Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
OoOE
You’re going to come across the phrase out-of-order execution (OoOE) a lot here, so let’s go through a quick refresher on what that is and why it matters.
At a high level, the role of a CPU is to read instructions from whatever program it’s running, determine what they’re telling the machine to do, execute them and write the result back out to memory.
The program counter within a CPU points to the address in memory of the next instruction to be executed. The CPU’s fetch logic grabs instructions in order. Those instructions are decoded into an internally understood format (a single architectural instruction sometimes decodes into multiple smaller instructions). Once decoded, all necessary operands are fetched from memory (if they’re not already in local registers) and the combination of instruction + operands are issued for execution. The results are committed to memory (registers/cache/DRAM) and it’s on to the next one.
In-order architectures complete this pipeline in order, from start to finish. The obvious problem is that many steps within the pipeline are dependent on having the right operands immediately available. For a number of reasons, this isn’t always possible. Operands could depend on other earlier instructions that may not have finished executing, or they might be located in main memory - hundreds of cycles away from the CPU. In these cases, a bubble is inserted into the processor’s pipeline and the machine’s overall efficiency drops as no work is being done until those operands are available.
Out-of-order architectures attempt to fix this problem by allowing independent instructions to execute ahead of others that are stalled waiting for data. In both cases instructions are fetched and retired in-order, but in an OoO architecture instructions can be executed out-of-order to improve overall utilization of execution resources.
The move to an OoO paradigm generally comes with penalties to die area and power consumption, which is one reason the earliest mobile CPU architectures were in-order designs. The ARM11, ARM’s Cortex A8, Intel’s original Atom (Bonnell) and Qualcomm’s Scorpion core were all in-order. As performance demands continued to go up and with new, smaller/lower power transistors, all of the players here started introducing OoO variants of their architectures. Although often referred to as out of order designs, ARM’s Cortex A9 and Qualcomm’s Krait 200/300 are mildly OoO compared to Cortex A15. Intel’s Silvermont joins the ranks of the Cortex A15 as a fully out of order design by modern day standards. The move to OoO alone should be good for around a 30% increase in single threaded performance vs. Bonnell.
Pipeline
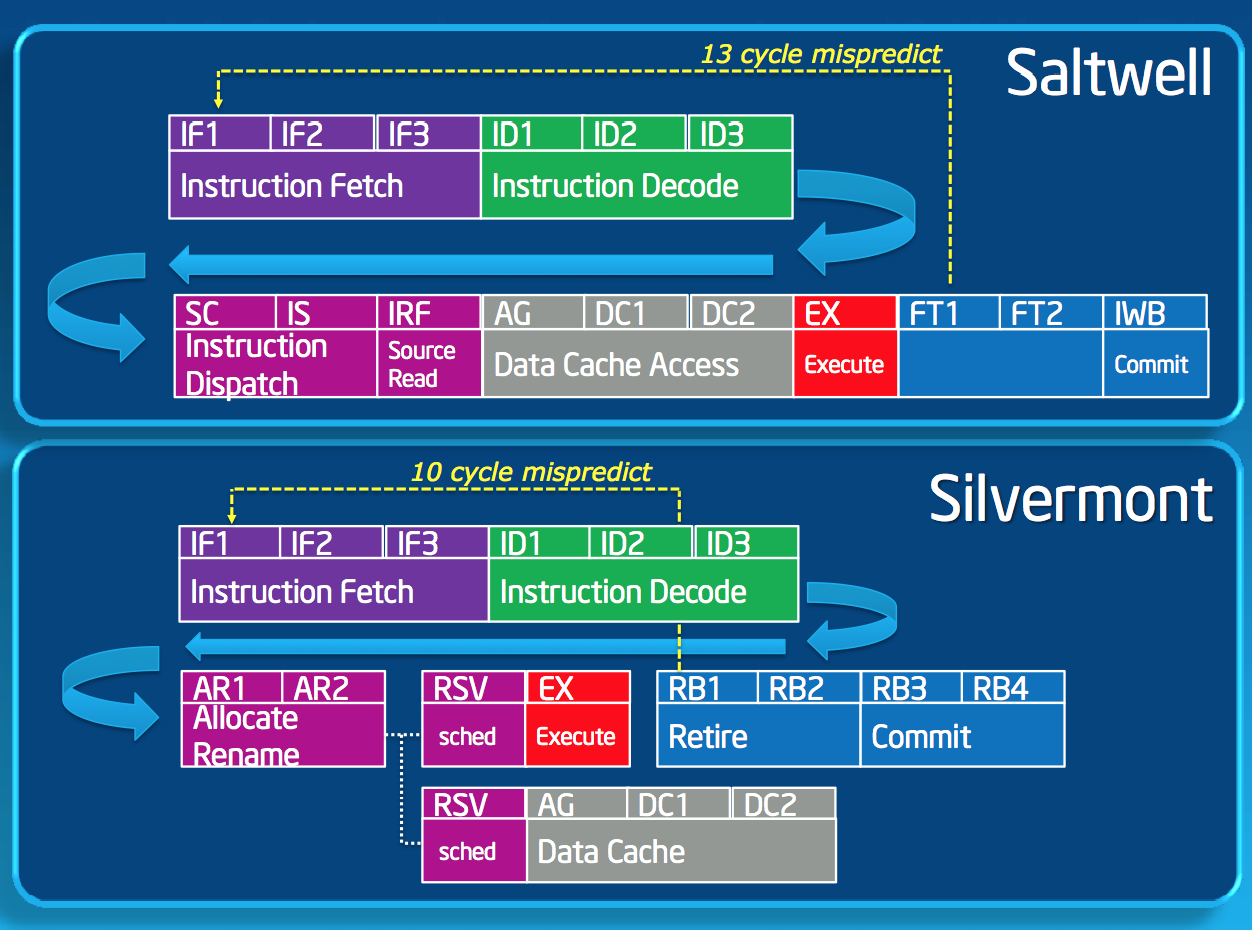
