Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Office and Science
Our previous set of ‘office’ benchmarks have often been a mix of science and synthetics, so this time we wanted to keep our office section purely on real world performance.
Agisoft Photoscan 1.3.3: link
The concept of Photoscan is about translating many 2D images into a 3D model - so the more detailed the images, and the more you have, the better the final 3D model in both spatial accuracy and texturing accuracy. The algorithm has four stages, with some parts of the stages being single-threaded and others multi-threaded, along with some cache/memory dependency in there as well. For some of the more variable threaded workload, features such as Speed Shift and XFR will be able to take advantage of CPU stalls or downtime, giving sizeable speedups on newer microarchitectures.

For the update to version 1.3.3, the Agisoft software now supports command line operation. Agisoft provided us with a set of new images for this version of the test, and a python script to run it. We’ve modified the script slightly by changing some quality settings for the sake of the benchmark suite length, as well as adjusting how the final timing data is recorded. The python script dumps the results file in the format of our choosing. For our test we obtain the time for each stage of the benchmark, as well as the overall time.
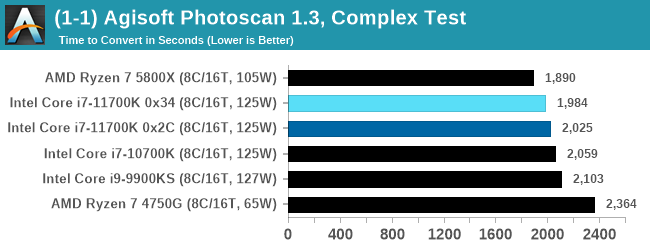
There is a small performance gain here in the real world test across the three generations of Intel processors, however it is still a step away from AMD.
Application Opening: GIMP 2.10.18
First up is a test using a monstrous multi-layered xcf file to load GIMP. While the file is only a single ‘image’, it has so many high-quality layers embedded it was taking north of 15 seconds to open and to gain control on the mid-range notebook I was using at the time.
What we test here is the first run - normally on the first time a user loads the GIMP package from a fresh install, the system has to configure a few dozen files that remain optimized on subsequent opening. For our test we delete those configured optimized files in order to force a ‘fresh load’ each time the software in run. As it turns out, GIMP does optimizations for every CPU thread in the system, which requires that higher thread-count processors take a lot longer to run.
We measure the time taken from calling the software to be opened, and until the software hands itself back over to the OS for user control. The test is repeated for a minimum of ten minutes or at least 15 loops, whichever comes first, with the first three results discarded.
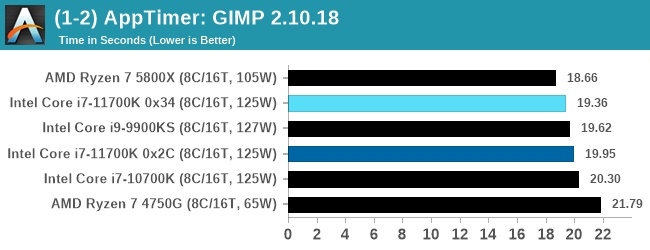
The app initialization test here favors single core performance, and AMD wins despite the lower single thread frequency. The 9900KS has a slight advantage, being a guaranteed 5.0 GHz, but none of the improved IPC from the Cypress Cove seems to come into play here.
Science
In this version of our test suite, all the science focused tests that aren’t ‘simulation’ work are now in our science section. This includes Brownian Motion, calculating digits of Pi, molecular dynamics, and for the first time, we’re trialing an artificial intelligence benchmark, both inference and training, that works under Windows using python and TensorFlow. Where possible these benchmarks have been optimized with the latest in vector instructions, except for the AI test – we were told that while it uses Intel’s Math Kernel Libraries, they’re optimized more for Linux than for Windows, and so it gives an interesting result when unoptimized software is used.
3D Particle Movement v2.1: Non-AVX and AVX2/AVX512
This is the latest version of this benchmark designed to simulate semi-optimized scientific algorithms taken directly from my doctorate thesis. This involves randomly moving particles in a 3D space using a set of algorithms that define random movement. Version 2.1 improves over 2.0 by passing the main particle structs by reference rather than by value, and decreasing the amount of double->float->double recasts the compiler was adding in.
