The Next Generation Open Compute Hardware: Tried and Tested
by Johan De Gelas & Wannes De Smet on April 28, 2015 12:00 PM EST
Four years ago we reviewed Facebook's self-designed and open source server, Freedom. Coinciding with releasing their datacenter design, they founded the Open Compute Foundation, creating a home for the design documents, licenses and bringing vendors together under one roof.
Today, the Open Compute Foundation is doing well. Many high profile companies such as Yandex, IBM and Intel are members, and in 2014 Microsoft joined the initiative as a second major open hardware partner; releasing its Open Cloud Server designs to a pool of open hardware spanning everything from servers and switches to datacenters. The international community has grown substantially, with Summits in all major continents attracting a larger crowd each time. More so, the number of companies adopting hardware from OCP and contributing back is rising as well, and with good reason: Mark Zuckerberg indicated at the 2015 Summit in San Diego that Facebook achieved a $2 billion (USD) cost reduction (!), achieved in part by using open purpose-built hardware instead of regular proprietary gear.
To Follow and Like, at Scale
When Facebook talks about the incredible amounts of money it has saved by using Open Compute, keep in mind that even though the vanity-free hardware is designed to be cost-effective, it's the actual software that enables hardware efficiency. The company has always sought to use commonly available software components to build its services, and when it picked one, plenty of time and money are spent on performance engineering to optimize the software. Performance engineering that enables Facebook to handle 6 billion likes, 930 million photos and 12 billion messages every day, and those numbers only represent activity its social network product generates; Instagram and WhatsApp are not exactly toy workloads either.
Facebook has carried out plenty of improvements in open-source projects, or started new implementations, most of them contributed back to the community, good karma indeed. Notable performance-related projects are HHVM -- short for HipHop VM, a JIT'ing PHP virtual machine with its own PHP language dialect called Hack, adding static typing in the mix. HHVM is advertised as 'a more predictable PHP', and if Wikipedia's migration serves as any indication it makes existing PHP powered sites quite a bit faster as well. Another initiative called rocksdb, implements a properly scaleable, persistent key-value store for fast storage written in C++ and presto, a distributed SQL engine for Big Data stored in common storage systems like Cassandra, JDBC DBs and HDFS. Presto provides functionality similar to Hive, and is currently in use at Dropbox and Airbnb.
