Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
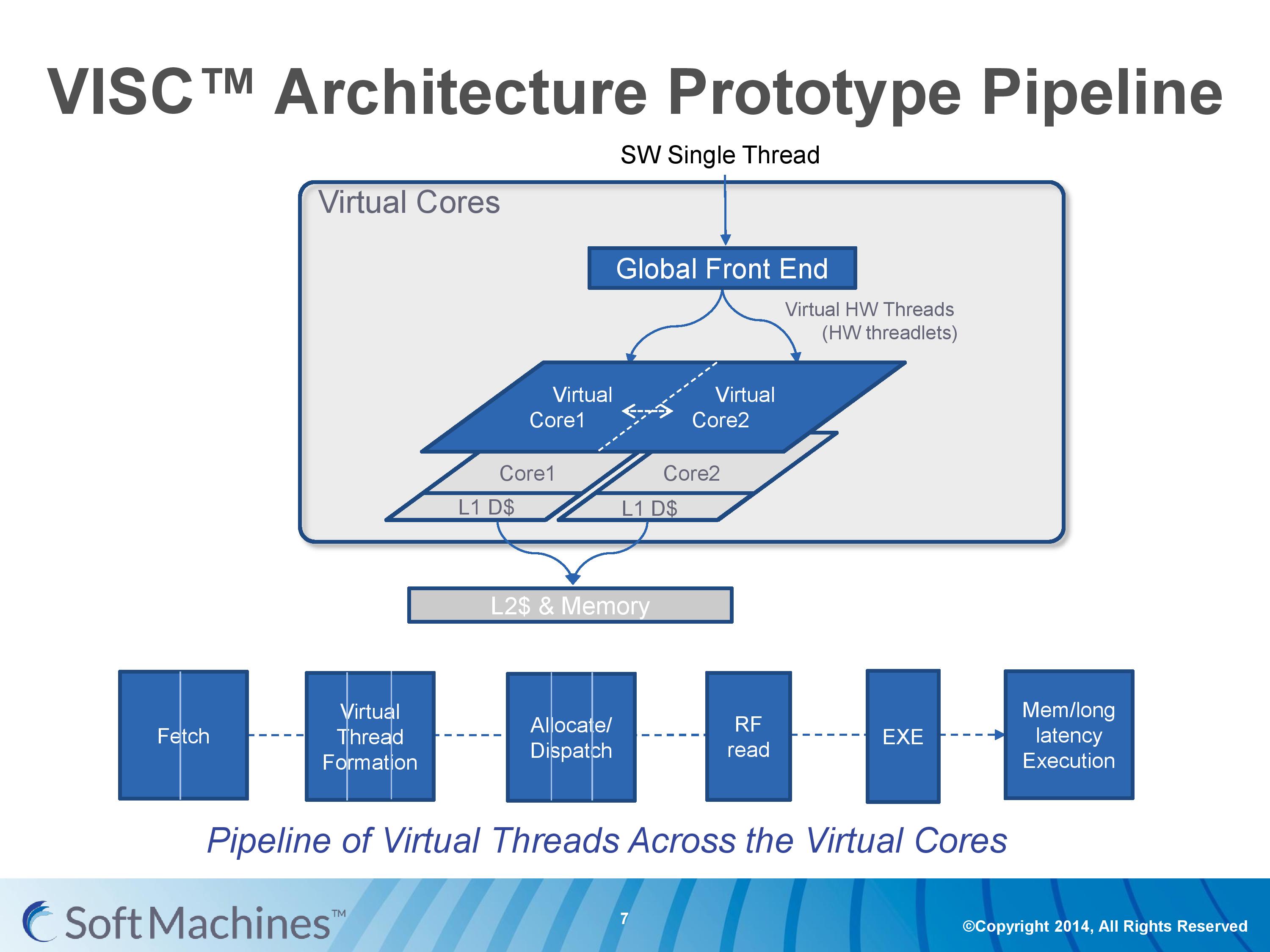
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
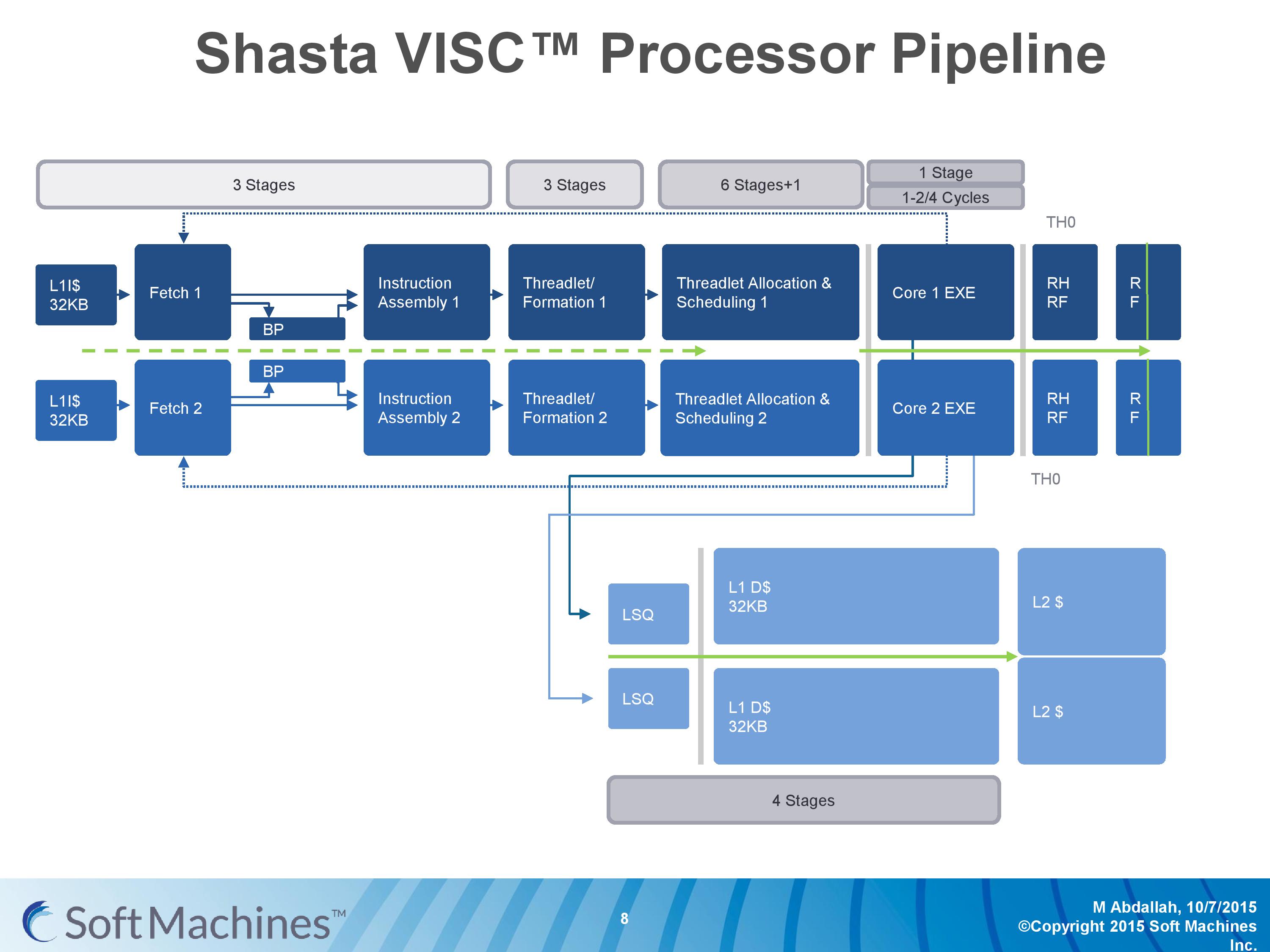
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
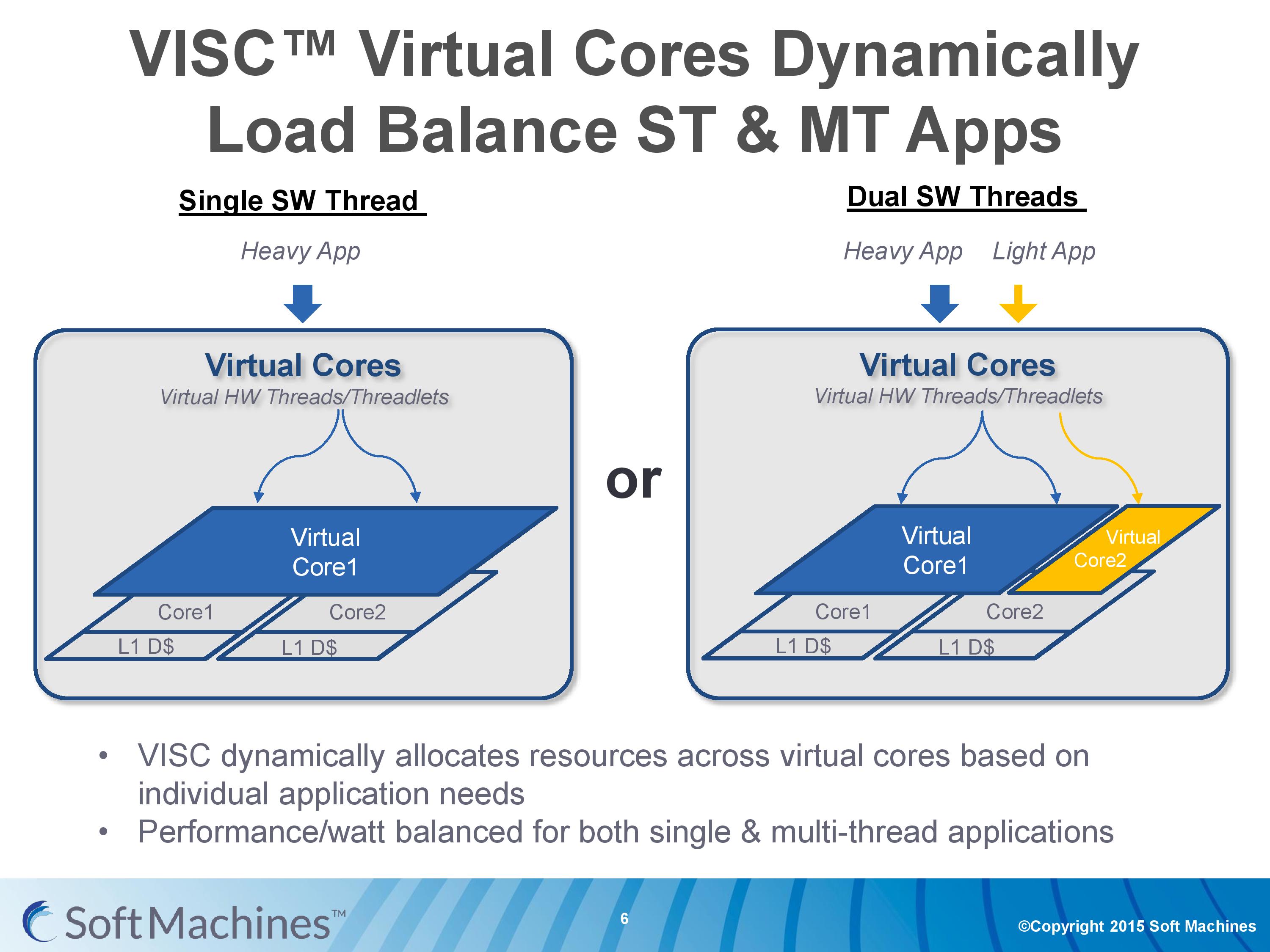
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
extide - Friday, February 12, 2016 - link
Because a compiler can only schedule instructions to the CPU's front end. This is scheduling of instructions to different ports on the back end of the cpu. The compiler can't tell the CPU what port an instruction goes down, the CPU picks that. THe compiler only gets to pick what instructions are issues, and in what order, and of course, modern CPU's can even change that order if they deem it faster to do so.Exophase - Friday, February 12, 2016 - link
To have any realistic chance of working the threading speculation/detection has to have a large dynamic component (detecting threadlets as they become desirable at runtime) and has to have architectural support for very lightweight thread splitting, merging, and inter-thread communication.That can't be provided by compilers targeting existing instruction sets.
AlexTi - Friday, February 12, 2016 - link
Thanks, I think I got the point finally. This looks similar to what instruction scheduler currently does for execution units in conventional CPU. Virtualization layer + CPUs will be a kind of very wide core. Right?It was already noted in the article, making curent CPU wider is problematic and not universally beneficial. So this new engine should be much more efficient than current implementations.
Good thing is that we'll see eventually :)
Senti - Friday, February 12, 2016 - link
Bullshit. I have no idea how technically incompetent writers should be to reprint that marketing nonsense again and again.First of all, this brings absolutely no advantages over existing fat core + SMT concept. More IPC per core with more pipelines is not done because it's hard to do without that 'virtual cores' nonsense, but simply because there are not enough actually independent instructions that can be automatically extracted from real code during parts where performance matters.
