Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
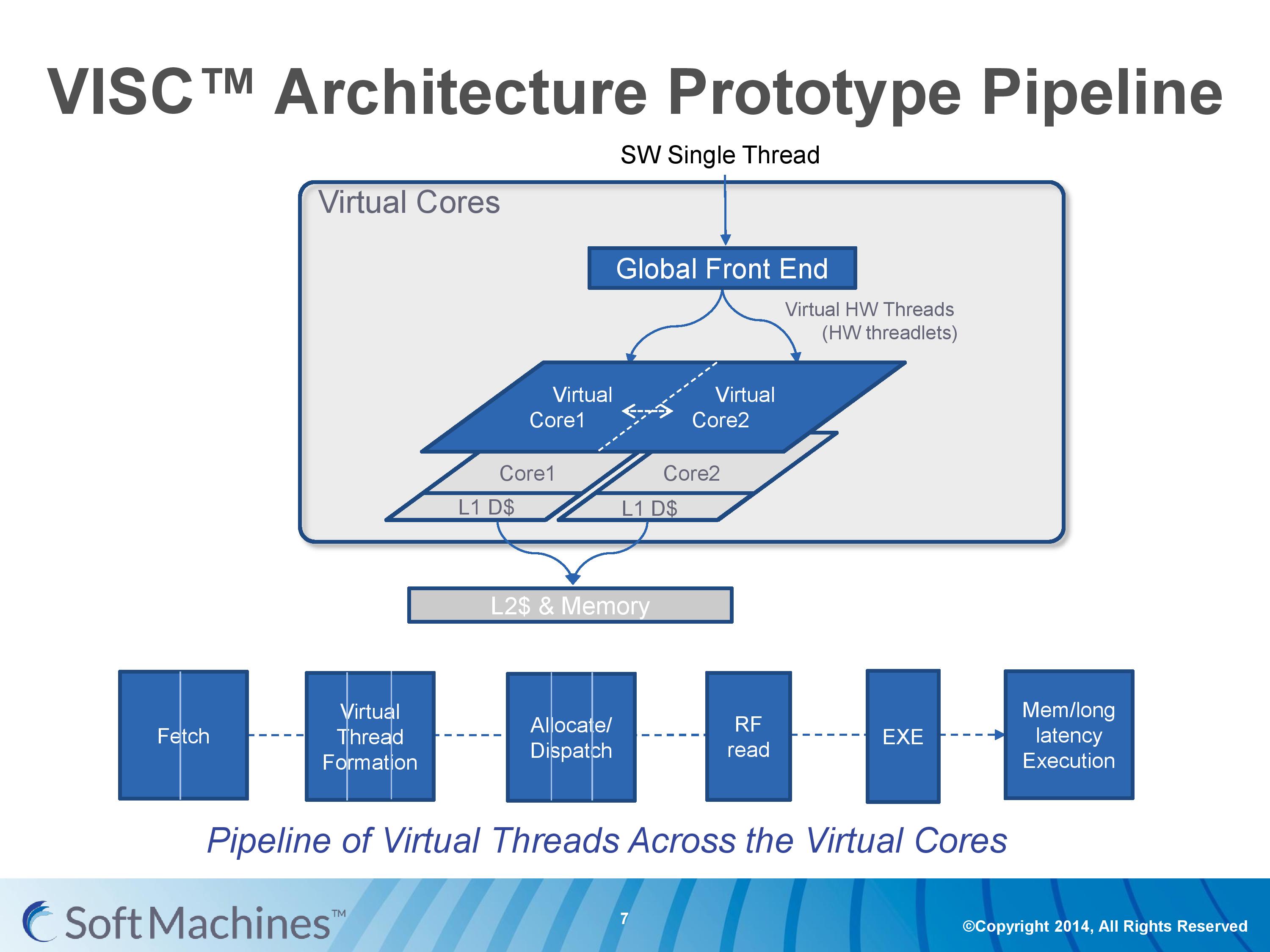
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
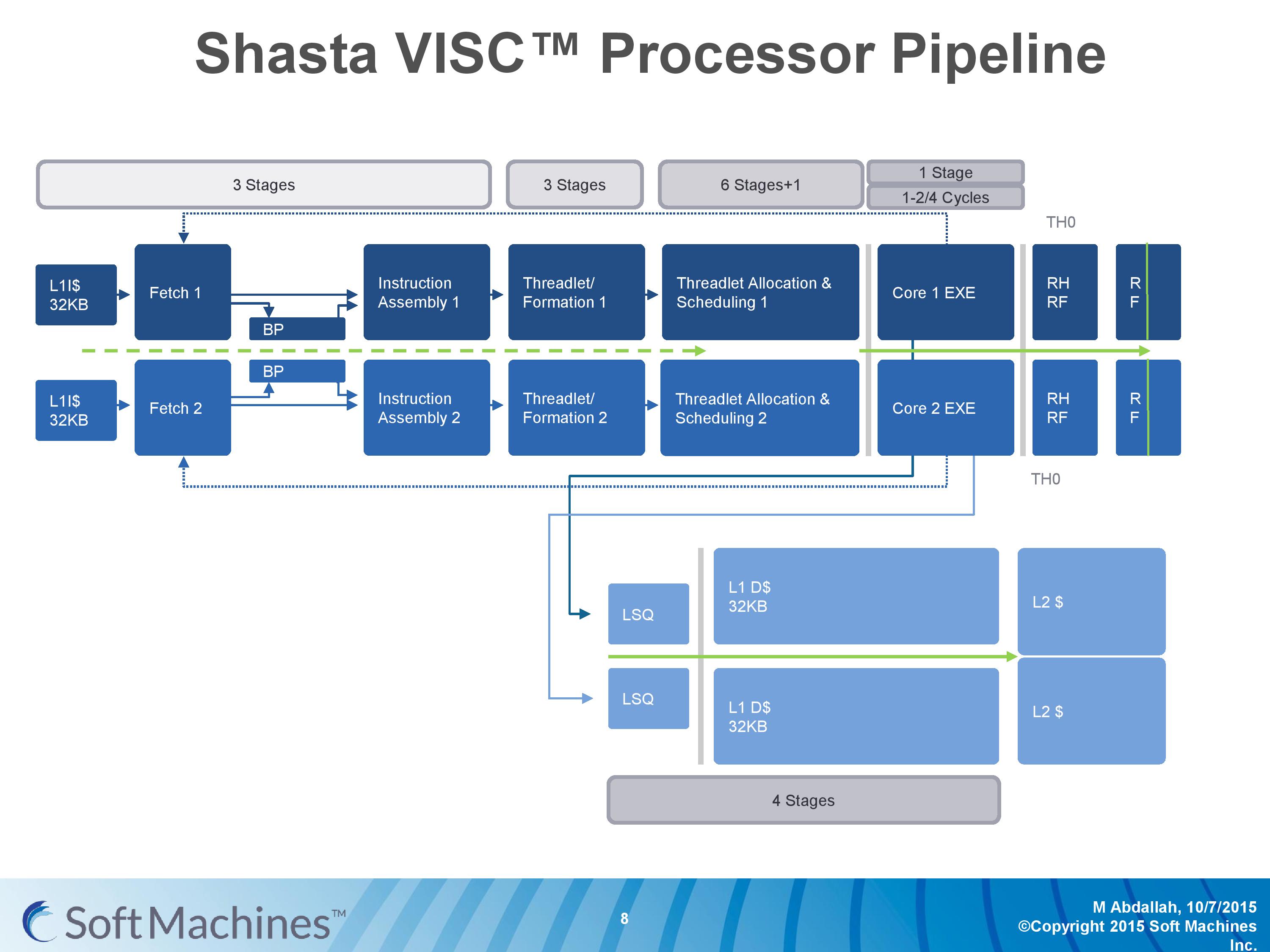
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
