Ampere Roadmap Update: Switching to In-House CPU Designs, 128+ 5nm Cores in 2022
by Andrei Frumusanu on May 19, 2021 11:00 AM EST
Today we’re covering some news of the more unusual type, and that is a roadmap update from Ampere, and having a closer look what the company is planning in terms of architectural and microarchitectural choices of their upcoming next-generation server CPUs in 2022 and onwards.
For people not familiar with Ampere, the company was founded back in 2017 by former Intel president Renée James, notably built upon a group of former Intel engineers who had left along with her to the new adventure. Initially, the company had relied on IP and design talent from former AppliedMicro’s X-Gene CPUs and still supporting legacy products such as the eMAG line-up.
With Arm having starting a more emphasised focus on designing and releasing datacentre and enterprise CPU IP line-ups in the form of the new Neoverse core offerings a few years back, over the last year or so we had finally seen the fruits of these efforts in the form of the release of several implementations of the first generation Neoverse N1 server CPU cores products, such as Amazon’s Graviton2, and more importantly, Ampere’s “Altra Quicksilver” 80-core server CPU.

The Altra Q line-up, for which we reviewed the flagship Q80-33 SKU last winter, was inarguably one of the most impressive Arm server CPU executions in past years, with the chip being able to keep up or beat the best AMD and Intel had to offer, even extending that positioning against the latest generation Xeon and EPYC generation.

Ampere’s next generation "Mystique" Altra Max is the next product on the roadmap, and is targeted to be sampling in the next few months and released later this year. The design relies on the same first generation Arm Neoverse N1 cores, at the same maximum 250W TDP as a drop-in replacement on the same platform, however with an optimised implementation that now allows for up to 128 CPU cores – 60% more cores than the first iteration of Altra we have today, and double the amount of cores of competitor systems from AMD or Amazon’s Graviton2.
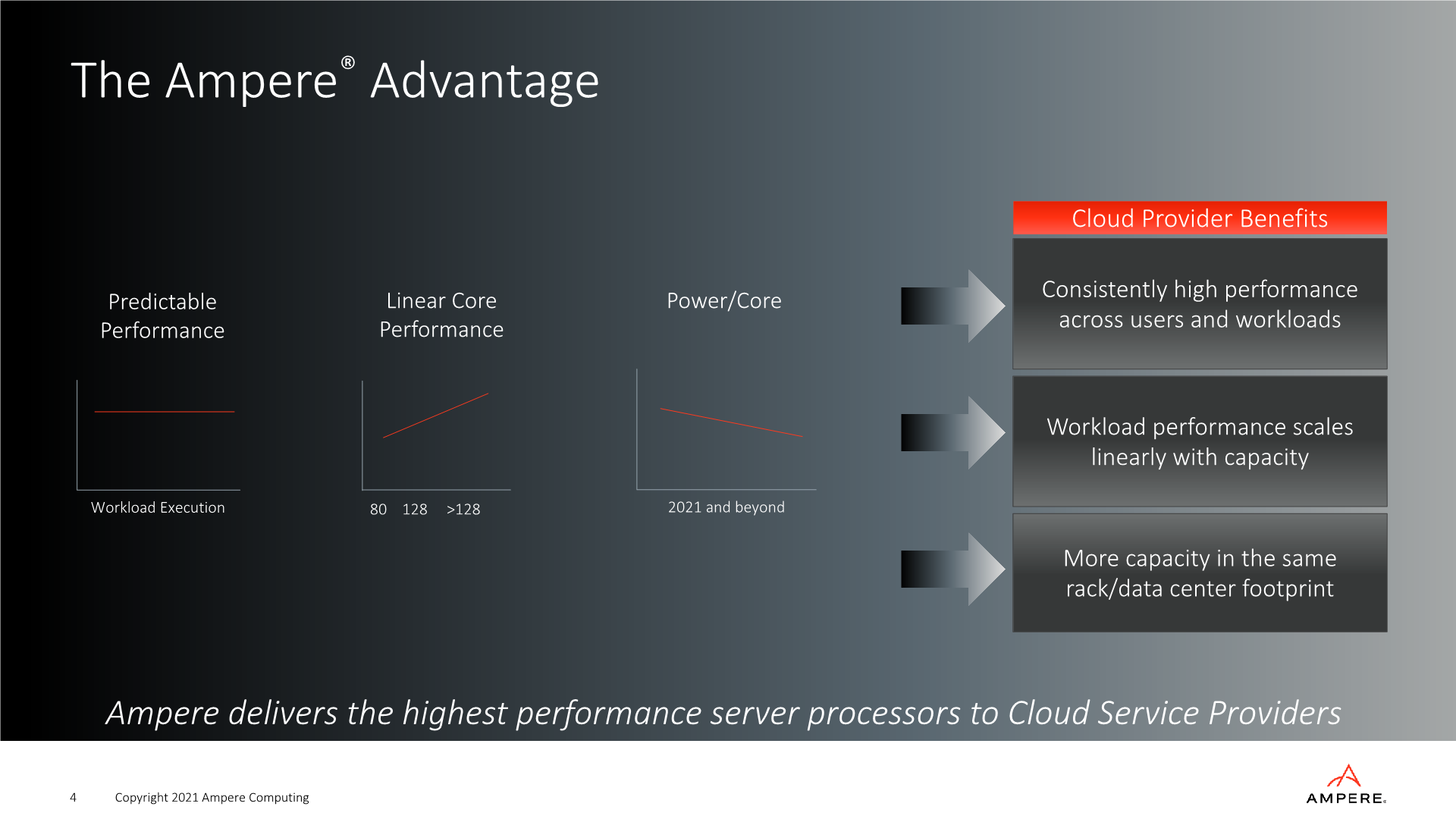
