Next Generation Arm Server: Ampere’s Altra 80-core N1 SoC for Hyperscalers against Rome and Xeon
by Dr. Ian Cutress on March 3, 2020 11:30 AM EST- Posted in
- CPUs
- Arm
- SoCs
- GIGABYTE Server
- Neoverse
- Neoverse N1
- Ampere
- Packet
- Graviton2
- Altra

Several years ago, at a local event detailing a new Arm microarchitecture core, I recall a conversation I had with a number of executives at the time: the goal was to get Arm into 25% of servers by 2020. A lofty goal, which hasn’t quite been reached, however after the initial run of Arm-based server designs the market is starting to hit its stride with Arm’s N1 core for data-centers getting its first outings. Out of those announcing an N1-based SoC, Ampere is leading the pack with a new 80-core design aimed at cloud providers and hyperscalers. The new Altra family of products is aiming to offer competitive performance, performance per watt, and scalability up to 210 W and tons of IO, for any enterprise positioning.
The Arm Server Market: 2010-2019 (Abridged)
We’ve seen companies such as Broadcom/Cavium/Marvell, Calxeda, Huawei, Fujitsu, Phytium, Annapurna/Amazon, AppliedMicro/Ampere, and even AMD put Arm-based IP into silicon and subsequently into the server market. Up until recently, most designs have been fairly lackluster – with companies either developing their own core on an Arm architecture license and not getting a performance lift, or using the standard Arm cores and not finding the right mix of performance, power, and software uptake needed to drive home the design. As a result, we’ve seen multiple companies fall by the wayside, be acquired, or limit their activities to specific customers and keep very hush-hush.
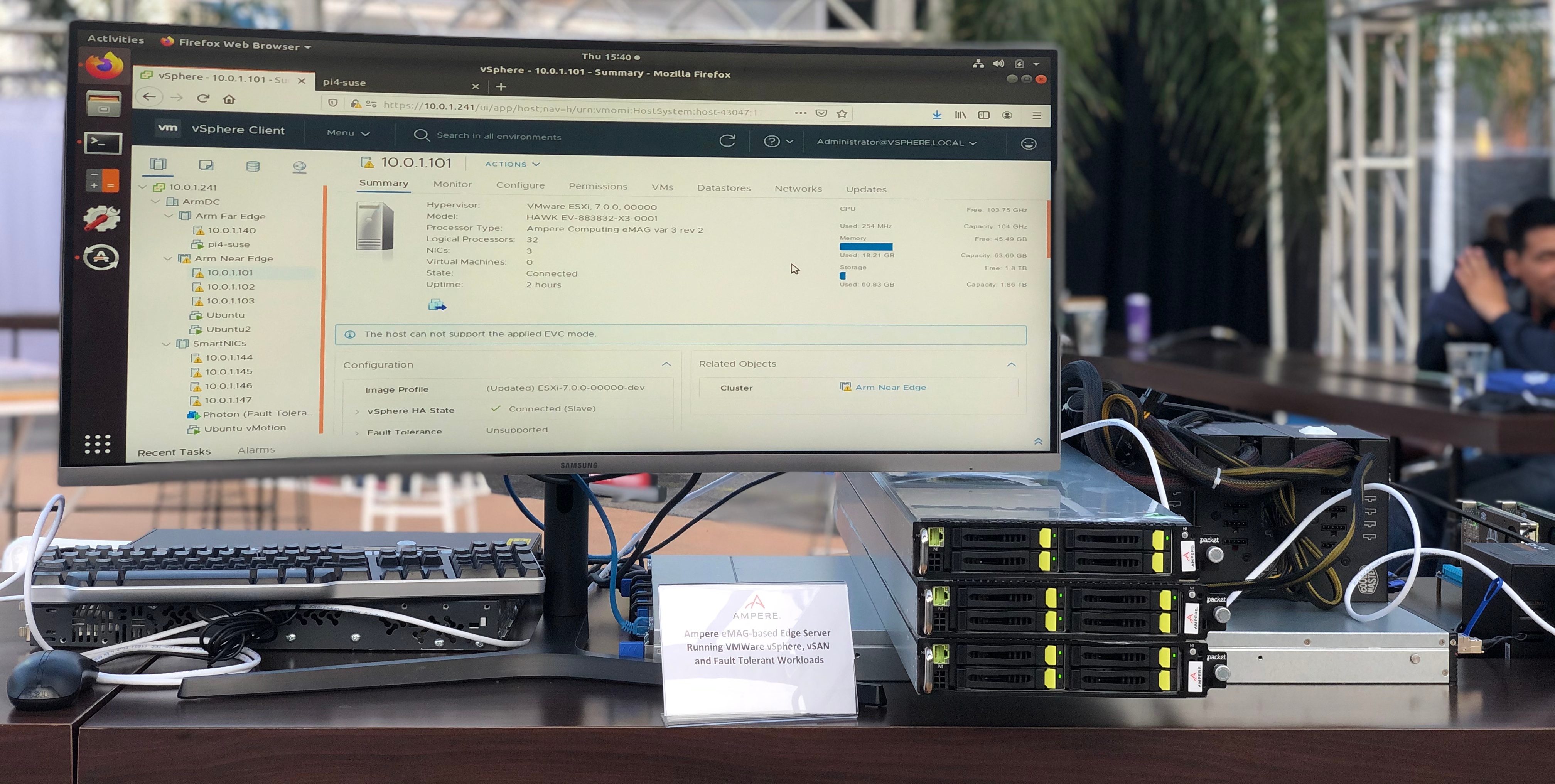
First Generation Ampere eMAG, Built on Applied Micro designs
A big example of the ‘be acquired’ type of company was Annapurna, whom Amazon acquired and eventually released its Graviton2 processor in recent months. This chip has 64 cores based on Arm’s N1 design, which is the leading microarchitecture layout for Arm server chips at this point. To that end, Ampere (who originally purchased Applied Micro) is now set to release its second generation product, with 80 of the N1-based cores, and it now has a name: Altra.
Ampere Altra
