Qualcomm Launches 48-core Centriq for $1995: Arm Servers for Cloud Native Applications
by Ian Cutress on November 10, 2017 6:30 AM EST- Posted in
- CPUs
- Arm
- Qualcomm
- Enterprise
- SoCs
- ARMv8
- Centriq
- Centriq 2400
- Cloud
- Falkor

Following on from the SoC disclosure at Hot Chips, Qualcomm has this week announced the formal launch of its new Centriq 2400 family of Arm-based SoCs for cloud applications. The top processor is a 48-core, Arm v8-compliant design made using Samsung’s 10LPE FinFET process, with 18 billion transistors in a 398mm2 design. The cores are 64-bit only, and are grouped into duplexes – pairs of cores with a shared 512KB of L2 cache, and the top end design will also have 60 MB of L3 cache. The full design has 6 channels of DDR4 (Supporting up to 768 GB) with 32 PCIe Gen 3.0 lanes, support for Arm Trustzone, and all within a TDP of 120W and for $1995.
We covered the design of Centriq extensively in our Hot Chips overview, including the microarchitecture, security and new power features. What we didn’t know were the exact configurations, L3 cache sizes, and a few other minor details. One key metric that semiconductor professionals are interested in is the confirmation of using Samsung’s 10LPE process, which Qualcomm states gave them 18 billion transistors in a 398mm2 die (45.2MTr/mm2). This was compared to Intel’s Skylake XCC chip on 14nm (37.5MTr/mm2, from an Intel talk), but we should also add in Huawei’s Kirin 970 on TSMC 10nm (55MTr/mm2). Today Qualcomm is releasing all this information, along with a more detailed block diagram of the chip.
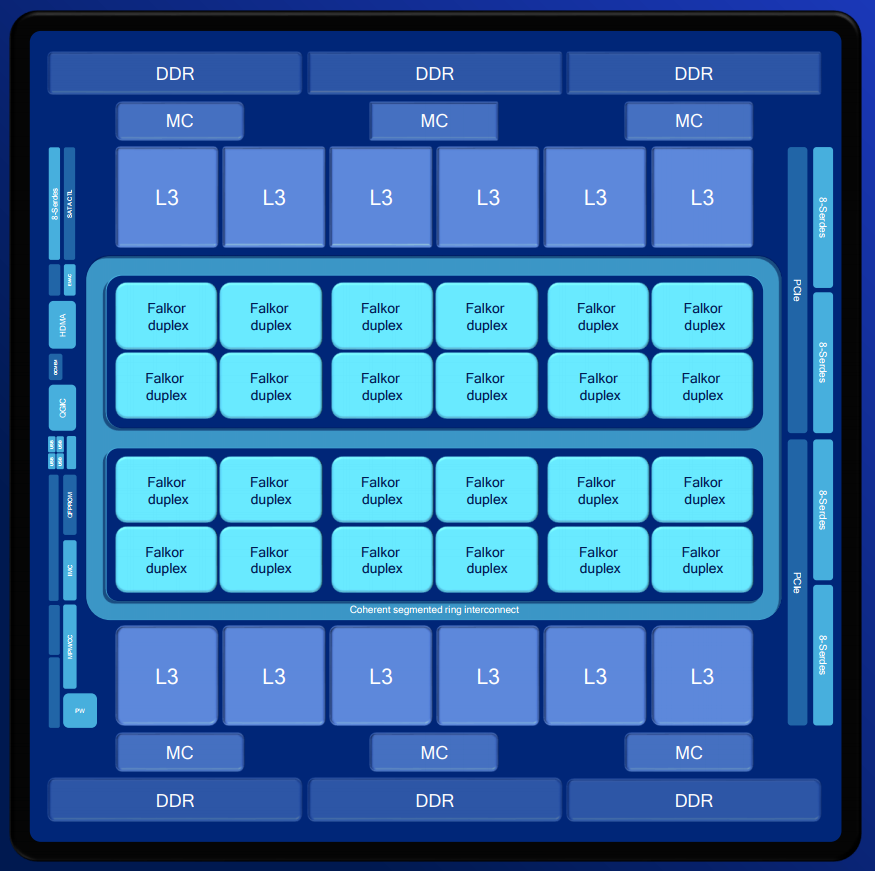
The chip has 24 duplexes, essentially grouped into sets of four. Connecting them all is a bi-directional segmented ring bus, with a mid-silicon bypass to speed up cross-core transfers. This ring bus is set with 250 GBps of aggregate bandwidth. Shown in the diagram are 12 segments of L3 cache, which means these are shipped with 5 MB each (although there may be more than 5 MB in a block for yield redundancy). This gives a metric of 1.25 MB of L3 cache per core, and for the SKUs below 48 cores the cache is scaled accordingly. Qualcomm also integrates its inline memory bandwidth compression to enhance the workflow, and provides a cache quality of service model (as explained in our initial coverage). Each of the six memory controllers supports a channel of DDR4-2667, with support up to 768GB of memory and a peak aggregate bandwidth of 128 GB/s.