For the future for designs beyond the Altra Max, Ampere is promising that they will be continuing emphasis of what they consider “predictable performance” for workloads with scaling socket load, increasing core counts with a linear increase in performance, and what I found interesting as a metric, to continue to reduce power per core – something to keep in mind as we’re discussing the next big news today:
Replacing Neoverse with Full Custom Cores
Today’s big reveal comes in regard to the microarchitecture choices that Ampere is going to be using starting in their next generation 2022 “Siryn” design, successor to the Altra Max, and relates to the CPU IP being used:
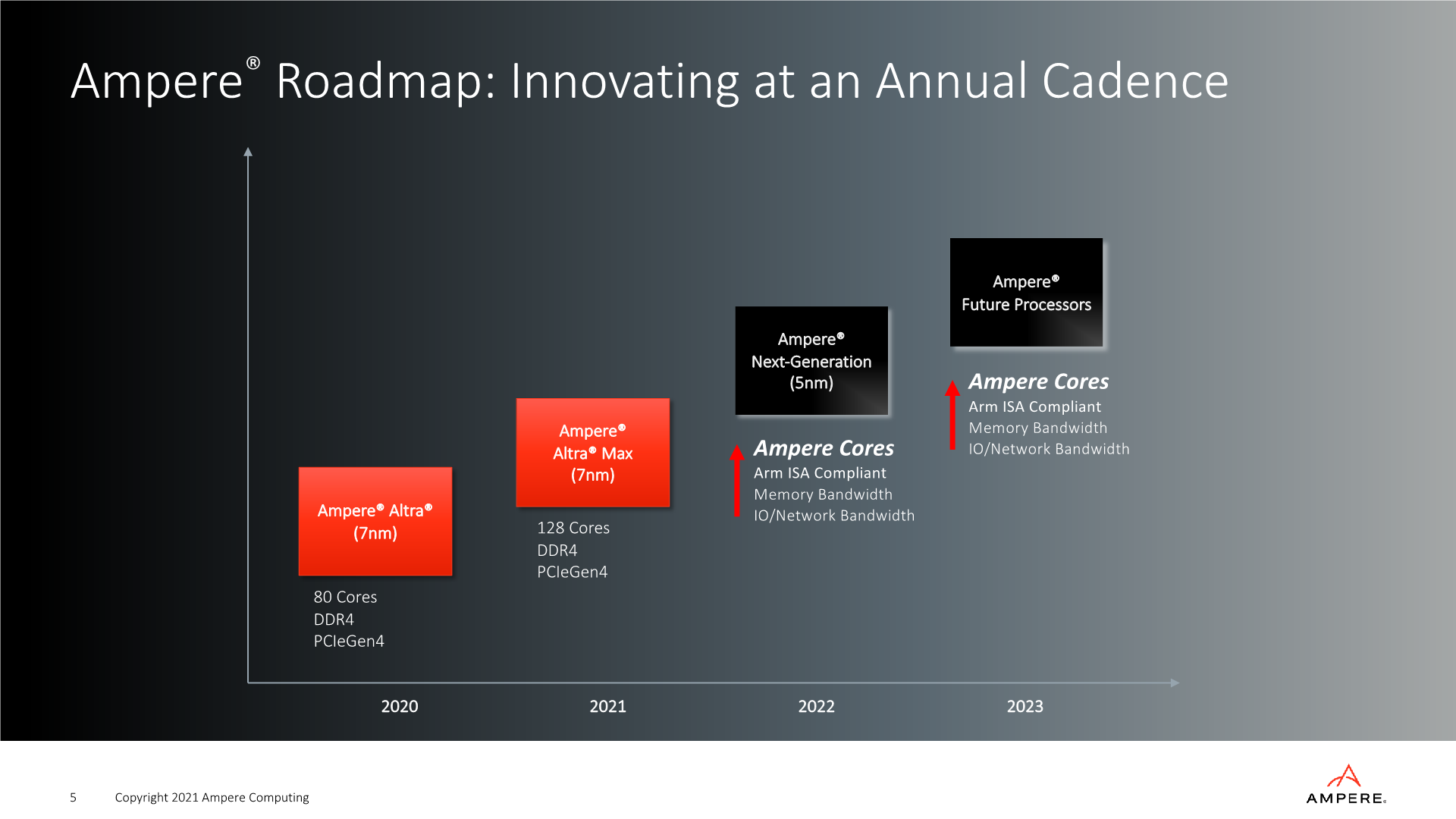
Starting with Siryn, Ampere will be switching over from Arm’s Neoverse cores to their new in-house full custom CPU microarchitecture. This announcement admittedly caught us completely off-guard, as we had largely expected Ampere to continue to be using Arm’s Neoverse cores for the foreseeable future. The switch to a new full custom microarchitecture puts Ampere on a completely different trajectory than we had initially expected from the company.
In fact, Ampere explains that what the move towards a full custom microarchitecture core design was actually always the plan for the company since its inception, and their custom CPU design had been in the works for the past 3+ years.
In terms of background - the design team leading the effort is lead by Ampere’s CTO Atiq Bajwa, who is also acting as the chief architect on the project. Bajwa and the team surrounding him appear to be mostly comprised of high-profile ex-Intel engineers and veterans which had left the company along with Renée James in 2017, topped-off with talent from a slew of other companies in the industry who joined them in the effort. The pedigree and history of the team is marked by achievements such as working on Intel’s Haswell and Broadwell processors.
Ampere’s explanation and rationale for designing a full custom core from the ground up, is that they are claiming they are able to achieve better performance and better power efficiency in datacentre workloads compared to what Arm’s Neoverse “more general purpose” designs are able to achieve. This is quite an interesting claim to make, and contrasts Arm’s projections and goals for their Neoverse cores. The recent Neoverse V1 and N2 cores were unveiled in more detail last month and are claimed to achieve significant generational IPC gains.