Ampere has already given a number of details away about Altra in an announcement late last year, however this time around we have concrete details and the company has performance projections. On the back of its first generation eMAG product, Ampere is looking to offer better-than-Graviton2 performance to any cloud provider or hyperscaler who isn’t called Amazon, given that Graviton2 is built by Amazon and only available to Amazon. In that regard, Ampere has taking Arm’s full recommendations for its N1 design, building a chip with the most number of cores that N1 is designed to support.

As with other N1-based products, Altra will be single threaded, ensuring that each thread has its own core, its own resources, and removing any potential core-sharing thread security issues that have occurred recently. The Altra SoC is built with containers in mind, ensuring high-levels of quality of service with multiple customers on the same chip, and additional RAS features to ensure consistent performance.

The N1 core is by design what we’ve covered when Arm detailed the microarchitecture design last year. There is a 4-cycle 64 KB L1I/L1D caches per core, along with a 9-11 cycle 1 MB of private L2 per core. This is partnered with 32 MB of system wide LLC distributed through the SoC mesh, and all these caches are ECC with SECDED operation. It’s worth noting that 32 MB across 80 cores is less per core than Amazon’s Graviton2, which has 32 MB for 64 cores. 32 MB is actually half of what Arm recommends, as in Arm’s presentation it stated that it would expect a 64-core design to have 64 MB.

On top of the 80 cores, the SoC will also have eight DDR4-3200 memory channels with ECC support, up to 4 TB per socket. There are also 128 PCIe 4.0 lanes, with which the CPU can use 32 of them to hook up to another CPU for dual socket operation. The dual socket system can then have a total of 192 PCIe 4.0 lanes between it, as well as support for up to 8 TB of memory. We are told that it’s actually the CCIX protocol that runs over these PCIe lanes, which means 25 GB/s per x16 linkup. That’s good for 50 GB/s in each direction.
Each of the PCIe lanes can be bifurcated down to x8/x4/x2, and every different variant of the Altra SoC will only be segmented on core count and frequency: all CPUs will have 4 TB support and 128 lanes of PCIe 4.0. Each CPU can also support up to four CCIX-based accelerators.
Altra is built on TSMC’s 7nm, and while is technically an Arm v8.2 design, it does borrow a couple of features from 8.3 and 8.5, namely hardware based mitigations for side channel attacks and a couple of other small micro-architectural features.
