the same as retail CPUs, because we don’t want to be misrepresenting the market.
Ian Cutress: One of the things we have talked about in the past is relating how TDP and turbo work and how turbo budgets work. My argument is that it is not necessarily clear to the general populous how Intel correlates these values to the masses. I was wondering if you are willing to give us a quick overview.
Guy Therien: Sure. So the general concept is that we have frequency limits – whenever a core is active, such that every CPU has a single or dual core turbo frequency that we publish. Beyond that, depending on the number of cores are active, we have a maximum limit on the frequency. But for that system limit, that’s a frequency limit, and what we really end up doing is enforcing TDP. TDP is an average power that is forced over time. This is important – it’s not just a singular value. As a result, what turbo is really doing is controlling power rather than frequency.
Within a processor we define a burst power limit, that we call Power Limit 2 (PL2), compared to the TDP, which is Power Limit 1 (PL1). There is an algorithm that is run in the processor that ensures that TDP, over a period of time, is enforced as the average power. The algorithm isn’t a simple rolling average, but is an expontential weighted moving average, meaning that the most recent power consumption matters the most – it’s a standard algorithm.
But that means that if you have been idle for a while, you have a specified power budget. A processor can use power, up to its PL2 power limit and its frequency limit, until the budget runs out, and then the processor will move to bring the average power PL1/TDP value. It’s like a bathtub that fills up with water – if you drain it out, you can only drain so much before it has to be refilled.
This PL2 limit, and the power budget, is configurable. In fact, on all client parts, you can configure both the period over which TDP is enforced and the height of the power limit to which you can burst. Do you remember talking about workload complexity? Well it turns out that if you run a simple workload, you might be getting all the possible turbo frequency, but because the workload is light, you don’t actually drain the power budget all that much, and can turbo at that high freuqency for longer. It’s the power budget that is ultimately being enforced. But a more complex workload might burst all the way up, hit PL2, and drain a lot of that budget very quickly, so you are all of a sudden out of budget. In that case internally we will reduce the frequency to maintain the CPU within the longer term power limit (PL1 / TDP) until you can regain budget again as per the algorithm mentioned before.
So if we consider a system at idle, that has a full power budget. As the workload comes onto the cores, the internal weighted time algorithms pump you up to the highest frequency as long as that’s available for the number of cores that are active. Then we’ll look at the power that’s being consumed, and as long as it is less than your power limit PL2, you are good. So we continue on at that frequency. As the exponential weighted moving average algorithm starts calculating, and sees the power that is being dissipated/sustained. Then, after a time, it’s looking at the time over which it needs to enforce that average power, which we call Tau (τ). When Tau is reached, the algorithm kicks in and sees if it needs to reduce the power that’s being consumed, so it can hit can stay within the TDP limit. This means that you get a burst of performance up front. After that performance, that power budget, is exhausted, internally the processor will start to reduce the power by reducing frequency to ensure that the TDP is enforced over the time that it is configured. So Tau is the timeline over which TDP is enforced by the algorithm.
Both PL2 and Tau are configurable by the OEM and ODM, and are ‘in spec’. So you have the ability, of course, if the power delivery supports a higher power limit, and also if the system has the thermal capability (because it makes no sense if you’re just going to thermally throttle), to adjust these values. So motherboard manufacturers and ODMs are investing in their power delivery and thermal solutions to allow them to maximize performance or get a certain about of turbo duration without throttling – to the maximum extent possible. As a result of this you can invest different amounts of money into the power delivery, the thermal solution, the thinness of the system and so on – it’s the ability to design something that is differentiated for the audience, both in terms of form factor and performance.