For Ampere to relinquish the reliance on Arm’s next-gen cores, and instead to rely on their own design and actually go forward with that switch in the next-gen product, shows a sign of great confidence in their custom microarchitecture design – and at the same time one could interpret it as a sign of no confidence in Arm’s Neoverse IP and roadmap. This comes at a great juxtaposition to what others are doing in the industry: Marvell has stopped development of their own ThunderX CPU IP in favour of adopting Arm Neoverse cores. On the other hand, not specifically related to the cloud and server market, Qualcomm earlier this year have acquired Nuvia, and their rationale and explanation was similar to Ampere’s in that they’re claiming that the new in-house design capabilities offered performance that otherwise wouldn’t have been possible with Arm’s Cortex CPU IP.
In our talks with Jeff Wittich, Ampere’s Chief Product Officer, he explains that today’s announcement should hopefully help paint a better picture of where Ampere is heading as a company – whether they’d continue to be content on “just” being an Arm IP integrator, or if they had plans for more. Jeff was pretty clear that in a few years’ time they’re envisioning and aiming for Ampere to be a top CPU provider for the cloud market and major player in the industry.
In terms of technical details as to how Ampere’s CPU microarchitecture will be different in terms of approach and how and why they see it as a superior performer in the cloud, are questions to which we’ll have to be a bit more patient for hearing answers to. The company wouldn’t comment on the exact status of the Siryn design right now – on whether it’s been taped in or taped out yet, but they do retierate that they’re planning customer sampling in early 2022 in accordance to prior roadmap disclosures. By the tone of the discussions, it seems the design is mostly complete, and Ampere is doing the finishing touches on the whole SoC. Jeff mentioned that in due time, they also will be doing microarchitectural disclosures on the new core, explaining their design choices in things like front-end or back-end design, and why they see it as a better fit for the cloud market.
