AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
Floating-point Analyses (Linux 64-bit)
AMD's newest quad-core behaves pretty weird when it comes to floating-point applications. In some FP intensive applications (CINEBENCH and LINPACK for example) a 2GHz quad-core cannot even keep up with Intel's older 2GHz 65nm quad-core CPUs; in other applications it is a close match (3ds Max, POV-Ray); finally, in applications like zVisuel's 3D Engine and SPECfp, Barcelona is clearly faster clock-for-clock than the older generation. Our aim is to understand this situation a little better and to see what the 45nm Xeon 54xx can achieve.
To understand this we first tested with two synthetic, but completely opposite FP benchmarks:
- LINPACK,
which calculates on massive matrices
- FLOPS, which fits in an 8 KB L1 cache
Let us start with LINPACK. LINPACK, a benchmark application based on the LINPACK TPP code, has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight (dual quad-core) threads. As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPACK is expressed in GFLOPS (Giga/Billions of Floating Operations Per Second).
We used two versions of LINPACK:
- Intel's
version of LINPACK compiled with the Intel Math Kernel Library (MKL)
- A fully optimized "K10-only" version for AMD's quad-core
The "K10-only" version uses the ACML version 4.0.0, compiled using the PGI 7.0.7. We used the following flags:
pgcc -O3 -fast -tp=barcelona-64
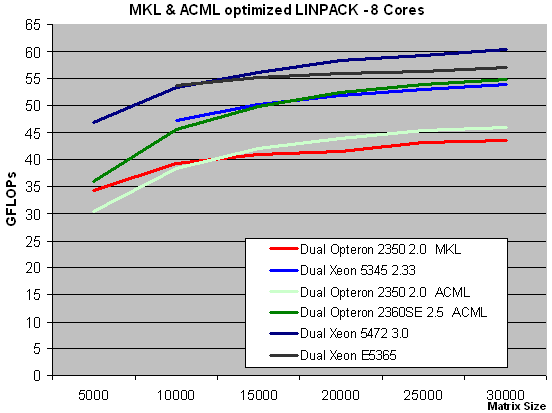
The graph above may come as a surprise to a quite few people. At the lower matrix sizes, AMD's quad-core is even a bit faster with the "Intel version" than with the specially optimized version. Only while calculating with the larger matrices does the heavily tuned version pull ahead. The K10-only version of LINPACK is about 6% faster, and the most important reason for that improvement is the ACML library of AMD. However, it is clear that the Intel MKL and compiler are not slowing the AMD core down when it is running LINPACK.
There is more. At first sight, the AMD 2360SE scores seem rather poor: just a tiny bit faster than the 2.33GHz quad-core of Intel. However, the Intel CPU scales rather poorly with clock speed: a 3GHz Clovertown is only 6% faster than a 2.33GHz one while the clock speed advantage is 28%. The Barcelona core however scales 19% from a 20% clock speed boost. The new Seaburg platform cannot help here: a 3GHz Xeon E5365 was capable of 57.1 GFLOPS, while it got 57 GFLOPS with the older chipset.
Intel's clever compiler engineers have already found a way around this, as the newest release of their LINPACK version is quite a bit faster on both Clovertown and Harpertown. The LINPACK score increases to 70 GLOPs for the Xeon 5472 3GHz (60.5 in our test) and 63 for the Xeon E5365 3GHz (57 in our test). Unfortunately, we don't have any data on what has changed, so we decided to freeze our benchmark code for now.








43 Comments
View All Comments
Hans Maulwurf - Wednesday, November 28, 2007 - link
Agreed, I have not seen an article as good as this one for years at Anandtech. And not for some time on other review sites as well.Thank you.
JohanAnandtech - Tuesday, November 27, 2007 - link
Thanks people. This kind of articles take ridiculously amounts of time and I really appreciate that you let me know that you liked the article. It keeps us going. (and I mean that!)magreen - Tuesday, November 27, 2007 - link
Excellent article, thorough and with amazing depth and expertise. Keep up the great work AT!Bluestealth - Tuesday, November 27, 2007 - link
I agree, it was a very well done article. I can't wait to see how Intel's processors preform on Hyper... errr... Common System Interface (next year?). I believe that I will be buying AMD until that happens though for any servers.Regs - Tuesday, November 27, 2007 - link
Yeah, every time I see "Johan De Gelas" I have to read it.I like the added info on the Barc's L3 cache and the intro-factoid about the new architecture.
I agree that the Barc's arrival is a year late and joined the party a little too shy. Integer performance will likely have to be addressed in the Bulldozer in 2-3 years. Which is 2-3 years too long. I would be really surprised if they can manage anything other than a die shrink for Shanghi with maybe more L3 cache and some tweaks for cache latency and SSE.
Just seems like AMD took a nose dive in development for their processors in the past 3-4 years. After the K8 I would think they would be able to come up with something more innovative. Revolutionary should of never entered their heads and they should actually look down upon themselves for using such a word after 4 years.
jones377 - Tuesday, November 27, 2007 - link
Any chance you could use the same tools to profile desktop applications as well in the future?DigitalFreak - Tuesday, November 27, 2007 - link
Three months or so since "launch", and you still can't get a server with AMD quad-core chips from any of the big 3 vendors (HP, Dell, IBM). AMD really screwed the pooch on this one.jojo4u - Tuesday, November 27, 2007 - link
Yuck, ugly GIF on the first page. Please use PNG because 256 colors are not enough for screenshots ;)deathwombat - Saturday, December 1, 2007 - link
In addition to being less ugly, PNG's higher compression would also make the file smaller (using less bandwidth), which I assume is what they were going for.jkostans - Tuesday, November 27, 2007 - link
Didn't even notice.