| Qualcomm Centriq 2400 Series | |||
| AnandTech.com | Centriq 2460 | Centriq 2452 | Centriq 2434 |
| Cores | 48 | 46 | 40 |
| Base Frequency | 2.2 GHz | 2.2 GHz | 2.3 GHz |
| Turbo Frequency | 2.6 GHz | 2.6 GHz | 2.5 GHz |
| L3 Cache | 60.0 MB | 57.5 MB | 50 MB |
| DDR4 | 6-Channel, DDR4-2667 | ||
| PCIe | 32 PCIe 3.0 | ||
| TDP | 120 W | 120 W | 110 W |
| Price | $1995 | $1373 | $888 |
Starting with the chips on offer, Qualcomm will initially provide three different configurations, starting with 40 cores at 2.3 GHz (2.5 GHz turbo), up to 46 and 48 cores both at 2.2 GHz (2.6 GHz turbo). All three chips are somewhat equal, binned depending on active duplexes and cache, with $1995 set for the top SKU. Qualcomm is aiming to attack current x86 cloud server markets on three metrics: performance per watt, overall performance, and cost. In that regard it offered three distinct comparisons, one for each chip:
- Centriq 2460 (48-core, 2.2-2.6 GHz, 120W) vs Xeon Platinum 8180 (28-core, 2.5-3.8 GHz, 205W)
- Centriq 2452 (46-core, 2.2-2.6 GHz, 120W) vs Xeon Gold 6152 (22-core, 2.1-3.7 GHz, 140W)
- Centriq 2434 (40-core, 2.3-2.5 GHz, 110W) vs Xeon Silver 4116 (12-core, 2.1-3.0 GHz, 85W)
Qualcomm provided some SPECint_rate2006 comparisons between the chips, showing Centriq either matching or winning in performance per thread, beating in performance per watt, and up to 4x in performance per dollar. It should be noted that the data for the Intel chips were interpolated from other Xeon chips, except the 8180. Those numbers can be found in our gallery below.
One interesting bit of data from the launch was the power consumption results provided. As a server or cloud CPU scales to more cores, there will undoubtedly be situations where not all the cores are always drawing power, either due to how the algorithm works or the system is waiting on data. Normally the TDP values are given as a measure of power consumption, despite the actual definition of thermal dissipation requirements – a 120W chip does not always draw 120W, in other words. To this end, Qualcomm provided the average power consumption of the 120W Centriq 2460 while running SPECint_rate2006.