Each of the 80 cores is designed to run at 3.0 GHz all-core, and Ampere was consistent in its messaging in that the top SKU is designed to run at 3.0 GHz at all times, even when both 128-bit SIMD units per core are being used (thus an unlimited turbo at 3.0 GHz). The CPU range will vary from 45W to 210W, and vary in core count - we suspect these SKUs will be derived from the single silicon design, and it will depend on demand as well as binning as to what comes out of the fabs. Exact SKUs are going to be announced later this year.

Also on security, Ampere was keen to point out that its new SoC will have two control processors: an SM Pro and a PM Pro. These allow for server manageability, up to SBSA Level 4, as well as Secure Boot, RAS error reporting, and advanced power management/temperature control.

Ampere will be launching with two reference designs for Altra, one in single socket called Mt. Snow, and one in dual socket called Mt. Jade. Each design will be available in 1U and 2U form factors, with PCIe 4.0 and CCIX attach, and up to 16 memory modules per socket. We know that the partner for the single socket is the GIGABYTE Server team, however the dual socket partner has not be announced yet. We have been told that the CPUs are socketed, which makes mass scale production and testing (at least on our side) a little easier.
Projected Performance
Ampere has some performance numbers, which as always we take with a grain of salt. These include 2.23x the performance on SPEC2017_int rate over a single 28-core Intel Xeon Platinum 8280, and 1.04x over a single 64-core AMD EPYC 7742. This is obviously extended into a number of claims about improved TCO. Ampere didn’t provide similar numbers for SPEC2017_fp, because the company states that the SoC has been developed with INT workloads in mind. Exact power/performance numbers were not given, but based purely on TDP, which is somewhat of an unreliable metric at times. We’ll wait to run our own numbers in due course.
Developing a Roadmap: 2021, 2022
One of the key questions going into our briefings with Ampere is how closely they are working with Arm on the next generation enterprise server core designs for upcoming SoCs. They weren’t keen to position themselves as Arm’s key partner in this venture (which might be Amazon, given they were first), but did state that there is a lot of collaboration and feedback that goes into the future designs. As a result, Ampere is able to formally declare a long-term roadmap for its product portfolio.
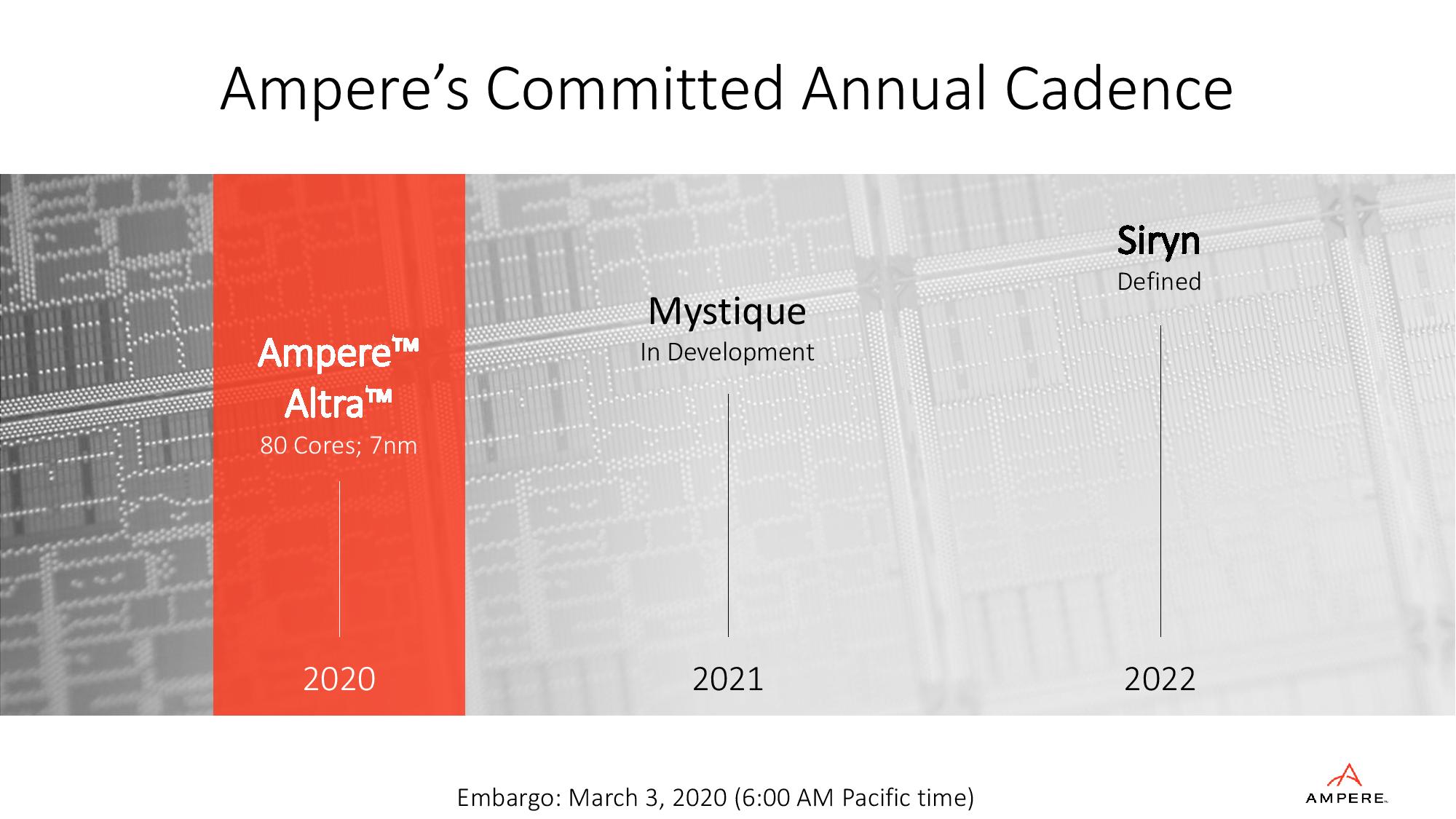
