AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
Raw FPU power: FLOPS
Let us see if we understand floating-point performance better when we look at FLOPS. FLOPS was programmed by Al Aburto and is a very floating-point intensive benchmark. Analysis show that this benchmark contains:
- 70% floating-point
instructions
- Only 4% branches
- Only 34% of instructions are memory instructions
Benchmarking with FLOPS is not real world, but isolates the FPU power. Al Aburto states the following about FLOPS:
"Flops.c is a 'C' program which attempts to estimate your systems floating-point 'MFLOPS' rating for the FADD, FSUB, FMUL, and FDIV operations based on specific 'instruction mixes'. The program provides an estimate of PEAK MFLOPS performance by making maximal use of register variables with minimal interaction with main memory. The execution loops are all small so that they will fit in any cache."
FLOPS shows the maximum double precision power that the core has, by making sure that the program fits in the L1 cache. FLOPS consists of eight tests, and each test has a different but well-known instruction mix. The most frequently used instructions are FADD (addition, 1st number), FSUB (subtraction, 2nd number), and FMUL (multiplication, 3rd number). FDIV is the fourth number in the mix. We focused on four tests (1, 3, 4, and 8) as the other tests were very similar.
We compiled three versions:
- Gcc
(GCC) 4.1.2 20070115 (prerelease) (SUSE Linux)
- Intel C Compiler (ICC) version 10.1 20070913:
- An x87 version
- A fully vectorized SSE2 version
- An x87 version
Let us restate what we are measuring with FLOPS:
- Single-threaded
double precision floating performance
- Maximum performance not constrained by bandwidth bottlenecks or latency delays
- Perfect clock speed scaling
This allows us to calculate the FLOPS per cycle number: we divide the MFLOPs numbers reported by FLOPS by the clock speed. This way we get a good idea of the raw floating-point power of each architecture. First we test with the basic '-O3' optimization.
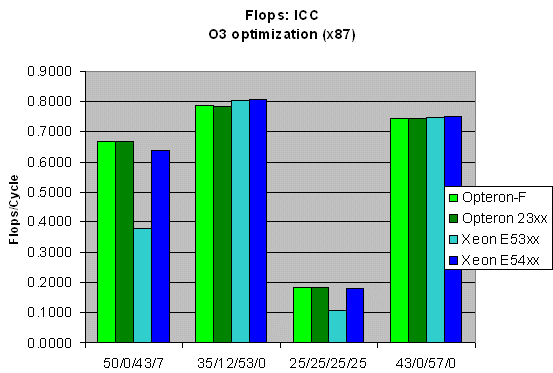
Don't you love the little FLOPS benchmark? It is far from a real world benchmark, but it tells us so much.
To understand this better, know that the raw speed of the AMD out of order x87 FPU (Athlon K7 and Athlon 64) used to be between 20% and 60% faster clock for clock than any P6 based CPU, including Banias and Dothan. However, this x87 FPU advantage has evaporated since the introduction of the Core architecture as the Core Architecture has a separate FMUL and FADD pipe. (Older P6 architectures could execute one FADD followed by one FMUL, or two FP operations per two clocks at the most). You can see that when we test with a mix of FADD/FSUB and FMUL, the Core architecture is slightly faster clock for clock.
The only weakness remaining in the Core x87 architecture is the FP divider. Notice how even a relatively low percentage of divisions (the 4th number in the mix) kills the performance of our 65nm Xeon. The Opteron 22xx and 23xx are 70% faster (sometimes more) when it comes to double precision FP divisions. However, the new Xeon 54xx closes this gap completely thanks to lowering the latency of a 64-bit FDIV from 32 cycles (Xeon 53xx) to 20 cycles (Xeon 54xx, Opteron 23xx). The Xeon 54xx is only 1% to 5% slower in the scenarios where quite a few divisions happen. That is because the Opterons are capable of somewhat pipelining FDIVs, which allows them to retire one FDIV every 17 cycles. The clock speed advantage of the 45nm Xeon (3.2GHz vs. 2.5GHz maximum at present) will give it a solid lead in x87 performance.
However, x87 performance is not as important as it used to be. Most modern FP applications make good use of the SSE SIMD instruction set. Let us see what happens if we "vectorize" our small FLOPS loops. Remember, FLOPS runs from the L1 cache, so L2 and memory bandwidth do not matter at all.