Scale Your Devops
A (dev)ops engineer at Facebook can request any kind of hardware configuration he likes, as long it is one of the following five:
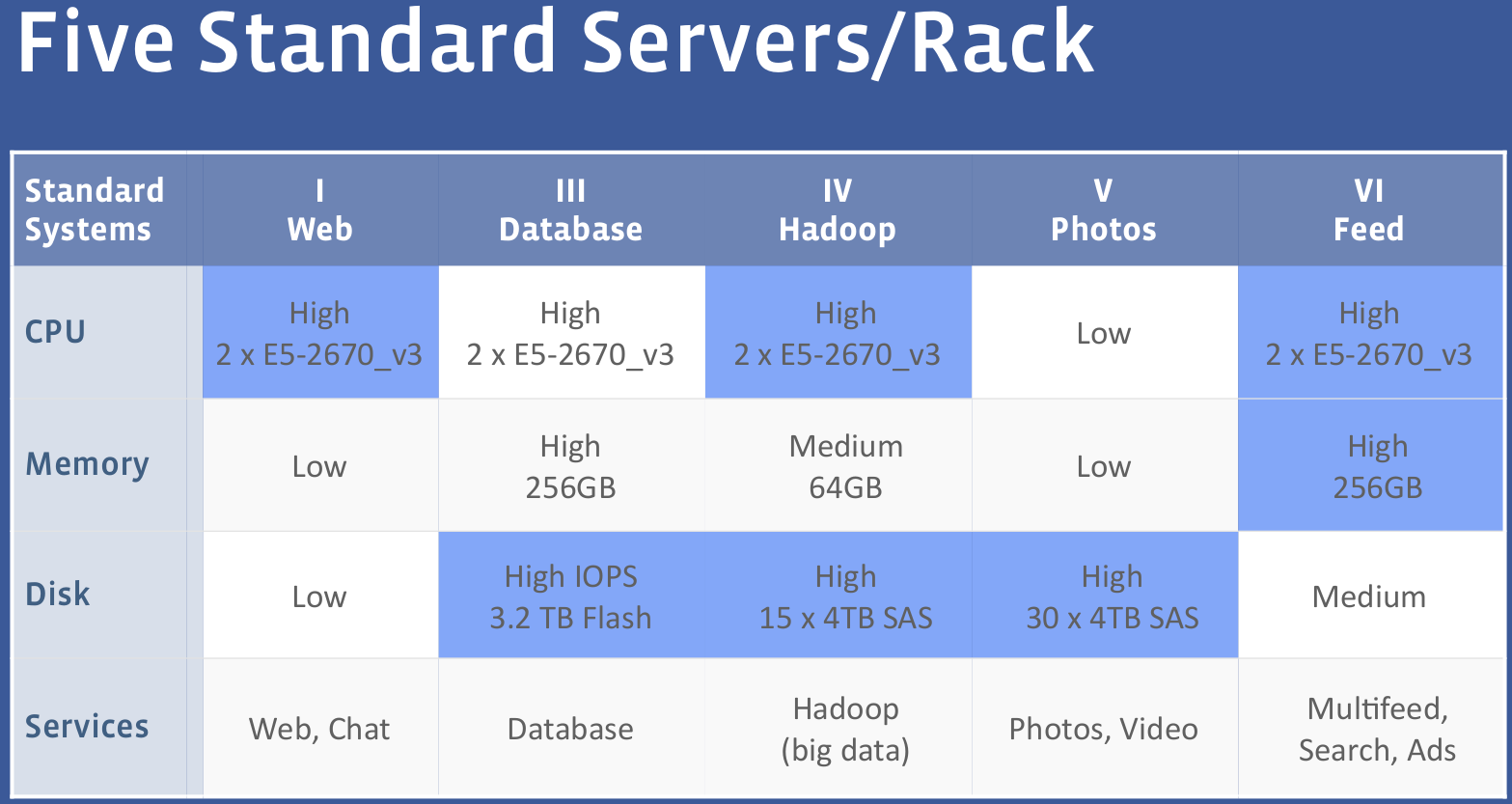
Increasing the number of parts used in your systems exponentially increases the amount of money and time that will be spent in procuring, validation and maintenance. And keep in mind that in order to avoid vendor lock-in, each configuration must be available from at least two suppliers, so it's easy to imagine why FB prefers to keep it simple when it comes to servers: 5 SKUs using the same base platform, each targeted at a certain kind of application.
The SKUs mentioned are variations on Facebook's latest Xeon E5 server platform, Leopard, reviewed in detail in this article. The web tier is concerned with gathering every piece of information from the entire stack and rendering it to HTML/JSON, for which it needs a decent CPU, but not much else. Object storage, like photos is quite the opposite, and requires just a simple CPU (Atom C2000) to serve object from a large storage backend. At the other end of the spectrum, you have the data crunching units that require a decent chunk of processing power, memory capacity and I/O.








26 Comments
View All Comments
Kevin G - Tuesday, April 28, 2015 - link
Excellent article.The efficiency gains are apparent even using suboptimal PSU for benchmarking. (Though there are repeated concurrency values in the benchmarking tables. Is this intentional?)
I'm looking forward to seeing a more compute node hardware based around Xeon-D, ARM and potentially even POWER8 if we're lucky. Options are never a bad thing.
Kind of odd to see the Knox mass storage units, I would have thought that OCP storage would have gone the BackBlaze route with vertically mount disks for easier hot swap, density and cooling. All they'd need to develop would have been a proprietary backplane to handle the Kinetic disks from Seagate. Basic switching logic could also be put on the backplane so the only external networking would be high speed uplinks (40 Gbit QSFP+?).