The thing to remember is that you can design a system that is overkill for a lot of environments - beyond what is usually required in normal use. If a workload is applied to a 65W CPU and a 95W CPU, and they both burst up to the same 200W, and finish before the turbo control algorithm is applied, that’s how OEMs and manufacturers can differentiate in their design. This means that if both CPUs have the same turbo frequency settings, they'll score the same at Cinebench, even with a 30W TDP difference. For mobile systems, it’s about the limited cooling capability of the system that you’re touching, and that the head maybe doesn’t come through and become uncomfortable to touch. For a desktop, maybe the concern is acoustics or the temperature of the exhaust fan air. But a partner can clearly design a system to have a three minute turbo window over which the TDP is enforced. So depending on the system capability, we have the TDP, and then the associated Turbo parameters (PL2 and Tau) can be configured to meet the capability of the system.
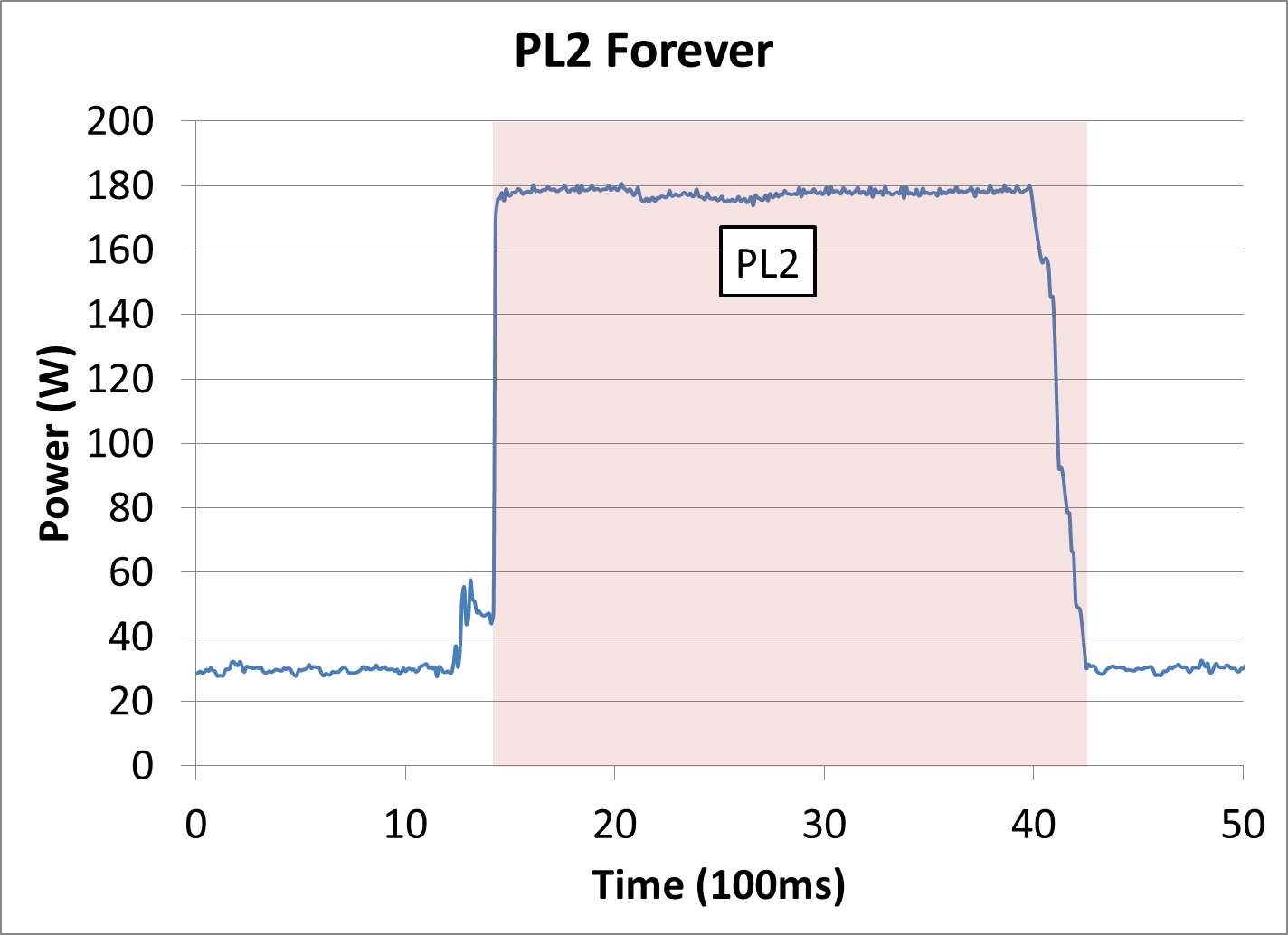
Ian Cutress: One of the things we’ve seen with the parts that we review is that we’re taking consumer or workstation level motherboards from the likes of ASUS, ASRock, and such, and they are implementing their own values for that PL2 limit and also the turbo window – they might be pushing these values up until the maximum they can go, such as a (maximum) limit of 999 W for 4096 seconds. From your opinion, does this distort how we do reviews because it necessarily means that they are running out of Intel defined spec?