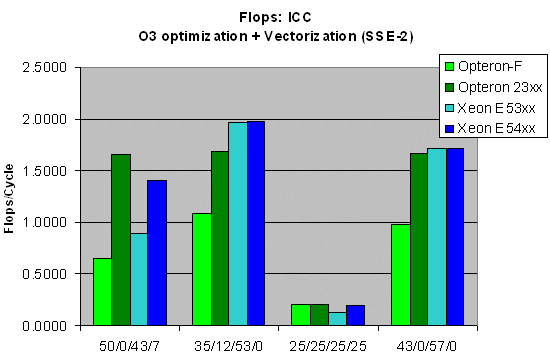
When it comes to raw SSE performance, the Intel architectures are 3% to 14% faster in the add/subtract/multiply scenarios. When there are divisions involved, Barcelona absolutely annihilates the 65nm Core architecture with up to 80% better SSE performance, clock for clock. It even manages to outperform the newest 45nm Xeon, but only by 8% to 18%. Notice once again the vast improvement from the 2nd generation Opteron to the 3rd generation Opteron when it comes to SIMD performance, ranging from 55% to 150% (!!).
As not all applications are compiled using Intel's high-performance compiler, we also compiled with the popular open source compiler gcc. Optimization beyond "-O3" had little effect on our FLOPS binary, so we limited our testing to one binary.
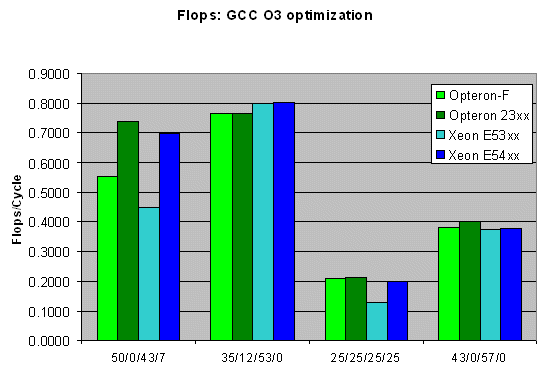
GCC paints about the same picture as ICC without vectorization. The new AMD Barcelona core has a small advantage, as it is the fastest chip in 3 out of 4 tests. Let us now see if we can apply our FP analyses of LINPACK and FLOPS to real world applications.








43 Comments
View All Comments
Hans Maulwurf - Wednesday, November 28, 2007 - link
Agreed, I have not seen an article as good as this one for years at Anandtech. And not for some time on other review sites as well.Thank you.
JohanAnandtech - Tuesday, November 27, 2007 - link
Thanks people. This kind of articles take ridiculously amounts of time and I really appreciate that you let me know that you liked the article. It keeps us going. (and I mean that!)magreen - Tuesday, November 27, 2007 - link
Excellent article, thorough and with amazing depth and expertise. Keep up the great work AT!Bluestealth - Tuesday, November 27, 2007 - link
I agree, it was a very well done article. I can't wait to see how Intel's processors preform on Hyper... errr... Common System Interface (next year?). I believe that I will be buying AMD until that happens though for any servers.Regs - Tuesday, November 27, 2007 - link
Yeah, every time I see "Johan De Gelas" I have to read it.I like the added info on the Barc's L3 cache and the intro-factoid about the new architecture.
I agree that the Barc's arrival is a year late and joined the party a little too shy. Integer performance will likely have to be addressed in the Bulldozer in 2-3 years. Which is 2-3 years too long. I would be really surprised if they can manage anything other than a die shrink for Shanghi with maybe more L3 cache and some tweaks for cache latency and SSE.
Just seems like AMD took a nose dive in development for their processors in the past 3-4 years. After the K8 I would think they would be able to come up with something more innovative. Revolutionary should of never entered their heads and they should actually look down upon themselves for using such a word after 4 years.
jones377 - Tuesday, November 27, 2007 - link
Any chance you could use the same tools to profile desktop applications as well in the future?DigitalFreak - Tuesday, November 27, 2007 - link
Three months or so since "launch", and you still can't get a server with AMD quad-core chips from any of the big 3 vendors (HP, Dell, IBM). AMD really screwed the pooch on this one.jojo4u - Tuesday, November 27, 2007 - link
Yuck, ugly GIF on the first page. Please use PNG because 256 colors are not enough for screenshots ;)deathwombat - Saturday, December 1, 2007 - link
In addition to being less ugly, PNG's higher compression would also make the file smaller (using less bandwidth), which I assume is what they were going for.jkostans - Tuesday, November 27, 2007 - link
Didn't even notice.