Silvermont changes the Atom pipeline slightly. Bonnell featured a 16 stage in-order pipeline. One side effect to the design was that all operations, including those that didn’t have cache accesses (e.g. operations whose operands were in registers), had to go through three data cache access stages even though nothing happened during those stages. In going out-of-order, Silvermont allows instructions to bypass those stages if they don’t need data from memory, effectively shortening the mispredict penalty from 13 stages down to 10. The integer pipeline depth now varies depending on the type of instruction, but you’re looking at a range of 14 - 17 stages.
Branch prediction improves tremendously with Silvermont, a staple of any progressive microprocessor architecture. Silvermont takes the gshare branch predictor of Bonnell and significantly increased the size of all associated data structures. Silvermont also added an indirect branch predictor. The combination of the larger predictors and the new indirect predictor should increase branch prediction accuracy.
Couple better branch prediction with a lower mispredict latency and you’re talking about another 5 - 10% increase in IPC over Bonnell.








174 Comments
View All Comments
MelodyRamos47 - Sunday, May 12, 2013 - link
If you think Emma`s story is super..., a month back father in-law also earned $6677 putting in from there apartment and their roomate's step-sister`s neighbour has done this for 6 months and easily made more than $6677 in their spare time from a labtop. applie the information on this link, Bow6.comCHECK IT OUTsamda - Monday, May 13, 2013 - link
I signed up here just to post this and show just how objective Anand really is."It will be insane if Silvermont reaches the 2010 MacBook Air "
Well what a load of biased ignorance.
Mr. Anand, you might want to read this and learn a bit:
http://browser.primatelabs.com/geekbench2/1946978
http://browser.primatelabs.com/geekbench2/1947269
Galaxy S4 ALREADY being there, heck even beating it easily!
Can you imagine what will a 2Ghz Octa do?
With this kind of memory? http://m.androidauthority.com/samsung-lpddr3-ram-2...
How about Snapdragon 800?
But yeah, it seems someone is being too busy sucking on Intel and living in the past!
etre - Monday, May 13, 2013 - link
Still Intel is not really trying on this market. They moved up from a 2008 design to a 2010 design on a last year process. And it took them 5 years to do that.They should have offered Haswell kind of tech, with the improvements on memory, this summer, at a killer price.
Why should I support Intel by buying an Asus Phonepad, on a promise that they will bring something sometime, instead of going for a sure bet with the new Nexus 7 and quad core Krait.
CodyCostaRica - Monday, May 20, 2013 - link
Anand,Thanks so much for this article. I would be highly interested in knowing how Intel's current and future chip road maps stack up against the competitors' current and future offerings in the mobile space (Qualcomm, NVIDIA, Samsung, Apple).
For example, how does Silvermont compare to the Apple A6X, currently used in the latest iPad?
Keep up the good work!