Altra Max later this year, more cloud customer disclosures
Beyond the longer-term >2022 plans, today’s roadmap updates also contained a few more performance claim reiterations of Ampere’s upcoming 128-core Altra Max product, which is planned to hit the market later in the second half of the year and customers being sampled in the next few months.
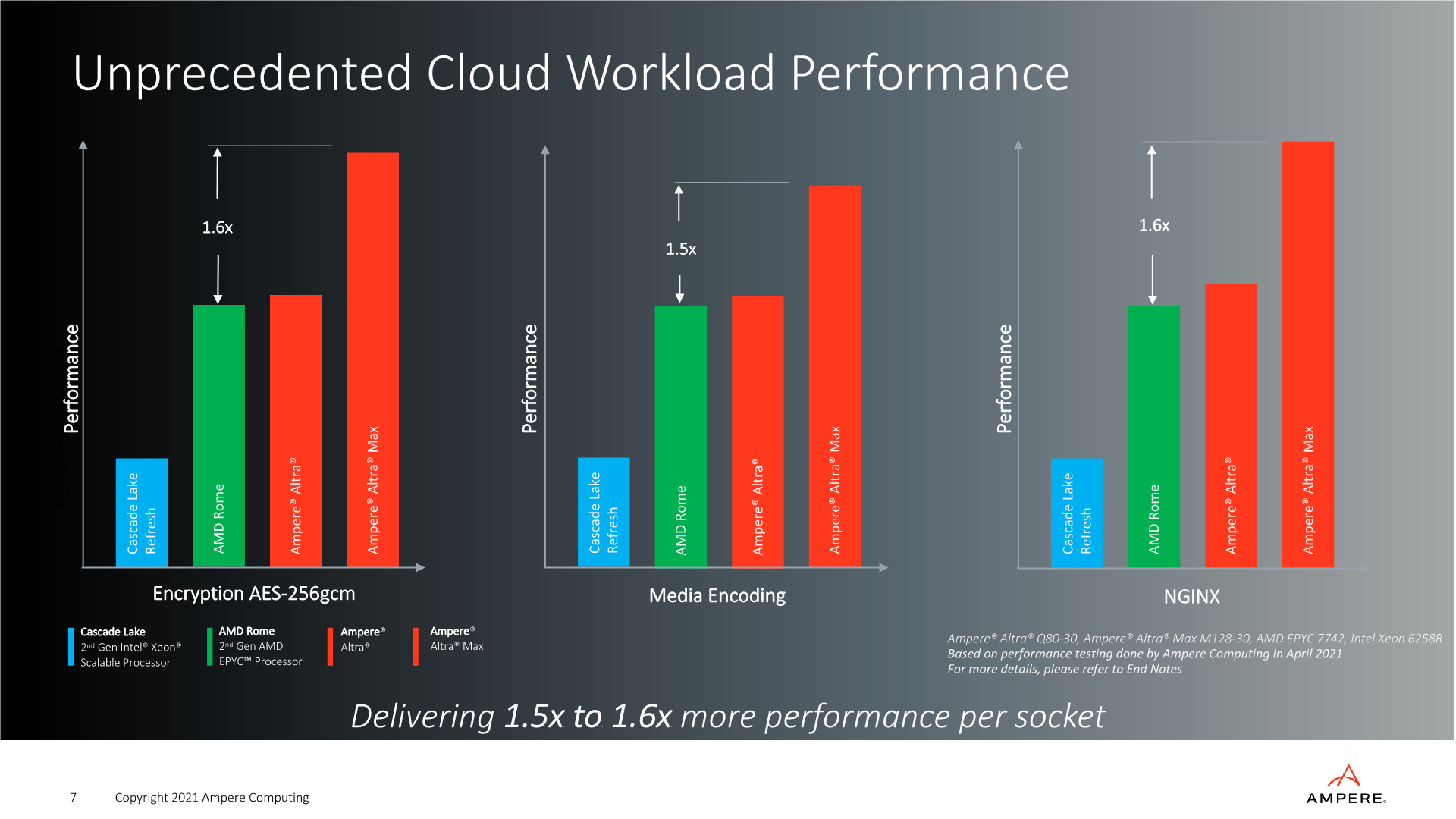
The “Mystique” code-named Altra Max design will be characterised in that it’s able to increase the core-count by 60% versus the current generation Altra design, all while remaining at and below the same 250W TDP. The performance slides here are showcasing comparisons and performance claims against what is by now the previous generation competitor products, Ampere here simply explains they haven’t been able to get their hands on more recent Milan or Ice Lake-SP hardware to test. Nevertheless, the relative positioning against the Altra Q80-30 and the EPYC 7742 would indicate that the new chip would easily surpass the performance of even AMD’s latest EPYC 7763.