It shows a median power consumption of 65W, peaking just below 100W for hmmer and h264ref. The other interesting point is the 8W idle power, which is indicated as for only when C1 is enabled. With all idle states enabled, Qualcomm claims under 4W for the full SoC. Qualcomm was keen to point out that this includes the IO on the SoC, which requires a separate chipset on an Intel platform.

Any time an Arm chip comes into the enterprise space, thoughts immediately turn to high-performance, and Qualcomm is keen here to point out that while performant, their main goal is to cloud services and hyper-scale, such as scale-out situations, micro-services, containers, and instance-based implementations. At the launch in San Diego, they rolled out quotes from Alibaba, Google, HPE, and Microsoft, all of whom are working closely with Qualcomm for deployment. Demonstrations at the launch event included NoSQL, cloud automation, data analytics with Apache Spark, deep learning, network virtualization, video and image processing, compute-based bioinformatics, OpenStack, and neural networks.
On the software side, Qualcomm is working with a variety of partners to enable and optimize their software stacks for the Falkor design. At Hot Chips, Qualcomm also stated that there are plans in the works to support Windows Server, based on work done with their Snapdragon on Arm initiative, although this seemed to be missing from the presentation.

Also as a teaser, Qualcomm gave the name of its next-generation enterprise processor. The next design will be called the Qualcomm Firetail, using Saphira cores. (Qualcomm has already trademarked both of those names).
Qualcomm Centriq is now shipping (for revenue) to key customers. We should be on the list for review samples when they become available.














37 Comments
View All Comments
mmrezaie - Friday, November 10, 2017 - link
Thanks for the mentioning of the article. It was a great read.zepi - Friday, November 10, 2017 - link
When you consider your average hyper-v / vmware cloud deployment, it might very well be that the 48core version is best choice because it aligns better with the license-pricing.deltaFx2 - Saturday, November 11, 2017 - link
Neither MS nor VMWare have an ARM virtualization solution so this discussion might be moot at least for now. Perhaps sometime in the future?xakor - Friday, November 10, 2017 - link
How is either a 16c Xeon or AMD not gonna totally mop the floor with this? Note that I'm not trying to be arrogant likely just very ignorant.psychobriggsy - Friday, November 10, 2017 - link
Read the cloudflare review of the chip and then maybe consider positing the opposite of your current question.deltaFx2 - Saturday, November 11, 2017 - link
Hardly. So in the cloudflare review it only wins in gzip compression and openSSL across the board. It wins a few cases in brotli. Other than that, it gets beaten pretty handily. My guess is that the 60MB cache is what's doing the trick here. The bdw and sky systems are hampered by being 2P, and lesser total cache which likely helps (the reviewer states this about brotli). And they didn't test it against the elephant in the room, EPYC. For $2k, you'll get an EPYC 1P with 24 cores, 2 more memory channels, and 4X PCIe lanes. And unlike Intel, AMD is motivated to compete on price.The thing going for Falkor is the low power consumption.
MrSpadge - Friday, November 10, 2017 - link
I'd say the 46 core chip may be an even better value proposal than the 40 core version. The reason is that you need to buy a lot more than the CPUs to build a server, especially the memory is going to be a significant cost factor in these price regions. So the 400$ higher CPU price for 15% more cores may be a lot less than 15% of the total price.The smaller chip would still be good for evaluation or situations where the throughput is limited by something else than the CPU.
Samus - Saturday, November 11, 2017 - link
I agree. But it really depends how many servers you are building overall. If you are building dozens, use the 40 core chip and just built one or two more to make up for it. At a savings of over $1000 for each server this would likely save a ton of money.HStewart - Friday, November 10, 2017 - link
One thing that to think about the number of cores is not a good factor on performance. Difference of core and CPU architecture should be taken in account and not just the core count. For example a Single Xeon core has much more performance than AMD and ARM core.A lot depends on applications running on system - for example if Application use AVX-512 on Xeons - than using only AVX-256 especially in AMD implementation which is basically two 128 units combine. Also ARM is RISC and by designed it takes many ARM instruction to implement a single AVX instruction.
Wilco1 - Friday, November 10, 2017 - link
The IPC difference between high-end Arm cores and Xeon is fairly small nowadays, and there are Arm cores with higher IPC.Also it's incorrect to claim RISC requires more instructions. On typical code AArch64 would use fewer instructions. On highly vectorized code having wider vectors will help of course, but that's not the type of application being targeted here.