The initial version of v2.1 is a custom C++ binary of my own code, and flags are in place to allow for multiple loops of the code with a custom benchmark length. By default this version runs six times and outputs the average score to the console, which we capture with a redirection operator that writes to file.

For v2.1, we also have a fully optimized AVX2/AVX512 version, which uses intrinsics to get the best performance out of the software. This was done by a former Intel AVX-512 engineer who now works elsewhere. According to Jim Keller, there are only a couple dozen or so people who understand how to extract the best performance out of a CPU, and this guy is one of them. To keep things honest, AMD also has a copy of the code, but has not proposed any changes.
The 3DPM test is set to output millions of movements per second, rather than time to complete a fixed number of movements.
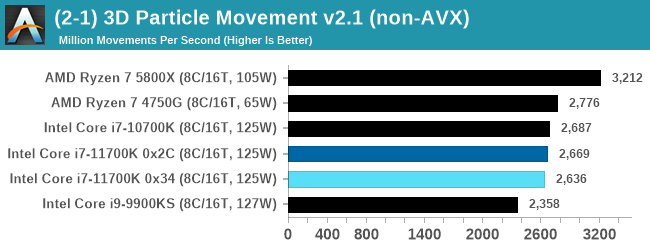
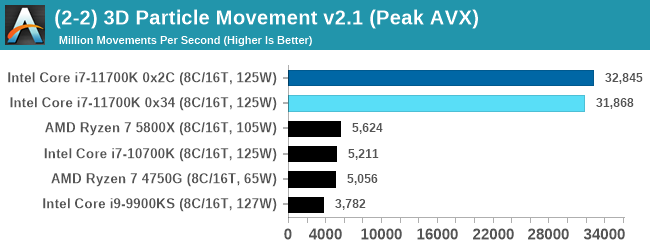
When AVX-512 comes to play, every-one else goes home. Easiest and clearest win for Intel.
y-Cruncher 0.78.9506: www.numberworld.org/y-cruncher
If you ask anyone what sort of computer holds the world record for calculating the most digits of pi, I can guarantee that a good portion of those answers might point to some colossus super computer built into a mountain by a super-villain. Fortunately nothing could be further from the truth – the computer with the record is a quad socket Ivy Bridge server with 300 TB of storage. The software that was run to get that was y-cruncher.
Built by Alex Yee over the last part of a decade and some more, y-Cruncher is the software of choice for calculating billions and trillions of digits of the most popular mathematical constants. The software has held the world record for Pi since August 2010, and has broken the record a total of 7 times since. It also holds records for e, the Golden Ratio, and others. According to Alex, the program runs around 500,000 lines of code, and he has multiple binaries each optimized for different families of processors, such as Zen, Ice Lake, Sky Lake, all the way back to Nehalem, using the latest SSE/AVX2/AVX512 instructions where they fit in, and then further optimized for how each core is built.
For our purposes, we’re calculating Pi, as it is more compute bound than memory bound. In ST and MT mode we calculate 250 million digits.
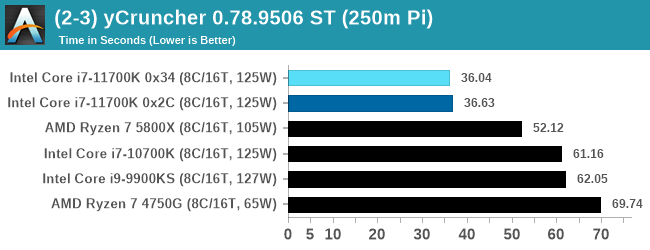
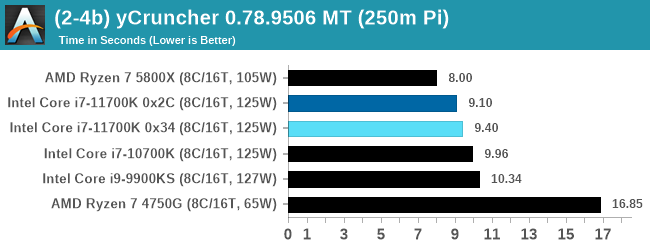
In ST mode, we are more dominated by the AVX-512 instructions, whereas in MT it becomes a mix of memory as well.