In the slide, Ampere actually discloses the SKU model name being used for the comparison, which is the "Altra Max M128-30" – meaning for the first time we have confirmation that all 128 cores are running at up to 3GHz clock speed, which is impressive given that we’re supposed to be seeing the same TDP and power characteristics between it and the Q80-33. We’ll be verifying these figures in the next few months once we get to review the Altra Max.

Today’s announcement also comes with an update on Ampere’s customers. Oracle was notably one of the first Altra adopters, but today’s disclosure also includes a wider range of cloud providers, with big names such as ByteDance and Tencent Cloud, two of the biggest hyperscalers in China.
Microsoft in particular is a big addition to the customer list, and while Ampere’s Jeff Wittich couldn’t comment on whether Microsoft has other internal plans in the works, he said that today’s announcement should give more clarity around the rumours of the Redmond company working on Arm-based servers, reports of which had surfaced back in December. Microsoft’s Azure cloud service is only second to Amazon’s AWS in terms of size and scale, and the company onboarding Altra products is a massive win for Ampere.
Taking control of one’s own future
Today’s announcements by Ampere of them deploying their own microarchitecture in future products is a major change in the company’s prospects. The news admittedly took us by surprise, but in the grand scheme of things it makes a lot of sense given that the company aims to be a major industry player in the next few years – taking full control of one’s own product future is critical in terms of assuring that success.
While over the years we’ve seen many CPU design teams be disbanded, actually having a new player and microarchitecture pop up is a much welcome change to the industry. While the news is a blow to Arm’s Neoverse IP, the fact that Ampere continues to use the Arm architecture is a further encouragement and win for the Arm ecosystem.
Related Reading:
- The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
- Oracle Announces Upcoming Cloud Compute Instances: Ice Lake and Milan, A100 and Altra
- Next Generation Arm Server: Ampere’s Altra 80-core N1 SoC for Hyperscalers against Rome and Xeon
- Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
- Intel 3rd Gen Xeon Scalable (Ice Lake SP) Review: Generationally Big, Competitively Small
- AMD 3rd Gen EPYC Milan Review: A Peak vs Per Core Performance Balance








160 Comments
View All Comments
Wilco1 - Wednesday, May 19, 2021 - link
The thing is, that graph is trying to be honest. Nobody else can sustain such large yearly IPC improvements. Moore's law is still holding on, but don't expect large frequency uplifts from new processes either. So everybody is in the same boat.Your math is off as well - Neoverse N1 is from 2019 and Neoverse V1 is in 2021, so that's 50% uplift in 2 years. N2 is a later, efficiency optimized core with slightly lower performance, but that doesn't change the performance gain of Neoverse V1 - unless you're trying to downplay the significant performance gains made by recent Arm cores...
ikjadoon - Wednesday, May 19, 2021 - link
Nope, the math is perfect. The N1 uarch is based on the 2018 A76. See AnandTech’s chart, designed by Andrei himself:https://www.anandtech.com/show/16640/arm-announces...
The Cortex A77 was released in 2019 and it has not been used a single Neoverse CPU.
//
And then after Matterhorn and Makalu? Surely NUVIA, Apple, Qualcomm, Ampere, and everyone else have seen Arm’s stock core roadmap. All of them used Arm cores for a few generations (NUVIA excluded) and went to custom.
You don’t need to beat Arm by 50%. Even a 10% IPC win versus Arm per year adds up.
Arm stock microarchitectures aren’t bad, but they’re not performance leaders. Likewise, It’s not just IPC, but perf-per-watt, too, as Ampere wrote.
Samsung, NVIDIA, Amazon are all hanging on, but I don’t expect any performance leadership from any of their designs.
