SSD versus Enterprise SAS and SATA disks
by Johan De Gelas on March 20, 2009 2:00 AM EST- Posted in
- IT Computing
Testing in the Real World
As interesting as the SQLIO and IOMeter results are, those benchmarks focus solely on the storage component. In the real world, we care about the performance of our database, mail, or fileserver. The question is: how does this amazing I/O performance translate into performance we really care about like transactions or mails per second? We decided to find out with 64-bit MySQL 5.1.23 and SysBench on SUSE Linux SLES 10 SP2.
We utilize a 23GB database and carefully optimized the my.cnf configuration file. Our goal is to get an idea of performance for a database that cannot fit completely in main memory (i.e. cache); specifically, how will this setup react to the fast SLC SSDs. The Innodb buffer pool that contains data pages, adaptive hash indexes, insert buffers, and locks is set to 1GB. That is indeed rather small, as most servers contain 4GB to 32GB (or even more) and MySQL advises you to use up to 80% of your RAM for this buffer. Our test machine has 8GB of RAM, so we should have used 6GB or more for this buffer. However, we really wanted our database to be about 20 times larger than our buffer pool to simulate a large database that can only partially fit within the memory cache. With our 32GB SLC SSDs, using a 6.5GB buffer pool and a 130GB large database was not an option. Hence, the slightly artificial limitation of our buffer pool size.
We let SysBench perform all kinds of inserts and updates on this 23GB database. As we want to be fully ACID compliant our database is configured with:
innodb_flush_log_at_trx_commit = 1
After each transaction is committed, there is a "pwrite" first followed by an immediate flush to the disk. So the actual transaction time is influenced by the disk write latency even if the disk is nowhere near its limits. That is an extremely interesting case for SSDs to show their worth. We came up with four test configurations:
- "Classical SAS": We use six SAS disks for the data and two for the logs.
- "SAS data with SSD logging": perhaps we can accelerate our database by simply using very fast log disks. If this setup performs much better than "classical SAS", database administrators can boost the performance of their OLTP applications with a small investment in log SSDs. From an "investment" point of view, this would definitely be more interesting than having to replace all your disks with SSDs.
- "SSD 6+2": we replace all of our SAS disks with SSDs. We stay with two SSDs for the logs and six disks for the data.
- "SSD data with SAS logging": maybe we just have to replace our data disks, and we can keep our logging disks on SAS. This makes sense as logging is sequential.
Depending on how many random writes we have, RAID 5 or RAID 10 might be the best choice. We did a test with SysBench on six Intel X25-E SSDs. The logs are on a RAID 0 set of two SSDs to make sure they are not the bottleneck.
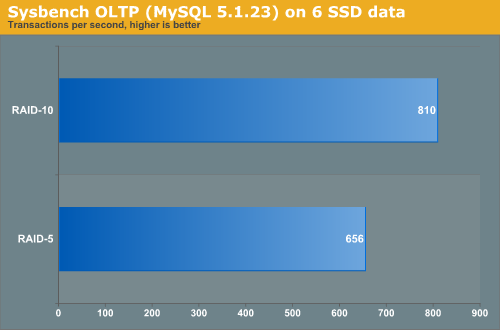
As RAID 10 is about 23% faster than RAID 5, we placed the database on a RAID 10 LUN.
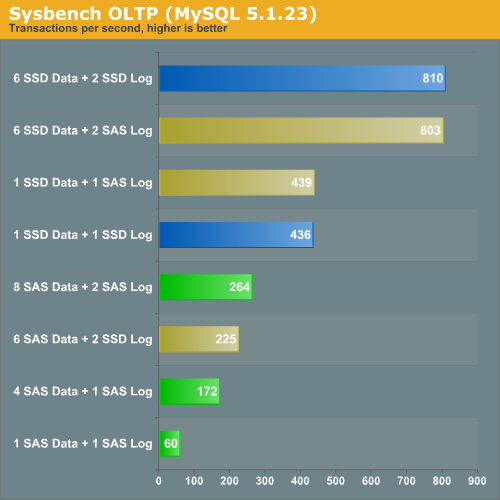
Transactional logs are written in a sequential and synchronous manner. Since SAS disks are capable of delivering very respectable sequential data rates, it is not surprising that replacing the SAS "log disks" with SSDs does not boost performance at all. However, placing your database data files on an Intel X25-E is an excellent strategy. One X25-E is 66% faster than eight (!) 15000RPM SAS drives. That means if you don't need capacity, you can replace about 13 SAS disks with one SSD to get the same performance. You can keep the SAS disks as your log drives as they are a relatively cheap way to obtain good logging performance.