In this instance, Ampere is stating that today it has the 80-core Altra design on 7nm. In 2021, it will launch its Mystique product, which is currently in development (and when asked, Ampere told us will share the same socket as Altra). In 2022, Ampere will launch Siryn, and at this time the product has been defined and requires development.
Having a sustained product cadence has been critical to a number of processor designs in the last couple of decades – it tells potential ODM partners and customers that the company is in for the long haul, and committed to future developments with targets to meet. Obviously with Ampere tying itself to Arm’s roadmap helps in those product definition stages. It’s a feature that has crippled previous Arm designs from coming to market – without a clear roadmap, customers are unwilling to invest in a one-generation wonder and provide long term support for it. There’s always the issue as to whether any investment funding might run out, so Ampere’s goal here with Altra is to be the obvious answer to Graviton2 for the other hyperscalers. With that large market on offer, the goal is to be profitable and self-sustaining as quickly as possible, which then in turn gives potential customers even more confidence.
Next Stage for Altra
At this point, Ampere has stated to us that Altra is currently sampling with its key customers who are looking to deploy the hardware. From previous experience, the key customers who are involved early tend to get priority for deployment, and in that respect Ampere has stated that an official SKU list will come to market mid-year, along with pricing, and with official SPEC submissions. Hopefully at that time we will also get instance pricing from the companies intending to deploy the new chip.

We’re currently in talks with Ampere in order to obtain Altra for in-house testing when they feel it is ready. We have a version of Ampere’s previous generation eMAG workstation that just arrived in the labs, which should help us provide a good base-line from the previous design to the new one. Stay tuned for our coverage of eMAG and Altra!
Related Reading
- 80-Core N1 Next-Gen Ampere, ‘QuickSilver’: The Anti-Graviton2
- Arm Server CPUs: You Can Now Buy Ampere’s eMAG in a Workstation
- Ampere Computing: Arm is Now an Investor
- Ampere eMAG in the Cloud: 32 Arm Core Instance for $1/hr














65 Comments
View All Comments
hescominsoon - Tuesday, March 3, 2020 - link
ok found it's a 210W TDP. Now lets see how it compares to similar TDP cpus..:)Ian Cutress - Tuesday, March 3, 2020 - link
It says this in the article?webdoctors - Tuesday, March 3, 2020 - link
So much text and slides, why not just a few lines saying how it compares in perf to a AMD or Intel or Apple CPU running SPEC2K6 or some common benchmark?The specRATE 2017 int per rack is sooooo vague, do a per core count to make it easy to understand.
