Apple's Cyclone Microarchitecture Detailed
by Anand Lal Shimpi on March 31, 2014 2:10 AM EST
The most challenging part of last year's iPhone 5s review was piecing together details about Apple's A7 without any internal Apple assistance. I had less than a week to turn the review around and limited access to tools (much less time to develop them on my own) to figure out what Apple had done to double CPU performance without scaling frequency. The end result was an (incorrect) assumption that Apple had simply evolved its first ARMv7 architecture (codename: Swift). Based on the limited information I had at the time I assumed Apple simply addressed some low hanging fruit (e.g. memory access latency) in building Cyclone, its first 64-bit ARMv8 core. By the time the iPad Air review rolled around, I had more knowledge of what was underneath the hood:
As far as I can tell, peak issue width of Cyclone is 6 instructions. That’s at least 2x the width of Swift and Krait, and at best more than 3x the width depending on instruction mix. Limitations on co-issuing FP and integer math have also been lifted as you can run up to four integer adds and two FP adds in parallel. You can also perform up to two loads or stores per clock.
With Swift, I had the luxury of Apple committing LLVM changes that not only gave me the code name but also confirmed the size of the machine (3-wide OoO core, 2 ALUs, 1 load/store unit). With Cyclone however, Apple held off on any public commits. Figuring out the codename and its architecture required a lot of digging.
Last week, the same reader who pointed me at the Swift details let me know that Apple revealed Cyclone microarchitectural details in LLVM commits made a few days ago (thanks again R!). Although I empirically verified many of Cyclone's features in advance of the iPad Air review last year, today we have some more concrete information on what Apple's first 64-bit ARMv8 architecture looks like.
Note that everything below is based on Apple's LLVM commits (and confirmed by my own testing where possible).
| Apple Custom CPU Core Comparison | ||||||
| Apple A6 | Apple A7 | |||||
| CPU Codename | Swift | Cyclone | ||||
| ARM ISA | ARMv7-A (32-bit) | ARMv8-A (32/64-bit) | ||||
| Issue Width | 3 micro-ops | 6 micro-ops | ||||
| Reorder Buffer Size | 45 micro-ops | 192 micro-ops | ||||
| Branch Mispredict Penalty | 14 cycles | 16 cycles (14 - 19) | ||||
| Integer ALUs | 2 | 4 | ||||
| Load/Store Units | 1 | 2 | ||||
| Load Latency | 3 cycles | 4 cycles | ||||
| Branch Units | 1 | 2 | ||||
| Indirect Branch Units | 0 | 1 | ||||
| FP/NEON ALUs | ? | 3 | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 64KB I$ + 64KB D$ | ||||
| L2 Cache | 1MB | 1MB | ||||
| L3 Cache | - | 4MB | ||||
As I mentioned in the iPad Air review, Cyclone is a wide machine. It can decode, issue, execute and retire up to 6 instructions/micro-ops per clock. I verified this during my iPad Air review by executing four integer adds and two FP adds in parallel. The same test on Swift actually yields fewer than 3 concurrent operations, likely because of an inability to issue to all integer and FP pipes in parallel. Similar limits exist with Krait.
I also noted an increase in overall machine size in my initial tinkering with Cyclone. Apple's LLVM commits indicate a massive 192 entry reorder buffer (coincidentally the same size as Haswell's ROB). Mispredict penalty goes up slightly compared to Swift, but Apple does present a range of values (14 - 19 cycles). This also happens to be the same range as Sandy Bridge and later Intel Core architectures (including Haswell). Given how much larger Cyclone is, a doubling of L1 cache sizes makes a lot of sense.
On the execution side Cyclone doubles the number of integer ALUs, load/store units and branch units. Cyclone also adds a unit for indirect branches and at least one more FP pipe. Cyclone can sustain three FP operations in parallel (including 3 FP/NEON adds). The third FP/NEON pipe is used for div and sqrt operations, the machine can only execute two FP/NEON muls in parallel.