67 Comments
View All Comments
marraco - Wednesday, March 25, 2009 - link
The comparison is not fair, but can be fairer:If the RAID of SATA/SAS disks is restricted to the same storage capacity than the SSD, limiting the partition to the fastest external tracks/cilynders, the latency is significantly reduced, and average read/write speed is significantly increased, so
PLEASE, PLEASE, PLEASE
Repeat the benchmarcks, but with short stroking for magnetic disks.
JohanAnandtech - Friday, March 27, 2009 - link
May I ask what the difference with the fact that we created a relatively small partition across our RAID-5 raidset? Also, you can imagine that our 23 GB database was at the outer tracks of the disks. I have to verify, but that seems logical.This kind of testing should give the same effects as short stroking. I personally think Short stroking can not be good for your actuator, while a small partition should be no problem.
marraco - Friday, March 27, 2009 - link
See this link.http://www.tomshardware.com/reviews/short-stroking...">http://www.tomshardware.com/reviews/short-stroking...
Clearly, you results are orders of magnitude than those showed on that benchmark.
As I understand, short stroking increase actuator health, because reduces physical acceleration on the actuator.
Anything necessary, is to use a small partition on the fastest external track.
you utilized a raid 0 of 16 disks, with less than 1000 gb/second.
On Tomshardware, a raid of only 4 disk achieved average (not maximun) 1400 to 1600 Mb/s. (of course, the test are not the same; for that reason, I ask for new test)
About the RAID 5: I would love to see RAID 0.
I are interesed on comparing a fast SSD as the intels, (or OCZ Vostro/Summit), with what can be achieved at the same cost, with magnetic media, if the partition size is restricted to the same total capacity than the SSD.
Anyway, thanks for the article. Good work.
So good, I want to see more :)
marraco - Sunday, April 5, 2009 - link
Please, tell me you are preparing such article :)JohanAnandtech - Tuesday, April 7, 2009 - link
We are investigating the issue. I like to have some second opinions before I start heavy benchmarking on THG article. They tend to be sensational...araczynski - Wednesday, March 25, 2009 - link
wow, color me impressed. all the more reason to upgrade everything to gigabit and fiber.BailoutBenny - Tuesday, March 24, 2009 - link
Can we get any updates on the future of chalcogenide glass (phase change) based drive technologies? IBM's Millipede and other MEMS probe storage devices? Any word about Intel and STMicroelectronics' shipments of PRAM samples to customers that happened last year? What do the rumor mills say? Are these technologies proving viable? It is difficult to formulate a coherent picture for these technologies without being an industry insider.Black Jacque - Tuesday, March 24, 2009 - link
RAID 5 in Action... However, it is rarely if ever used for any serious application.
You are obviously not a SAN Admin or know too much about enterprise level storage.
RAID 5 is the mainstay of block-level storage systems by companies like EMC.
In addition, the article mentions STEC EFDs used by EMC. On the EMC CLARiiON line, those EFDs are provisioned in RAID 5 groups.
spikespiegal - Wednesday, March 25, 2009 - link
[quote]RAID 5 is the mainstay of block-level storage systems by companies like EMC. [/quote]Which thus explains why in this day in age I see so many SANs blowing entire volumes and costing days of restoration when the room temp gets a few degrees above ambient.
Corrupted RAID 5 arrays have cost me more lost enterprise data than all the non-RAID client side disks I've ever replaced; iSeries, all brands of x386, etc. EMC has a great script to account for this in which they always blame the drives first, then only when cornered by an enraged CIO will they admit it's their controllers. Been there...done that...for over a decade in many different industries.
If you haven't been burned by RAID 5, or dare claim a drive controller in RAID 5 mode has a better MTBF than the drives it's hosting, then it's time to quite your day job at the call center in India. RAID 5 saves you the cost of one drive every four, which was logical in 1998 but not today. At least span across multiple redundant controllers in RAID 10 or something....
JohanAnandtech - Tuesday, March 24, 2009 - link
I fear you misread that sentence:"RAID 0 is good way to see how adding more disks scales up your writing and reading performance. However, it is rarely if ever used for any serious application."
So we are talking about RAID-0 not RAID-5.
http://it.anandtech.com/IT/showdoc.aspx?i=3532&...">http://it.anandtech.com/IT/showdoc.aspx?i=3532&...