Wilco1 - Wednesday, May 19, 2021 - link
No your math is way off. Neoverse N1 was announced in February 2019 with implementations late 2019. Neoverse V1 was just announced with first implementations likely later this year. So that's 50% performance gain in 2 years. It's the same for Cortex-A76 to Cortex-X1. The roadmap shows another 30% in the next 2 years, so that averages to 18% per year over 4 years. That's very hard to beat.Many companies have tried custom cores but gave up (QC are at their 4th try with Nuvia and kept using Cortex cores alongside custom designs). It's possible to differentiate and get a 10-20% gain but gaining 10% yearly is unlikely. Apple is ahead because they spend many times more area on cores and caches than everybody else and pay a premium for early access to the latest processes. Those are one-off gains, you can't keep doubling your caches every year...
Ampere Altra is proof of performance and efficiency leadership for a stock Arm core. From the article the decision to go custom seems more about specialization for the cloud market. You could cut down the floating point and Neon units if integer performance is all you want.
Wilco1 - Wednesday, May 19, 2021 - link
Btw it's actually possible Arm's latest Neoverse cores are simply too fast. A custom core that is say only 20% faster than Neoverse N1 (but at same area by cutting down FP/Neon and 32-bit support) might well be more suited for certain cloud applications.mode_13h - Friday, May 21, 2021 - link
> it's actually possible Arm's latest Neoverse cores are simply too fast.LOL.
> cutting down FP/Neon
They're already #losing on FP. And the N1's vector width is only 2x 128-bit, as compared with Zen's 4x 256-bit and Intel's 2x 512-bit. So, it's not like the N1 is burning a ton of die space on it, or has a lot of excess FP performance to spare.
Wilco1 - Friday, May 21, 2021 - link
Ampere is aiming at integer cloud workloads. N1 achieves 86% of the FP performance of Milan with just 2x128-bit pipes, which is likely more than Ampere needs. Since N1 is absolutely tiny compared to Zen 3 or IceLake, the 2x128-bit pipes are actually a significant fraction of its die size.mode_13h - Friday, May 21, 2021 - link
> the 2x128-bit pipes are actually a significant fraction of its die size.Let's take this as given and look to the N2. It's not increasing its vector pipelines in either width or count (but they report some wins from simply using SVE), in spite of going to 5 nm. So, if they're not increasing the N2's FPU, in spite of the overall core size getting larger, then that means it'll constitute a smaller portion of the N2. That naturally leads to the question of what Siryn stands to gain, by making an even *smaller* FPU? I'd say: not much.
Wilco1 - Saturday, May 22, 2021 - link
N2 adds SVE2 so the vector pipelines are larger and more complex. FP performance is likely 40% higher than N1, so you could cut out a lot if all you wanted is bare-bones FP/SIMD like Ampere's eMAG generation.Saving 10-15% area directly translates to more cores/cache and lower costs. We are talking about 128+ cores so small savings per core add up.
mode_13h - Sunday, May 23, 2021 - link
> N2 adds SVE2 so the vector pipelines are larger and more complex.> FP performance is likely 40% higher than N1
Why would you expect the same number & width of pipelines @ the same clock speed to deliver that kind of speedup? According to ARM's own estimates, the N2 delivers only about 20% speedup at about 60th percentile. Median speedup looks to be only about 15%.
https://images.anandtech.com/doci/16640/Neoverse_V...
> Saving 10-15% area directly translates to more cores/cache and lower costs.
It's very unlikely one 128-bit SVE pipeline takes 10% of die area, and you can't have less than 128-bits in ARMv9. I suppose they could simplify the pipeline stages at the expense of latency, but that could really start to hurt code that uses even a little floating-point, which is probably more common in "server workloads" than it used to be.
Wilco1 - Tuesday, May 25, 2021 - link
> Why would you expect the same number & width of pipelines @ the same clock speed to deliver that kind of speedup?Because the rest of the core is improved. The bottleneck is usually the frontend and caches rather than the FP pipes. For example the Cortex-A77 article shows a 23% speedup over Cortex-A76 on SPECINT_2017 but a larger 28% speedup for FP despite no reported changes to the SIMD pipes: https://images.anandtech.com/doci/14384/CortexA77-...
You can reduce the area significantly, eg. using a single 64-bit FMA pipe that needs 2 cycles for 128-bit SIMD. That would work fine with code that needs a bit of scalar floating point.