"Alternatively, if multiple programs or threads want to use the hardware, then a single core is inaccessible to additional threads while the first thread is still in use (though this can be avoided somewhat by simultaneous multithreading or SMT which will let another thread have access when the first has encountered a stall such as waiting for L1/L2 memory)." - total lies. That describes coarse-grained multithreading which is not very popular atm. For example, Intel HT allows usually 2 threads to execute simultaneously dynamically sharing pipelines of the same core all the time. POWER8 uses 8 'virtual' threads per core.
Why no one splits instructions from the same thread over several cores (other than the obvious reason that there are not enough independent instructions to split)? Almost quote from the text: "cross-core communication adds latency and reduces performance".
Instruction set emulation? Far from new concept. Why not popular? Reason is very simple: significant overhead. Try translating something non-trivial like AVX/NEON instructions to some generic internal instruction set.
Finally, the last point: everyone can draw cute performance graphs and huge numbers in marketing presentations, but how about giving actually working chips for independent reviews of performance and power efficiency on real code?
vladx - Sunday, February 14, 2016 - link
Skim the article again, there's a roadmap so let's see how things will go from here.Exophase - Friday, February 12, 2016 - link
There's another big question with their power measurements. They take differences between idle and 1C and 1C and 2C to cancel out the static contribution of other peripherals. But this still ignores the dynamic contribution.For example, we can look at Cortex-A72, where ARM claims that one core at 2.5GHz on the TSMC 16FF+ process will consume about 750 mW. In Kirin 950, the power consumption appears to be about 900 mW at 2.3GHz. Is ARM exaggerating or is Huawei's implementation inferior to ARM's expectations? The discrepancy can actually be pretty easily explained by losses in the PMIC/VRMs, the SoC's memory controller, and the DRAM - all components which use more power the more the CPU load increases.
This is especially a factor for wall measurements because they take into effect an additional AC/DC convertor. While it's possible that Soft Machines included these figures in their power estimations I doubt it since they didn't mention it, and like ARM it's more practical and beneficial for them to work with core power estimations only.
So there could easily be another 25+% that the non-VISC platforms are being penalized.
Something else that raises a red flag to me is the 16FF+ test chip. There are only 100 pins. When you take out power, ground, and various control signal are accounted for that leaves a very small interface either to a memory controller or memory (if the controller is integrated). Even a single channel 32-bit interface would be a hard fit. So does this chip really represent both realistic power consumption or realistic performance? I think they're trading one for the other on this one and that makes me question the applicability of the power numbers they've given for it.
Arnulf - Friday, February 12, 2016 - link
Since one cannot buy these "scaled" chips, IMHO it'd make more sense for SMI to publish performance per watt figures of real hardware and let the market decide whether their concept is attractive enough. Yes, Intel may have process node advantage, yes, different CPUs are targetting different performance and power profiles but at least it's a straight comparison and if VISC doesn't beat its entire competition at at least one metric then it's destined to fail anyway.Oh and the remark in the article regarding "VISC advantage" because of it using twice the number of cores while running a single thread in tests - who cares as long as it comes out on top in performance per watt? If they can beat other CPUs by using more cores, kudos to them!
ppi - Saturday, February 13, 2016 - link
Regarding core count, I would direct you to recent AT article on Android usage of multiple cores. Simplified conclusion may be, that Android tends to utilise 4 cores pretty well.In real world, this significantly reduces impact of distributing single thread over multiple cores.
kgardas - Friday, February 12, 2016 - link
Interesting stuff, but to be honest, combining "simpler" cores into more complex is also done by software on SPARC64. At least Fujitsu mentions this on some of their hotchip presentation for SPARC64 VII. So you have 4 cores CPU with 4-wide core and you can combine this by software (compiler) into 8-wide or more depending on your needs for instruction parallelism.Another thing is that something like that is IIRC also supported by POWER8 where you do have a lot of duplicated resources, but not enough so in case 1 thread is able to consume all core resources you may switch-off 7 others. IIRC IBM's compilers contains some optimizations for this too.
Pity think you have mentioned Itanium only in this negative way. Honestly speaking Itanium design was really great and really pity that Intel stopped developing it and not provided any OoO designs on this architecture. If Denver will be successful we will see, but NVidia still counts with it for some designs which may be interesting in a light that they are using ARM's core (A57) for some time now and don't need Denver that much. Also automotive does not care if Denver is there or not yet nVidia pushes it there so I would bet they needs to have really good reason for it. Perhaps their VLIV is good for some special tasks...
So to me whole this looks like they are on another round for money.
Oxford Guy - Friday, February 12, 2016 - link
"Honestly speaking Itanium design was really great and really pity that Intel stopped developing it"The market disagreed so, if you're right, it's a pity the market dictates product success to such a degree.