Guy Therien: Even with those values, you're not running out of spec, I want to make very clear – you’re running in spec, but you are getting higher turbo duration.
We’re going to be very crisp in our definition of what the difference between in-spec and out-of-spec is. There is an overclocking 'bit'/flag on our processors. Any change that requires you to set that overclocking bit to enable overclocking is considered out-of-spec operation. So if the motherboard manufacturer leaves a processor with its regular turbo values, but states that the power limit is 999W, that does not require a change in the overclocking bit, so it is in-spec.
Ian Cutress: So the question then becomes - how would Intel prefer that we test for reviews?
Guy Therien: Let me just brainstorm with you a little about this. If you’re looking at an i9-9900K, and one of the highest end overclocking end motherboards. That motherboard manufacturer is going to say that they’re differentiating, they could put a bajillion phases on the VRM, they could assume that you’re going to liquid cool the CPU, and so they put their default settings to support the maximum power the board can dissipate – even if it’s a defacto ‘unlimited’ maximum power. They’ll actually start clipping it if the processor ever consumes more than what’s possible. They enable differentiation by adjusting the capabilities of the board and then the settings, but still in-spec, until you flip that overclock bit. Then maybe there will be another set of folks that build not an overclocking board, but a gaming enthusiast board, or a corporate system. These users might still want the top i7 or i9 processor, even if it’s a K processor, because they want the best in-spec performance.
So you have to ask how you are going to review the capability of a processor like the i9-9900K. I would review it in a motherboard from the top, something in the middle, and a budget design, or the cheapest/most cost effective design, to show how it can be configured. Then you can say that in the different designs, it will perform how the motherboard manufacturers have designed the systems.
But then the question also becomes one of benchmarks. Something like TouchXPRT or SYSMark will give you good burst durations, because the workloads on these tests don’t draw much power. But something like Cinebench might be deceptive, because with a good system it can potentially run entirely in the configured turbo burst window. You have to be careful when you’re looking and measuring something like Cinebench. That’s one of the reasons why we’re not in favor of using that as a relevant benchmark.
Ian Cutress: So how does Intel work with its partners on the laptop side with respect to the turbo values and the turbo window values?
Guy Therien: It’s an interesting history which is not all roses. I was involved with the definition and the creation of turbo, and so specifically laptops were where we were trying to eke out all the performance of possible, and we recognized that there was a period of time that we could run above the base frequency with turbo, and deliver burst performance benefits. So we asked ourselves what values should this turbo be set to. When we first looked at the problem many years ago, we took a look at these laptops, and we examined how thick they were, how quick thermals would propagate from where the CPU is to up through the keyboard and palm rest, what was the size of the heat exchanger, and stuff like that. We did a complete analysis of it, because the idea was that we didn’t want to say something like ‘here’s the turbo frequency, it’s really high, you’ll never get it’. That would be silly to say, to give numbers that might only be possible for a tenth of a second – we wanted to give data that was realistic.