NAMD 2.13 (ApoA1): Molecular Dynamics
One of the popular science fields is modeling the dynamics of proteins. By looking at how the energy of active sites within a large protein structure over time, scientists behind the research can calculate required activation energies for potential interactions. This becomes very important in drug discovery. Molecular dynamics also plays a large role in protein folding, and in understanding what happens when proteins misfold, and what can be done to prevent it. Two of the most popular molecular dynamics packages in use today are NAMD and GROMACS.
NAMD, or Nanoscale Molecular Dynamics, has already been used in extensive Coronavirus research on the Frontier supercomputer. Typical simulations using the package are measured in how many nanoseconds per day can be calculated with the given hardware, and the ApoA1 protein (92,224 atoms) has been the standard model for molecular dynamics simulation.
Luckily the compute can home in on a typical ‘nanoseconds-per-day’ rate after only 60 seconds of simulation, however we stretch that out to 10 minutes to take a more sustained value, as by that time most turbo limits should be surpassed. The simulation itself works with 2 femtosecond timesteps. We use version 2.13 as this was the recommended version at the time of integrating this benchmark into our suite. The latest nightly builds we’re aware have started to enable support for AVX-512, however due to consistency in our benchmark suite, we are retaining with 2.13. Other software that we test with has AVX-512 acceleration.
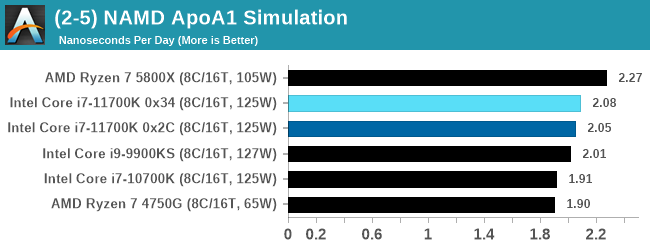
The 11700K shows some improvement over the previous generations of Intel, however it does sit much in the middle of the APU and the Zen 3.
AI Benchmark 0.1.2 using TensorFlow: Link
Finding an appropriate artificial intelligence benchmark for Windows has been a holy grail of mine for quite a while. The problem is that AI is such a fast moving, fast paced word that whatever I compute this quarter will no longer be relevant in the next, and one of the key metrics in this benchmarking suite is being able to keep data over a long period of time. We’ve had AI benchmarks on smartphones for a while, given that smartphones are a better target for AI workloads, but it also makes some sense that everything on PC is geared towards Linux as well.
Thankfully however, the good folks over at ETH Zurich in Switzerland have converted their smartphone AI benchmark into something that’s useable in Windows. It uses TensorFlow, and for our benchmark purposes we’ve locked our testing down to TensorFlow 2.10, AI Benchmark 0.1.2, while using Python 3.7.6.

The benchmark runs through 19 different networks including MobileNet-V2, ResNet-V2, VGG-19 Super-Res, NVIDIA-SPADE, PSPNet, DeepLab, Pixel-RNN, and GNMT-Translation. All the tests probe both the inference and the training at various input sizes and batch sizes, except the translation that only does inference. It measures the time taken to do a given amount of work, and spits out a value at the end.
There is one big caveat for all of this, however. Speaking with the folks over at ETH, they use Intel’s Math Kernel Libraries (MKL) for Windows, and they’re seeing some incredible drawbacks. I was told that MKL for Windows doesn’t play well with multiple threads, and as a result any Windows results are going to perform a lot worse than Linux results. On top of that, after a given number of threads (~16), MKL kind of gives up and performance drops of quite substantially.
So why test it at all? Firstly, because we need an AI benchmark, and a bad one is still better than not having one at all. Secondly, if MKL on Windows is the problem, then by publicizing the test, it might just put a boot somewhere for MKL to get fixed. To that end, we’ll stay with the benchmark as long as it remains feasible.
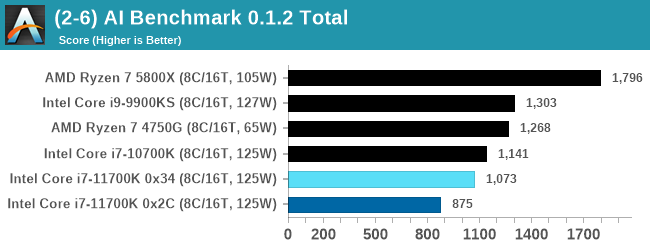
Every generation of Intel seems to regress with AI Benchmark, most likely due to MKL issues. I have previously identified the issue for Intel, however I have not heard of any progress to date.








