The Best Server CPUs Compared, Part 1
by Johan De Gelas on December 22, 2008 10:00 PM EST- Posted in
- IT Computing
HPC
Several of the HPC benchmarks are way too expensive for us to test, and contrary to virtualization, web servers, and databases, we have little expertise in our lab to perform and fully understand these benchmarks. Nevertheless, we can get an impression from AMD's and Intel's own benchmarking. Two applications, LSDyna (Crash simulation) and Fluent (fluid dynamics) from Ansys seem to dominate the benchmark scene.
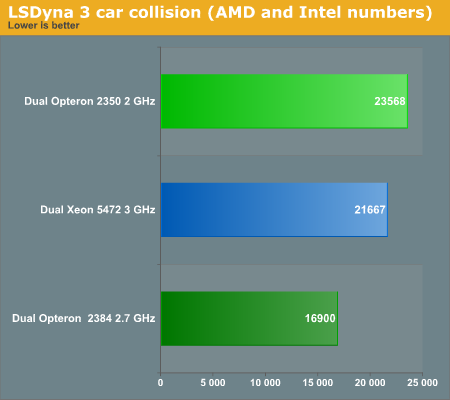
Back in 2007, the AMD 8350 was running at a paltry 2GHz, but it was already capable of keeping up with the best Intel CPUs. Intel seems to have improved its LSDyna scores a little bit. The introduction of the Xeon 5450 means that we get the same performance at a much lower TDP, but the Intel 3GHz CPU is no match for AMD's latest at 2.7GHz, as it still needs 30% more time to perform the complex crash simulation.
At the website of the Fluent benchmark we find a wealth of benchmarking info. The "Shanghai" numbers are not published there yet, so the numbers below are a combination of already published numbers (Intel) and AMD's own benchmarking numbers.
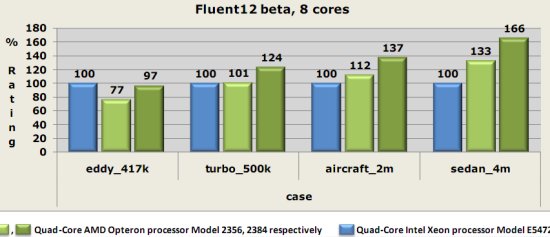
AMD's best quad-core is in a neck and neck race in the first benchmark, but the other benches show a significant (24%) to supreme (66%) advantage for the latest AMD chip. The newest AMD quad-core clearly strengthens the position of AMD in the HPC market.








29 Comments
View All Comments
zpdixon42 - Wednesday, December 24, 2008 - link
DDR2-1067: oh, you are right. I was thinking of Deneb.Yes performance/dollar depends on the application you are running, so what I am suggesting more precisely is that you compute some perf/$ metric for every benchmark you run. And even if the CPU price is less negligible compared to the rest of the server components, it is always interesting to look both at absolute perf and perf/$ rather than just absolute perf.
denka - Wednesday, December 24, 2008 - link
32-bit? 1.5Gb SGA? This is really ridiculous. Your tests should be bottlenecked by IOJohanAnandtech - Wednesday, December 24, 2008 - link
I forgot to mention that the database created is slightly larger than 1 GB. And we wouldn't be able to get >80% CPU load if we were bottlenecked by I/Odenka - Wednesday, December 24, 2008 - link
You are right, this is a smallish database. By the way, when you report CPU utilization, would you take IOWait separate from CPU used? If taken together (which was not clear) it is possible to get 100% CPU utilization out of which 90% will be IOWait :)denka - Wednesday, December 24, 2008 - link
Not to be negative: excellent article, by the waymkruer - Tuesday, December 23, 2008 - link
If/When AMD does release the Istanbul (k10.5 6-core), The Nehalem will again be relegated to second place for most HPC.Exar3342 - Wednesday, December 24, 2008 - link
Yeah, by that time we will have 8-core Sandy Bridge 32nm chips from Intel...Amiga500 - Tuesday, December 23, 2008 - link
I guess the key battleground will be Shanghai versus Nehalem in the virtualised server space...AMD need their optimisations to shine through.
Its entirely understandable that you could not conduct virtualisation tests on the Nehalem platform, but unfortunate from the point of view that it may decide whether Shanghai is a success or failure over its life as a whole. As always, time is the great enemy! :-)
JohanAnandtech - Tuesday, December 23, 2008 - link
"you could not conduct virtualisation tests on the Nehalem platform"Yes. At the moment we have only 3 GB of DDR-3 1066. So that would make pretty poor Virtualization benches indeed.
"unfortunate from the point of view that it may decide whether Shanghai is a success or failure"
Personally, I think this might still be one of Shanghai strong points. Virtualization is about memory bandwidth, cache size and TLBs. Shanghai can't beat Nehalem's BW, but when it comes to TLB size it can make up a bit.
VooDooAddict - Tuesday, December 23, 2008 - link
With the VMWare benchmark, it is really just a measure of the CPU / Memory. Unless you are running applications with very small datasets where everything fits into RAM, the primary bottlenck I've run into is the storage system. I find it much better to focus your hardware funds on the storage system and use the company standard hardware for server platform.This isn't to say the bench isn't useful. Just wanted to let people know not to base your VMWare buildout soley on those numbers.