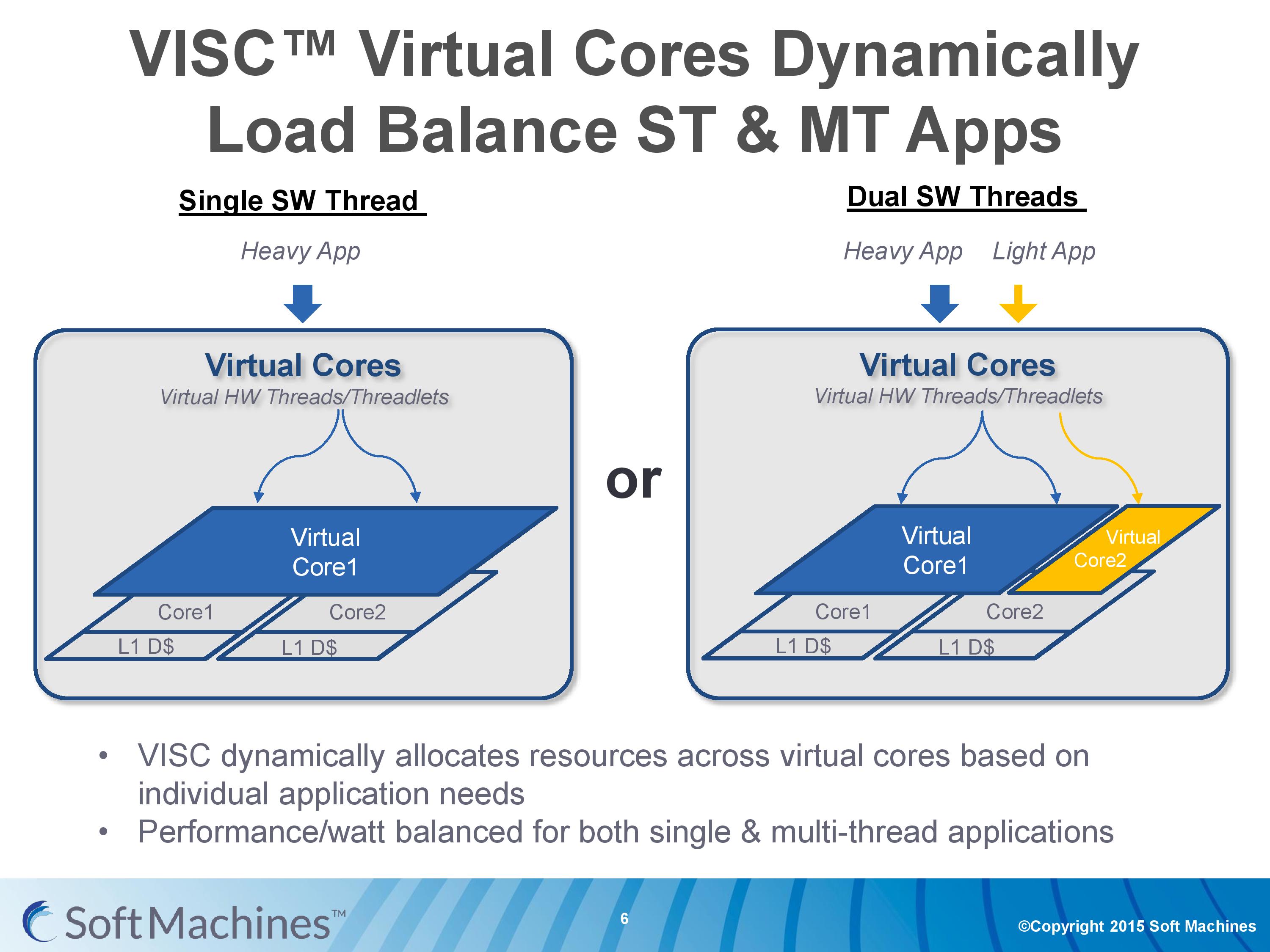
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
Bleakwise - Tuesday, March 14, 2017 - link
I mean IBM does this with the POWER8 very successfully.Bleakwise - Tuesday, March 14, 2017 - link
If you would like to know how an Superscaler CPU can beat an in-order CPU....https://en.wikipedia.org/wiki/Instruction-level_pa...
https://en.wikipedia.org/wiki/Superscalar_processo...
https://en.wikipedia.org/wiki/Instruction-level_pa...