Wilco1 - Tuesday, March 3, 2020 - link
Did you not read the article? It says it beats AMDs fastest 64-core Rome by 4% on SPECINT_rate 2017. Or https://www.anandtech.com/Gallery/Album/7519#15This is an impressive result given it does it with 80 threads rather than 128. Also, like Graviton 2, it uses a fraction of the cache and silicon area of Rome to achieve this performance.
name99 - Tuesday, March 3, 2020 - link
It’s not impressive, it’s exactly as expected.Their cores are more or less the same IPC as AMD, running at more or less the same frequency (~3GHz). SMT is worth a quarter of a core, not a whole core.
So 64x1.25=80 .. as expected.
Wilco1 - Tuesday, March 3, 2020 - link
Sure - but it's still impressive. We're not talking about a low-end chip here, we're talking about a startup taking a standard Arm core and beating the fastest x86 server chip!CiccioB - Wednesday, March 4, 2020 - link
It's not impressive that a startup made a chip that is a powerful as the latest ultra advanced, biggest in (x86) core chip that has been ever made?Well, if so, AMD's EPYC is not impressive as well as a startup could glue 80 core instead than only 64 without going around speaking on how good, versatile, powerful (and power hungry) their interconnection bus is.
So we'll wait for the next one piece of impressive silicon to positively comment on innovation and technology which probably will come when Intel will manage to get their MCM chips with their new interconnection buses.
name99 - Wednesday, March 4, 2020 - link
I guess it's impressive if you've had your head in the sand for the past few years!I'm not saying ARM is cheating, or this chip sucks, or whatever, I'm saying that this is exactly what people like me expected!
Ever since Apple started their relentless annual core improvements, followed by ARM always lagging about 2.5 to 3 years behind, it was obvious that this was going to happen.
People like me were talking about ARM making it big in servers in 2020 five years ago. And it's happening, pretty much on the schedule expected, pretty much playing out as expected, pretty much attacking x86 on the fronts we expected. When you calculate the trajectory then the rocket follows it, it's nice to see that your calculations were correct, but impressive is not the right word.
deltaFx2 - Wednesday, March 4, 2020 - link
You may want to read the STH article on how that 4% number is calculated: https://www.servethehome.com/ampere-altra-80-arm-c...They seem to have locked the CPU at 3.3 GHz (3.0 being their max published turbo, so that's single core turbo, at a tdp of 210W). The AMD part has a single core turbo of 3.4 GHz and a base of 2.25GHz, so in these tests, it's running in the 2.8GHz range (approx, guesstimate).
But wait, there's more. They didn't actually measure the spec int rate score on their competitors, they just derated the published base score on aocc and icc by ~17% and 25% respectively (exact numbers in STH).
Even with all this fudging, let's say the spec scores for Epyc and Ampere are the same. So, with 25% more cores, they achieve the same perf as Epyc. SMT yield is ~20-30% on a single core system, so if you turn off SMT on a fully loaded system, say you 25% (memory b/w effects means that SMT doesn't always help spec rate). So at best, a 3.3GHz locked ARM neoverse N1 equals a ~2.8GHz AMD Epyc. i.e. AMD still has higher IPC.
I recall Mike Fillipo/ARM saying the cortex A76 should max out at 3.0GHz. Clever physical design and binning might get 3.3GHz, but that chip is operating in the inefficient part of the VF curve, i.e. power consumption will be horrible. Lets see if they actually put out a 3.3GHz all-core-turbo part and see what the power is. I doubt it will be good.
Wilco1 - Wednesday, March 4, 2020 - link
I have read that article already of course. Direct measurement using identical compiler and options is preferable when possible, but if not, derating is an accepted practice in the industry. GCC is being optimized and the soon to be released GCC10 already shows significantly higher performance on SPEC, so derating may not be needed for much longer!Having a 3.3GHz bin does not seem unusual or impossibly power hungry. It should remain below the 300+W power EPYC 7742 draws at wall running integer code according to Phoronix.
The AnandTech article about Rome showed it can run at least one benchmark at 3.2GHz with 128 threads, so I think you're underestimating Rome's average frequency. I don't think there is any data for SMT gains in SPEC2017, so it would be interesting to see results. My guess is that the N1 has higher overall IPC but throughput scales less due to the much smaller L3 cache.
Whichever way you put it, a small startup showing server performance on par with Rome using a fraction of the silicon area and L3 cache is incredibly impressive.