Linux Desktop CPU Roundup: Cutting Edge Penguin Performance
by Kristopher Kubicki on September 19, 2004 8:00 PM EST- Posted in
- Linux
Content Creation
On the other end of Synthetic Benchmarks, we have content creation benchmarks, which are extremely difficult to replicate and convey little information if interpreted incorrectly. Below, we compiled lame 3.96.1 without any additional optimizations and then used the following command on a 800mb .wav file.# lame sample.wav -b 192 -m s -h - >/dev/null
The file is sent to stdout, which is then directed to /dev/null. We do not want the hard drive to throttle our MP3 encoding if possible, even if we are just immediately destroying it.
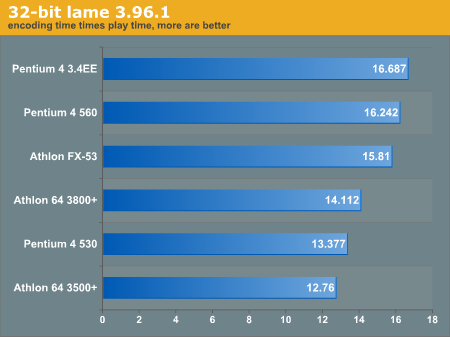
Hold your mouse over for the 64-bit graph.
Under the GCC 3.4.1 compiler, we noticed the largest difference between 64-bit and 32-bit binaries yet. The 64-binaries are encoding 25 times faster than if we were to play them, i.e. in one second the Athlon FX-53 encodes ~25 seconds worth of playtime!
Next, we used the SuSE 9.1 Pro i686 RPM for this portion of the analysis. The 700MB test file from the lame benchmark above was compressed and then timed using the command below.
# time gzip -c sample.wav > /dev/null
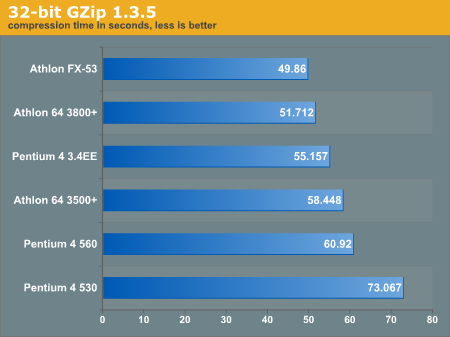
Hold your mouse over for the 64-bit graph.
Now on to our MEncoder test. We compiled 1.0pre5 from source without any optimizations. We had difficulty getting MPlayer to compile on x86_64, and thus, that portion was omitted. The benchmark command that we ran is below:
# time mencoder sample.mpg -nosound -ovc lavc vcodec=mpeg4:vpass=2 -o sample.avi

Again, we saw vast differences between the AMD and Intel processors on these content specific benchmarks.








33 Comments
View All Comments
Cheval - Monday, September 20, 2004 - link
Using Firefox 1.0PR and those graphs don't work either.jensend - Monday, September 20, 2004 - link
Were any of the 32-bit binaries (incl kernel) conducted with -mregparm=x where x!=0? See e.g. http://lwn.net/Articles/66965/ - improvements in the use of registers are generally the main source of performance improvements for x86-64, and using this parameter can significantly improve gcc's register usage on regular x86. Generally, mregparm=3 is recommended for the kernel and =1 for C++ code.RyanHirst - Monday, September 20, 2004 - link
o, i c.k.
ryan
LittleKing - Monday, September 20, 2004 - link
The article is good, but the Rollover images don't work in FireFox 9.2.KristopherKubicki - Monday, September 20, 2004 - link
I had trouble compiling crafty. The numbers were more to show the impact of compiler options rather than actual chess numbers themselves.Kristopher
RyanHirst - Monday, September 20, 2004 - link
Hello,Liked the article! I was disappointed to see you stuck with the only chess engine on the planet that is faster on a 3.6GHz P4 than a 2.4GHz A64. The Crafty benches looked odd, but they were more realistic. Even with HT optimized engines like Frtiz8 (which has competed internationally for as much as $1 million on Xeon machines, including one 4-way Xeon "donation" from Intel) pull almost identical numbers between the top a64 and the top p4.
If, as I assume, you left HT off [which you should for benchmarks. there are some odd issues with HT and chess], there just isn't a chess program around (except apparently TSCP) that pulls these numbers.
I know there is a risk of sounding fanboyish. That is not my intent. I play in the computer engine room on playchess.com, and I know the numbers I get from other machines. The benchmark you are using is simply not representative of chess engines. Please take a look at Frtiz benchmarks at: www.beepworld.de/members39/computerschach2/chessmarks.htm [disregard the top dual xeon score; "Deep Fritz 8" calculates many more nodes/s than regular "Fritz8", even on a single processor]. Again, this is an engine that is optimized for the Pentium architecture.
Less dedicated engines like Crafty show the results that, unfortunately, you found questionable in the previous article. Bob Hyatt has been programming chess for decades and Crafty is available on every major desktop OS. It's part of the SPEC2000 benchmark [where it performs identically on a lowly XP3200 and a Xeon 3.4]. It is also the first engine out the door with a 64-bit clean code! In one of the few fields where 64-bit computing can offer a near perfect doubling of calculations/s, why leave out the 64-bit bench? If you're concerend Crafty is Athlon optimized, check out Hyatt's homepage: www.cis.uab.edu/info/faculty/hyatt/hyatt.html ...his ICC account pet machine is a dual Xeon.
Cheers,
Ryan
KristopherKubicki - Monday, September 20, 2004 - link
johnsonx: sorry about that- i put in the 530 score for the 3500+. The correct score is 175.Kristopher
johnsonx - Monday, September 20, 2004 - link
Good article Kris.I think you've got a graph error on the 32-bit MEncoder graph. You show the P4 530 and the A64 3500+ tied at 146fps, but then show the A64 3800+ at 193fps; that's a 32% higher score for a CPU that is only 9% higher-clocked and otherwise identical. Methinks the 146fps for the A64 3500+ is an error; it should be somewhere between 165 & 175, right around the P4EE.
WooDaddy - Monday, September 20, 2004 - link
"whenever I get cornered by a processor on campus or guest speak at a Linux Users Group"OH NO!!!! ROGUE PROCESSORS ARE ATTACKING PEOPLE ON COLLEGE CAMPUSES!!!! LOCK YOUR DOORS!! GRAB YOUR SHOTGUN!!
heheheh
Kris.. I think you meant professors ;)
I'd still lock your doors and grab weapons of minimal destruction. Professors are scary. Especially the fat ones with suspenders who talk about overclocking their PDP-11s.
Illissius - Monday, September 20, 2004 - link
Nice review, and you actually compared 32- and 64-bit for once ;). Would've been more interesting to do it back when you had some 64-bit Intel processors in the mix as well, though...Why no 64-bit results on the kernel compile? :/ That's probably the single benchmark out of all of them I'd be most interested in (Gentoo :D).
Also, UT2004 has both 32- and 64-bit Linux versions, and nVidia has both 32- and 64-bit Linux drivers. Seeing as this was a desktop review, that would've been nice to see.
I'd personally have been more interested in s754 processors, but they're the same architecture anyways so I can mostly extrapolate their performance from the ones tested, so it isn't a big deal either way.