We took a step back to look at the big picture, about how we would be deriving the turbo values. There was a long effort looking at a bunch of workloads on a curve of complexity and power, to try and understand what these PL2 and Tau values should be configured to given how long it would take the computer to heat up. These values might go above or below what the ODM might feel is an appropriate temperature for the palm rest, or the fan noise, or the exhaust temperature. So it was tuned to make sure that the period of what you got with turbo was such that you didn’t throttle. The original PL2 and Tau was set for a turbo of something like 28 seconds in mobile.
Initially, unfortunately, we didn’t come back to refocus on this point year after year, to ensure that these values were continuously updated with how modern mobile designs were being approached, which impacted optimal implementations in retrospect. We are now providing year-over-year updates of internal defaults as we continue to deliver more performance generation over generation. Moving forward there will be even more focus on our partners and customers to define what the default settings should be and to ensure that there is no thermal throttling but still being able to take advantage of the turbo.
The Future
Ian Cutress: How do you see Intel evolving, how it reports TDP and Turbo in the future? Do you have any insights into how Intel approaches it from here, about its engagement of turbo, and how it will evolve?
Guy Therien: We will target providing capabilities that we think users can take advantage of. So as we mentioned at the Computex keynote, in the HEDT space with lots of cores, we will be expanding our definitions of Turbo Boost Max to more than just a single core, to more than just two cores, as it becomes appropriate. As you can imagine, as core counts go up, the question then becomes when do you need all those cores, and when do you only need a few and can take advantage of extra headroom.
But it’s a back and forth kind of flow, especially with things like gaming – the lion’s share of consoles are eight cores, so you won’t necessarily see games go beyond eight cores, because there’s not a lot of use for it. Game developers will have to decide where they are going to put their effort. So that said, we have seen what you might call the sweet spot number of cores for gaming, between four and eight, and so moving forward you will see us focus our efforts on optimizing frequency and performance in that area.
I think I’ve mentioned in an Intel blog at one point that however many cores that folks need, with the app demand to both take advantage and provide benefit with that many cores, that we do the analysis all the time with respect to concurrently running software, how it scales with number of cores, and so forth. So for now, four cores is the sweet spot for most consumers, with four-to-eight for gaming. Beyond that requires multiple things running simultaneously, as individual apps don’t tend to scale that high, unless you move into HEDT. So we will continue to look at providing capability like Turbo and Turbo Boost Max for the sweet spot number of cores that we think people can get the most benefit out of, and of course we’ll look at moving this into other CPU segments beyond HEDT over time.
Ian Cutress: One thing that Intel and AMD do differently is that Intel provides specific turbo tables for turbo frequencies on how many cores are active, whereas AMD takes a more power orientated approach whereby and boosts the cores based on how much power budget table left in the system. Given that you understand the merits of both implementations, can you say why Intel’s recommendations are better to what AMD are offering, or give some insight into the different approaches from your perspective?
Guy Therien: So I can only really speak to the operation of Intel’s implementation, but I would like to point out that our turbo tables are more about absolute frequency limits – there is still a power budget element to the equation, and those values are merely just the peak values, but it is still power based.
So you might be wondering why we don’t just let the frequency ‘float’ up, or all-core frequency float up, if the power allows it. This is a discussion about techniques, and I’m not saying which is better, but I’ll give you two reasons why our turbo tables exist the way that they do.