So a Processor with 6 pipelines can do
1*2*3*4*5*6 in one instructoin
a processor with 12 piplines can do
1*2*3*4*5*6*7*8*9*10*11*12
in one clock cycle
This is the opposite of hyper threading, which allows my 4770k with 5 pipelines to do
1*2*3*4*5
or
1*2*3 and 4*5
or
1*2 and 3*4*5
all in one clock cycle.
jjj - Friday, February 12, 2016 - link
What they do with A72 in their slides is a huge red flag. They clock it above 3GHz on 16ff to make it look bad. When you don't need to distort the truth why do it? Was excited about them but they lost all credibility with this.vs ARM it will be hard for them ,assuming ARM will have yearly updates and a broader range of cores. Area will also matter a lot Ofc vs ARM the proper math when it comes to perf, power, thermal and area would be to include dark silicon. ARM is at 8-10 cores in 2-3 clusters but we might see even more than that (i would add a gaming cluster, as GPU perf is a rather complicated problem right now).
Hope we do get to see them in commercial products and i wonder about their longer term plans. Would be interesting if they would aim for a lot more cores at very low power and even cooler if they would aim to use different types of cores - as undoable as all that might be lol. For glasses we need a huge step forward that process and packaging might fail to enable soon enough and even server might find such a path preferable. Would love to see 1T 32PC at 50-100mW on 5nm. Or ,to just go crazy, would be great if they could reach low enough power (thermal) to stack logic and go monolithic 3D since folks are not quite able to do that , for now.
Guess , it would be great if you could ask them how far they think they can push with the number of cores in a thread.
gamerk2 - Friday, February 12, 2016 - link
Odds are, Soft Machines gets acquired by Intel (who want a low-power core for mobile. And hey, ARM support to eliminate the lack of mobile X86 software to boot) or NVIDIA (who want a CPU core, and hey, already have ARM based tablets. X86 support is a bonus an could allow full NVIDIA branded PCs).jjj - Friday, February 12, 2016 - link
It would be easier for Intel or ARM to just copy. Additionally, a sale to Intel would be difficult with Samsung and AMD as investors in SM.fiodhkf - Friday, February 12, 2016 - link
I don't understand these results. How are skylake specint and spefp scores so low? On spec.org the weakest skylake part I could quickly find is Celeron G3900 at 2.8 GHz and 2MB L3 (and huge power consumption, but let's ignore that for now). It has CINT2006 of ~45 and CFP2006 of ~61. Can i5-6200U be that much slower?extide - Friday, February 12, 2016 - link
Because those are NOT the results of a skylake chip, those are their adjusted results of a chip that is equivalent to skylake, but with 1MB L2, no L3, and made on TSMC's 16nmFF+, which is a chip that will NEVER exist in the wild and is POINTLESS to compare to as these guys will never be competing against a made up chip, only the actual stuff released by Intel, and other people.fiodhkf - Friday, February 12, 2016 - link
In the second Performance/Watt comparisonfigure the blue curve is supposed to(?) show the true unscaled-for-cache skylake (power is probably scaled to TSMC 16nmFF+, but surely they're not scaling the performance as well). Even there the skylake spec scores are only about half of what they should be according to results on spec.org.Exophase - Friday, February 12, 2016 - link
The spec.org scores are using ICC, which has optimizations that game a few SPEC2006 subtests like crazy. They also apply auto-par and pointer compression optimizations that aren't applied in GCC. There's also some extra optimizations for peak if you're looking at that but it doesn't make a huge difference in the overall score.All of this adds up to big differences in SPEC score.
fiodhkf - Friday, February 12, 2016 - link
Thanks, that was pretty much what I guessed would be one explanation for the difference. Still, I'm a bit surprised with the low skylake scores even when compared to some (old) AMD processors where spec.org scores used open64. But I don't care quite enough to try myself.