Speaking of the Kinetic disks, how is redundancy handled with a network facing drive? Does it get replicated by the host generating the data to multiple network disks for a virtual RAID1 redundancy? Is there an aggregator that handles data replication, scrubbing, drive restoration and distribution, sort of like a poor man's SAN controller? Also do the Kinetic drives have two Ethernet interfaces to emulate multi-pathing in the event of a switch failure (quick Googling didn't give me an answer either way)?
The cold storage racks using Blu-ray discs in cartridges doesn't surprise me for archiving. The issue I'm puzzled with is the process how data gets moved to them. I've been under the impression that there was never enough write throughput to make migration meaningful. For a hypothetical example, by the time 20 TB of data has been written to the discs, over 20 TB has been generated that'd be added to the write queue. Essentially big data was too big to archive to disc or tape. Parallelism here would solve the throughput problem but that get expensive and takes more space in the data center that could be used for hot storage and compute.
Do the Knox storage and Wedge networking hardware use the same PDU connectivity as the compute units?
Are the 600 mm wide racks compatible use US Telecom rack width equipment (23" wide)? A few large OEMs offer equipment in that form factor and it'd be nice for a smaller company to mix and match hardware with OCP to suit their needs.
nils_ - Wednesday, April 29, 2015 - link
You can use something like Ceph or HDFS for data redundancy which is kind of like RAID over network.davegraham - Tuesday, April 28, 2015 - link
Also, Juniper Networks has an ONIE-compliant OCP switch called the OCX1100 which is the only Tier1 switch manufacturer (e.g. Cisco, Arista, Brocade) to provide such a device.floobit - Tuesday, April 28, 2015 - link
This is very nice work. One of the best articles I've seen here all year. I think this points at the future state of server computing, but I really wonder if the more traditional datacenter model (VMware on beefy blades with a proprietary FC-connected SAN) can be integrated with this massively-distributed webapp model. Load-balancing and failovering is presumably done in the app layer, removing the need for hypervisors. As pretty as Oracle's recent marketing materials are, I'm pretty sure they don't have an HR app that can be load-balanced on the app layer in alongside an expense app and an ERP app. Maybe in another 10 years. Then again, I have started to see business suites where they host the whole thing for you, and this could be a model for their underlying infrastructure.ggathagan - Tuesday, April 28, 2015 - link
In the original article on these servers, it was stated that the PSU's were run on 277v, as opposed to 208v.277v involves three phase power wiring, which is common in commercial buildings, but usually restricted to HVAC-related equipment and lighting.
That article stated that Facebook saved "about 3-4% of energy use, a result of lower power losses in the transmission lines."
If the OpenRack carries that design over, companies will have to add the cost of bringing power 277v to the rack in order to realize that gain in efficiency.
sor - Wednesday, April 29, 2015 - link
208 is 3 phase as well, generally 3x120v phases, with 208 tapping between phases or 120 available to neutral. Its very common for DC equipment. 277 to the rack IS less common, but you seemed to get hung up on the 3 phase part.Casper42 - Monday, May 4, 2015 - link
3 phase restricted to HVAC?Thats ridiculous, I see 3 Phase in DataCenters all the time.
And Server vendors are now selling 277vAC PSUs for exactly this reason that FB mentions. Instead of converting the 480v main to 220 or 208, you just take a 277 feed right off the 3 phase and use it.
clehene - Tuesday, April 28, 2015 - link
You mention a reported $2 Billion in savings, but the article you refer to states $1.2 Billion.FlushedBubblyJock - Tuesday, April 28, 2015 - link
One is the truth and the other is "NON Generally Accepted Accounting Procedures" aka it's lying equivalent.wannes - Wednesday, April 29, 2015 - link
Link corrected. Thanks!