The first one is to do with when you have a large diversity of instruction types, such as AVX, that can all of a sudden be presented on a processor. You have to be able to react very quickly to changes in the processor instruction mix, in other words, changes in the power that a core is consuming in order to ensure continued operation, or you’ll get voltage droop and potentially a failure (depending on how close the voltage is to a failure state, which ties in with power draw if extra margin is added). So we enforce those power states on C-state entry/exit boundary. It’s not a periodic poll to see what’s going on here and perhaps do some changes – every time a core changes its C-state the power and limits change based on the number of active cores, which ensures reliability. There is some inherent conservatism in that, but as you know, quality and consistent running are king. So our turbo tables are typically set quite high, and we make sure that power hungry instructions like AVX react to a different set of rules, with even further rules for bigger AVX instructions beyond the standard ones. But because of the large swing in power between that simple loop and the most complex power virus workload (and/or the TDP workload), there is a conservatism that we apply to ensure quality and operation, and that’s why as the number of cores that are active increases, we stair-step down the frequency limits, which protects the core from failure. Now you might see some of our products that don’t actually stair-step, they actually keep everything at the same frequency – that’s because those are special screened parts where we know that we can sustain the frequency based on the characteristics of the silicon of that part. But when you’re making millions and millions of them, there are a variety of material characteristics that you learn, and we have controls in place to ensure reliable operation for all the parts we sell.
The second reaso is SKU seperation. We have a range of products and we specify each one exactly for long term reliability and continued operation, with predefined operational frequencies as required by some of our largest customers for consistency and predictability, providing maximum frequency settings for customers who needs it.
The third reason this is that we have to make sure our parts last a long time. If the first reason is to make the parts not die because of sudden voltage, the second reason is that we are very diligent about looking at the lifetime of the parts and ensuring that when you buy an Intel part, on average, it lasts a given target lifetime. No-one wants to be the manufacturer that you buy from where as soon as the warranty runs out, the part dies the next day – we want to ensure that we are the ones with long reliable operation. So from that perspective, we have our wear out targets that necessarily impact those values to ensure continued operation. We also have to take into account how different customers use the parts over the lifetime, especially with high-performance always on hardware. So other CPU manufacturers might have different quality goals than we do.
Many thanks to Intel PR and Guy for their time. Many thanks also to Gavin Bonshor for transcription.
Related Reading
- Intel's Interconnected Future: Combining Chiplets, EMIB, and Foveros with Ramune Nagisetty (Q2 2019)
- Intel Architecture Day: Q&A with Raja, Jim, and Murthy (Q4 2018)
- An AnandTech Exclusive: The Jim Keller Interview (Q3 2018)
- An Interview with Lisa Spelman, VP of Intel’s DCG (Q3 2018)
- Interview with Aicha Evans, Intel’s Chief Strategy Officer (Q2 2018)
- Talking Snapdragon: An Interview with Cristano Amon, President of Qualcomm
- An Interview with AMD’s Forrest Norrod: Naples, Rome, Milan, & Genoa
- All Ryzen: Q&A with AMD CEO Dr. Lisa Su
- An Exclusive Interview with Dr. Gary Patton, CTO of GlobalFoundries
- Interview with Rod O’Shea, EMEA Embedded Group Director and Site Manager for Intel UK
- Interview with Jackson Hsu, Product Management Director at GIGABYTE








53 Comments
View All Comments
dwbogardus - Thursday, July 25, 2019 - link
In my experience, my Intel hardware has been Very reliable. 1) Dell 8500 laptop from 2003 works fine, but its hard drive got tired. 2) Compaq Presario desktop from 2008, on which I'm writing this. 3) a cheap destop purchased in about 1998 lasted my son about 15 years, when its chipset lost a few marbles and the sound hardware and the motherboard USB quit. Worked-around with add-in cards. Never had an intel processor die. The only thing threatening my otherwise good old hardware is Microsoft, by torpedoing XP, Vista, and Win 7, and even the earlier versions of Win 10, and the collusion of the apps and browser companies that now require the latest OS, which can never be loaded onto my otherwise adequate and reliable hardware.phoenix_rizzen - Sunday, July 28, 2019 - link
We're still running a couple dual-P3 systems at work (fax server with ISA fax card and PCI modem). And several of the original Opteron CPUs.We also have dozens of AMD Sempron, Athlon64, Athlon X2/X3/X4 desktops still in the schools, along with some of the earlier Pentium G-series.
We run systems until the hardware dies (motherboard or cpu), basically. A 10-year life isn't odd at work.
