AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
Software Rendering: zVisuel (32-bit Windows)
This benchmark is the zVisuel Kribi 3D test, which is exclusive to AnandTech.com and which simulates the assembly of a mechanical watch. The complete model is very detailed with around 300,000 polygons and a lot of texture, bump, and reflection maps. We render more than 1000 frames and report the average FPS (frames per second). All this is rendered on the "Kribi 3D" engine, an ultra-powerful real-time software rendering 3D engine. That all this happens at reasonable speeds is a result of the fact that the newest AMD and Intel architectures contain four cores and can perform up to eight 32-bit FP operations per clock cycle and per core. The people of zVisuel told us that - in reality - the current Core architecture can sustain six FP operations in well-optimized loops. Profiling for Barcelona architecture is not yet complete, so we did our best with CodeAnalyst 2.74 for Windows. We only profiled the non-AA benchmark so far.
| ZVisuel Kribi3D Profiling | |
| Profile | Total |
| Average IPC (on Opteron 2350) | 1 |
| Instruction mix | |
| Floating Point | 31% |
| SSE | 35% |
| Branches | 6% |
| L1 datacache ratio | 0.63 |
| L1 Instruction ratio | 0.22 |
| Performance indicators on Opteron 2350 | |
| Branch misprediction | 8% |
| L1 datacache miss | 1% |
| L1 Instruction cache miss | 1% |
| L2 cache miss | 0% |
This is a very different engine than the scanline-rendering engine of 3ds Max. SSE instructions play a very dominant role, and the zVisuel Kribi 3D benchmark gives us a view on how the different CPUs perform on well-optimized SSE applications. While the application seems to run almost perfectly from the L2 cache, this seems to be a result of well-tuned, predictable access to the memory. We noticed that hardware prefetching and the new Seaburg chips help this benchmark a lot:
| Zvisuel Intel Platform Performance Comparison | |||
| CPU | HW Prefetch on | HW Prefetch disabled | Difference |
| Dual Xeon E5365 3.0 (Blackford) | 99.9 | 87.7 | 14% |
| Dual Xeon E5365 3.0 (Seaburg) | 110 | 104.2 | 6% |
| Dual Xeon E5472 3.0 (Seaburg) | 124.8 | 110 | 13% |
Let us see all the results.
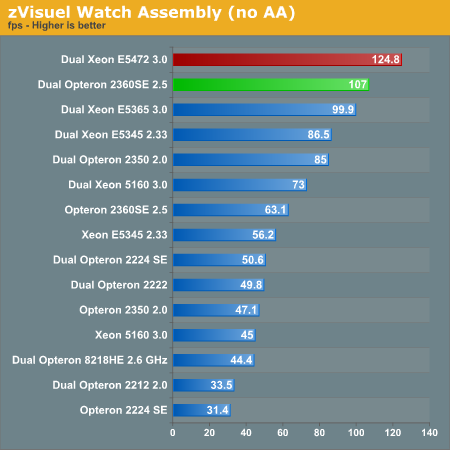

Although we haven't done a detailed analysis, we can assume that the "Super Shuffle Engine" and "Radix-16" divider that Intel has implemented in the Xeon 5472 is paying off here. AMD Opteron 2360 SE at 2.5GHz can overtake the best Xeon at 65nm, but the new Xeon has a tangible lead. A silver lining to the cloud hanging over AMD is that the Opteron 23xx series scale perfectly with clock speeds: compare the 2GHz with the 2.5GHz results. Still, Intel has the advantage when it comes to SSE processing.
The results with AA show that the memory subsystem of the Xeon 53xx is a major bottleneck, but the new Seaburg chipset has made this bottleneck a bit smaller. The result is a crushing victory for the latest Intel architecture. Enough FP testing, let us see what Barcelona can do when running typical integer server workloads.








43 Comments
View All Comments
Hans Maulwurf - Wednesday, November 28, 2007 - link
Agreed, I have not seen an article as good as this one for years at Anandtech. And not for some time on other review sites as well.Thank you.
JohanAnandtech - Tuesday, November 27, 2007 - link
Thanks people. This kind of articles take ridiculously amounts of time and I really appreciate that you let me know that you liked the article. It keeps us going. (and I mean that!)magreen - Tuesday, November 27, 2007 - link
Excellent article, thorough and with amazing depth and expertise. Keep up the great work AT!Bluestealth - Tuesday, November 27, 2007 - link
I agree, it was a very well done article. I can't wait to see how Intel's processors preform on Hyper... errr... Common System Interface (next year?). I believe that I will be buying AMD until that happens though for any servers.Regs - Tuesday, November 27, 2007 - link
Yeah, every time I see "Johan De Gelas" I have to read it.I like the added info on the Barc's L3 cache and the intro-factoid about the new architecture.
I agree that the Barc's arrival is a year late and joined the party a little too shy. Integer performance will likely have to be addressed in the Bulldozer in 2-3 years. Which is 2-3 years too long. I would be really surprised if they can manage anything other than a die shrink for Shanghi with maybe more L3 cache and some tweaks for cache latency and SSE.
Just seems like AMD took a nose dive in development for their processors in the past 3-4 years. After the K8 I would think they would be able to come up with something more innovative. Revolutionary should of never entered their heads and they should actually look down upon themselves for using such a word after 4 years.
jones377 - Tuesday, November 27, 2007 - link
Any chance you could use the same tools to profile desktop applications as well in the future?DigitalFreak - Tuesday, November 27, 2007 - link
Three months or so since "launch", and you still can't get a server with AMD quad-core chips from any of the big 3 vendors (HP, Dell, IBM). AMD really screwed the pooch on this one.jojo4u - Tuesday, November 27, 2007 - link
Yuck, ugly GIF on the first page. Please use PNG because 256 colors are not enough for screenshots ;)deathwombat - Saturday, December 1, 2007 - link
In addition to being less ugly, PNG's higher compression would also make the file smaller (using less bandwidth), which I assume is what they were going for.jkostans - Tuesday, November 27, 2007 - link
Didn't even notice.