I also found references to buffer sizes for each unit, which I'm assuming are the number of micro-ops that feed each unit. I don't believe Cyclone has a unified scheduler ahead of all of its execution units and instead has statically partitioned buffers in front of each port. I've put all of this information into the crude diagram below:
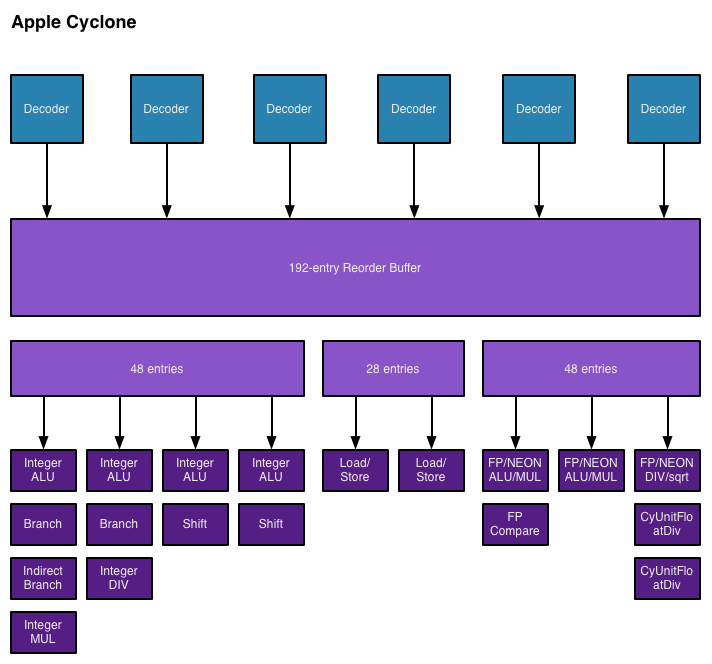
Unfortunately I don't have enough data on Swift to really produce a decent comparison image. With six decoders and nine ports to execution units, Cyclone is big. As I mentioned before, it's bigger than anything else that goes in a phone. Apple didn't build a Krait/Silvermont competitor, it built something much closer to Intel's big cores. At the launch of the iPhone 5s, Apple referred to the A7 as being "desktop class" - it turns out that wasn't an exaggeration.
Cyclone is a bold move by Apple, but not one that is without its challenges. I still find that there are almost no applications on iOS that really take advantage of the CPU power underneath the hood. More than anything Apple needs first party software that really demonstrates what's possible. The challenge is that at full tilt a pair of Cyclone cores can consume quite a bit of power. So for now, Cyclone's performance is really used to exploit race to sleep and get the device into a low power state as quickly as possible. The other problem I see is that although Cyclone is incredibly forward looking, it launched in devices with only 1GB of RAM. It's very likely that you'll run into memory limits before you hit CPU performance limits if you plan on keeping your device for a long time.

It wasn't until I wrote this piece that Apple's codenames started to make sense. Swift was quick, but Cyclone really does stir everything up. The earlier than expected introduction of a consumer 64-bit ARMv8 SoC caught pretty much everyone off guard (e.g. Qualcomm's shift to vanilla ARM cores for more of its product stack).
The real question is where does Apple go from here? By now we know to expect an "A8" branded Apple SoC in the iPhone 6 and iPad Air successors later this year. There's little benefit in going substantially wider than Cyclone, but there's still a ton of room to improve performance. One obvious example would be through frequency scaling. Cyclone is clocked very conservatively (1.3GHz in the 5s/iPad mini with Retina Display and 1.4GHz in the iPad Air), assuming Apple moves to a 20nm process later this year it should be possible to get some performance by increasing clock speed scaling without a power penalty. I suspect Apple has more tricks up its sleeve than that however. Swift and Cyclone were two tocks in a row by Intel's definition, a third in 3 years would be unusual but not impossible (Intel sort of committed to doing the same with Saltwell/Silvermont/Airmont in 2012 - 2014).
Looking at Cyclone makes one thing very clear: the rest of the players in the ultra mobile CPU space didn't aim high enough. I wonder what happens next round.








182 Comments
View All Comments
Khato - Monday, March 31, 2014 - link
Here's a hint - Intel's fab advantage is always shrinking according to the foundry PR. When has TSMC or Global Foundries or all the rest not promised a narrowing of the gap? Why precisely is this latest round of reactionary roadmaps going to be any different?Want a sampling of how TSMC's 20nm is actually going thus far? Because we've actually had the first indicator for awhile now, namely that Xilinx announced shipment of their first 20nm FPGA back in November of 2013 - http://press.xilinx.com/2013-11-11-Xilinx-Ships-In... Now compare that to TSMC's 28nm process where Xiling announced shipment of their first 28nm FPGA in March of 2011 - http://press.xilinx.com/2011-03-18-Xilinx-Ships-Wo... - which was what, 9 months before consumer products started showing up? Either way it's a pretty clear indication that TSMC is on track for at least a 2.5 year gap between 28nm and 20nm... which is, at best, maintaining the gap with Intel.