My work laptop even has an i5 2700-something in it. Was going to replace it this year, but swapping in an SSD and more RAM made it tolerable to use again, so well keep it for another year or two. :)
My work desktop is an Athlon X2 (8 GB of RAM and a HDl that's being replaced with a Ryzen 5 2600 (16 GB, NVMe) that's redirected to last at least the next 5 years+.
Spunjji - Friday, July 26, 2019 - link
It would probably be impossible for them to provide a useful figure, as it depends so much on load and the specific silicon. I've had 3 Sandy Bridge CPUs go faulty on me since 2011 - the first went faulty around 3 years from new, the the next two died between 4 and 6 years of age. In all cases, the faults were unusual - the CPU would still POST and the system would load windows, but running applications would stutter, halt, and eventually crash without any obvious cause. The one that died first wasn't overclocked, while the other two were. So it seems like even if they provided such a number, it wouldn't be worth much!Slash3 - Saturday, July 27, 2019 - link
My '11 launch i7-2600K is still crankin' away. It's been in 24/7 operation since day one, with the vast majority of the time spent at 4.8 or 5GHz and 1.4-1.45v on an air cooler. Gonna be sad to see it go.Alexvrb - Thursday, July 25, 2019 - link
" So motherboard manufacturers and ODMs are investing in their power delivery and thermal solutions to allow them to maximize performance or get a certain about of turbo duration without throttling – to the maximum extent possible."Translation: TDP is and will continue to be a worthless number for Intel chips, as stock board settings will violate the piss out of it while somehow remaining "in-spec". Tell Intel Guy Fellow Therien he needs to cough up a separate "Turbo TDP" and make the CPU respect it regardless of what the motherboard demands, EXCEPT when *actually* overclocking (running non-stock settings, even if that just means throwing a switch in the BIOS). Otherwise his suggestion of testing with THREE motherboards with different configs sounds like something I'm sure you'll enjoy implementing from now on!
I mean seriously AMD is mauling the hell out of Intel when it comes to real-world power, and I feel like it has barely received a passing mention in most of the tech press. Meanwhile for years many outlets harped on and on about AMD's high power consumption and poor efficiency when the shoe was on the other foot.
Ian Cutress - Thursday, July 25, 2019 - link
TDP/PL1 is the same regardless, the manufacturers manipulate PL2 and Tau based on their design. Your Turbo TDP is likely already covered by PL2. The issue is that OEMs never ever list what they set PL2 to be.Alexvrb - Sunday, July 28, 2019 - link
The issue is that BY DEFAULT the CPU should be in control and have some modicum of respect for the TDP. You should need to throw a switch to enable board-dictated limits. There's no reason an end user should have to guess at what the results will be when they drop a "95W" CPU into X or Y board. If Intel wants to sell 125, 150W chips, let them label them as such.AMD has a noticeable advantage in power efficiency, and I feel like this is going to be glossed over continuously by the mainstream press (unlike the 'dozer days) - at least until Intel gets its new process ironed out. Then I predict it will suddenly become an issue that needs a spotlight.
Spunjji - Friday, July 26, 2019 - link
Agreed entirely here. Saying "it's in spec" isn't much use when we don't know how the spec is being implemented for any given CPU.Laptops are definitely the worst for this, though. It seems like between Intel's TDP, their boost specs and the manufacturer's interpretations of those specs, we've ended up in a situation where you *have* to read a review of a device just to have some idea how it will perform.
CityBlue - Friday, July 26, 2019 - link
@DrIanCutress: Embarrassing that you have an article like this and succeed in ignoring completely the performance losses due to Intel vulnerabilities. Are you desperately trying to ignore this serious issue to avoid upsetting Intel? Your lack of independence and timidity entirely undermines your credibility with readers. This place used to be a go-to site for technical information, now it's just a sham.AV_Stables - Friday, July 26, 2019 - link
aye its been brought up and avoided many times /