541 Comments
View All Comments
shabby - Sunday, March 7, 2021 - link
I hear intel will be bringing back btx to cope with the 300w+ 11900k...Doug1820 - Sunday, March 7, 2021 - link
Rocket Lake is looking more and more like Netburst 2.0.Oxford Guy - Sunday, March 7, 2021 - link
Someone literally wrote ‘I commend Intel for this release’. Commend? Perhaps the word originally sought was condemn?This product exists due to inadequate competition. It is a gift from monopolization. While the mantra of the corporation is ‘sell less for more’, it’s adequate competition that’s supposed to be its saving grace. That hasn’t been the case in many areas of tech for a long time.
Not only is AMD not enough competition, it took this long for the company to finally beat Intel badly. If Intel had managed its business better it would still be competitive.
And, to top things off, just like in GPUs (dire lack of competition) it’s extremely profitable to fail. Nvidia is failing to meet gamer demand, for various reasons that come down to inadequate competition. Despite that, it is taking record money. Intel is profitable despite failing in the consumer desktop CPU market.
Allison Kilkenny joked that America is special because one can ‘fail upward’. But, really, tech has a huge problem with inadequate competition — a global one.
People see brief glimmers of competition and mistake it for adequate competition. This is not the first time AMD had the better CPU design and we all know how that turned out.
Being held captive by one and 1/2 companies (the typical tech competition ratio) isn’t at all close to approaching ideal.
If huge profitability while failing very badly to meet demand is the recipe for a good state of business...
GeoffreyA - Monday, March 8, 2021 - link
I believe that was me. "While it hasn't displaced Ryzen, I commend Intel for the effort that Rocket Lake is."I should have worded it better, I agree, but what I meant was, instead of just releasing another Skylake refresh, they did the unthinkable, in an attempt to release something: porting Sunny Cove to their legacy node. "We will fail, but we'll try anyway, futile though our efforts may be." Their being the underdog at present makes me feel a bit sorry for them, but then again, when we consider Intel's bank account, we realise they don't need our sympathy.
For my part, I am not an Intel shill or proponent. In fact, from my teenage years I've had a distaste towards them, and as I see it, Rocket Lake is a disappointment: still behind Zen 3, using far more power, slower graphics than Tiger Lake. There's practically no good in it. For the elusive Sunny Cove, I had expected a lot more. Despite that, I do commend them for making an attempt, something in life that's more important than winning.
GeoffreyA - Monday, March 8, 2021 - link
As for the business/economic side of the matter, I don't understand these things too much to comment, but from that side, Intel has always been wretched; and all these companies are only out to make profit. We've even learned that those who offer something for nothing---it comes at a cost (Google, Facebook, etc.).Spunjji - Monday, March 8, 2021 - link
100%Oxford Guy - Tuesday, March 9, 2021 - link
'all these companies are only out to make profit'Which means consumers need to get their heads out of the sand and fight for value for their dollars.
Spunjji - Monday, March 8, 2021 - link
Intel are very much not the underdog - they're still the 800 lb gorilla, they've just got themselves trapped inside a cage of their own making. Tiger Lake is an example of the fact that they're still capable of first-tier core designs; they're just not (currently) capable of bringing them to market on a competitive process.Hifihedgehog - Tuesday, March 9, 2021 - link
They are 800-lbs on a fixed rations in self-imposed solitary confinement. Watch them slim down in a jiffy to as skinny as a rail if Alder Lake fails to impress. It was a slippery slope with Bulldozer. The only issue with Intel is the sheer amount of corporate waste. If they go down, others will be ready to swoop in and pick up the layoff broken pieces—pieces, once surrendered, that never again be recovered without a fight. Intel has never been fully challenged but they just might fall into Bulldozer-like obscurity this time around.GeoffreyA - Tuesday, March 9, 2021 - link
"self-imposed solitary confinement"Hard to believe how the tables have turned in a matter of four years, and worse for Intel, this isn't the slack, "we've done a good job, let's rest" AMD of the K8 days. This time round, they're relentlessly executing, with a vigour I don't remember them possessing. Whether it's Lisa or just the pain they went through in the Bulldozer days, I don't know, but it's magnificent to watch.