Then, of course, there's still the matter of FinFET implementation. We'll have to wait and see whether or not they actually deliver on that promise. After all, recall when FinFET went on TSMC's roadmap? Not to mention everyone else's? Yeah, that's right, pretty much immediately after Intel's 22nm announcement. Same thing happened with TSMC's '16nm FF+' creation - another roadmap response to Intel with very little evidence that it's anything more than a PR move.
iollmann - Monday, March 31, 2014 - link
Given that the size of an atom is about 0.3 nm, it seems unlikely to me that anyone's fab advantage can last too much longer. Eventually you hit the wall, and other factors such as quality of software take over.Kidster3001 - Monday, April 7, 2014 - link
Intel's fab advantage is, in fact, growing every year. TSMC won't have workable 16 nm finfet "that you can buy" for about 3 years. They are falling further behind every year.WaltFrench - Monday, March 31, 2014 - link
As of today, there are very few design wins where there was any question about whether an X86 or ARM architecture would be <b>considered.</b> Right now, the architectures have very separate ecosystems around them; with over half of all ARM chips going to low-power, extremely price-sensitive handset sales, Intel isn't even bothering to try. Soon, they may need to better protect the low end of their X86 business as ARM chips become competitive in Intel's current domain. But that'd inevitably mean lower profitability that I don't think they're ready to cede.iollmann - Tuesday, April 1, 2014 - link
Classic innovators dilemma. Intel has some fabulous marketing / business strategy people, but even so, the days of printing money from sand at high margin look numbered.OreoCookie - Monday, March 31, 2014 - link
Since this is Apple's own CPU, how is Windows support relevant? Apple could offer a version of OS X on ARM (I'm certain they have something like that in the lab), but I don't see any pressure for Apple to move their laptops to ARM cpus. Right now, there is not that much pressure to move away from Intel cpus (my new Retina MacBook Pro lasts a complete transatlantic flight and then some/a whole workday on battery).Even though in principle you're right that ARM's efficiency advantage becomes smaller and smaller, two other advantages remain: (1) Apple could develop everything on its own schedule and (2) its own CPUs are cheaper (because the in-house CPU team doesn't have to make any money). And it seems that Intel has hit some snags with its cpu development. So I think this may be something Apple would consider doing in 5 years or so.
Kevin G - Monday, March 31, 2014 - link
Intel's fab advantage has stalled and allowing others to catch up a bit. 14 nm has been delayed till the end of 2014 with part of the first wave arriving in 2015. The move to 10 nm looks to be brutal for all involved and Intel themselves isn't sure of 7 nm mass production viability (they do have prototypes).In the midst of these last few shrinks, there is going to be a move to 450 mm wafers. This too has been delayed by Intel. Though no fab seemingly wants to be first here as it requires reworking of production lines with expensive new equipment that'd cost billions to upgrade.
The one manufacturing advantage Intel does have is means of mixing analog and digital circuits. This is mainly for the analog side of a radio though in the mobile market this is critical. Intel still has some interesting packaging technologies ( http://www.anandtech.com/show/834/5 ) that have yet to be used in mass production. Lastly, Intel has made several advancements in terms of silicon photonics. Silicon photonics is the next big thing (tm) in the server market as it'll enable greater socket scaling. Depending on power consumption, silicon photonics has been suggested as a means to link high resolution displays directly to a GPU and this would have mobile applications.
a
I am surprised that Intel hasn't used their process and packaging advantages to innovate past the competition. For example, they manufacturer their own eDRAM for usage with Iris Pro graphics. Not only does this increase performance but it also saves power. So why not extend this to a phone SoC and use it to replace the low power DRAM? Reducing the complexity of the memory controller can be done as Intel would design both the controller and the memory, saving a bit of power here too.
Guspaz - Monday, March 31, 2014 - link
"Plus, who will port all of the Wintel software to ARM?"Why would you need to, if you're talking about a Mac running OS X? Apple has shifted architectures numerous times in the past, and each time the transition was pretty smooth. In fact, they did their first architecture shift from 68k to PPC without even porting most of the OS, they just built kernel-level emulation support into Mac OS and let it handle all the 68k code until they finished that port. Later, when they did the shift from PPC to x86, they used a userspace emulator, and that transition didn't even take as long.
If Apple wanted to do another transition, from x86 to ARM (and I'm not convinced that they do), there's no reason why they couldn't do so again. They control the entire hardware and software stack, and are even in the position of making architectural tweaks to their processor to facilitate x86 emulation if they need to.
cbmuir - Monday, March 31, 2014 - link
Except in those two earlier architecture changes, which I agree were preternaturally smooth, the new architecture was considerably faster than the previous one, so that the penalty of using an emulator didn't hurt so much. I don't see ARM getting ahead of intel like this.WaltFrench - Monday, March 31, 2014 - link
Agreed. But the advantage this go 'round *would be* (nb: hypothetical) that a large fraction of their code goes thru a single development environment that Apple controls, and that already spits out ARM/X86 variants.Apple is *almost* in the position where developers wouldn't even have to know or care what the actual instruction set was for ANY of their devices; block diagrams such as Anand has guessed at above, plus the LLVM pseudo-assembly would be good enough. Already there, AFAICT, for iOS.