Intel Core i7-11700K Review: Blasting Off with Rocket Lake
by Dr. Ian Cutress on March 5, 2021 4:30 PM EST- Posted in
- CPUs
- Intel
- 14nm
- Xe-LP
- Rocket Lake
- Cypress Cove
- i7-11700K
CPU Tests: Encoding
One of the interesting elements on modern processors is encoding performance. This covers two main areas: encryption/decryption for secure data transfer, and video transcoding from one video format to another.
In the encrypt/decrypt scenario, how data is transferred and by what mechanism is pertinent to on-the-fly encryption of sensitive data - a process by which more modern devices are leaning to for software security.
Video transcoding as a tool to adjust the quality, file size and resolution of a video file has boomed in recent years, such as providing the optimum video for devices before consumption, or for game streamers who are wanting to upload the output from their video camera in real-time. As we move into live 3D video, this task will only get more strenuous, and it turns out that the performance of certain algorithms is a function of the input/output of the content.
HandBrake 1.32: Link
Video transcoding (both encode and decode) is a hot topic in performance metrics as more and more content is being created. First consideration is the standard in which the video is encoded, which can be lossless or lossy, trade performance for file-size, trade quality for file-size, or all of the above can increase encoding rates to help accelerate decoding rates. Alongside Google's favorite codecs, VP9 and AV1, there are others that are prominent: H264, the older codec, is practically everywhere and is designed to be optimized for 1080p video, and HEVC (or H.265) that is aimed to provide the same quality as H264 but at a lower file-size (or better quality for the same size). HEVC is important as 4K is streamed over the air, meaning less bits need to be transferred for the same quality content. There are other codecs coming to market designed for specific use cases all the time.
Handbrake is a favored tool for transcoding, with the later versions using copious amounts of newer APIs to take advantage of co-processors, like GPUs. It is available on Windows via an interface or can be accessed through the command-line, with the latter making our testing easier, with a redirection operator for the console output.
We take the compiled version of this 16-minute YouTube video about Russian CPUs at 1080p30 h264 and convert into three different files: (1) 480p30 ‘Discord’, (2) 720p30 ‘YouTube’, and (3) 4K60 HEVC.
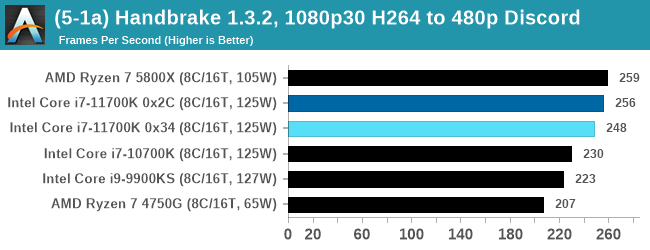
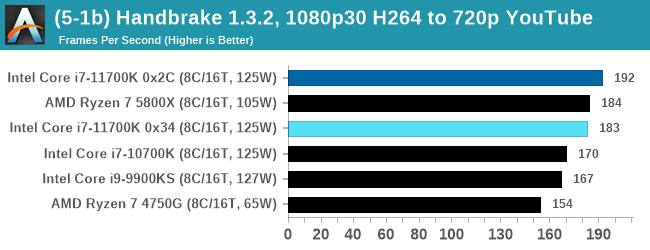
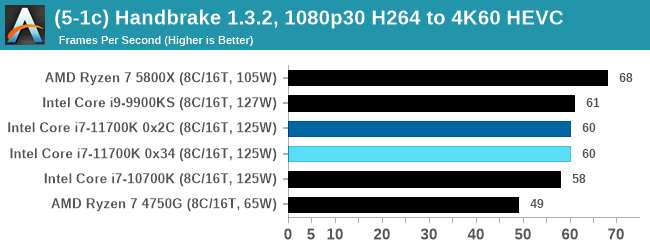
Up to the final 4K60 HEVC, in CPU-only mode, the Intel CPU puts up some good gen-on-gen numbers.
7-Zip 1900: Link
The first compression benchmark tool we use is the open-source 7-zip, which typically offers good scaling across multiple cores. 7-zip is the compression tool most cited by readers as one they would rather see benchmarks on, and the program includes a built-in benchmark tool for both compression and decompression.
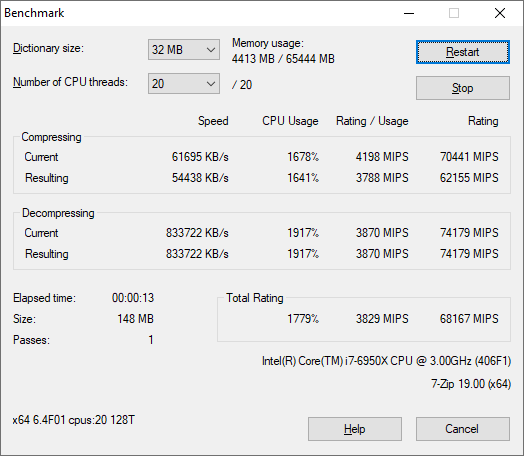
The tool can either be run from inside the software or through the command line. We take the latter route as it is easier to automate, obtain results, and put through our process. The command line flags available offer an option for repeated runs, and the output provides the average automatically through the console. We direct this output into a text file and regex the required values for compression, decompression, and a combined score.
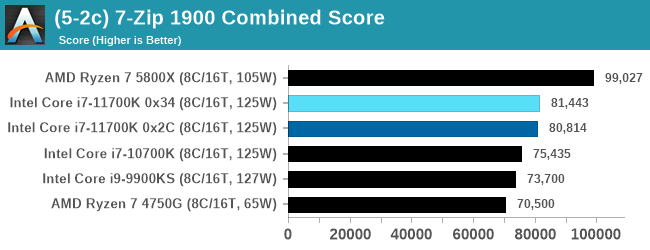
An increase over the previous generation, but AMD has a 25% lead.
AES Encoding
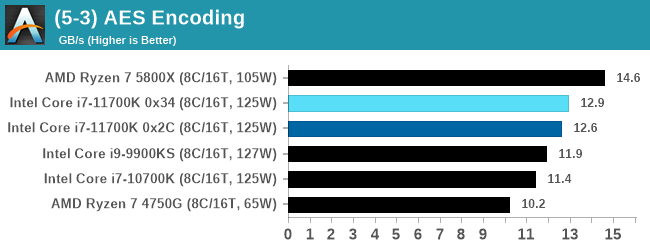
Algorithms using AES coding have spread far and wide as a ubiquitous tool for encryption. Again, this is another CPU limited test, and modern CPUs have special AES pathways to accelerate their performance. We often see scaling in both frequency and cores with this benchmark. We use the latest version of TrueCrypt and run its benchmark mode over 1GB of in-DRAM data. Results shown are the GB/s average of encryption and decryption.
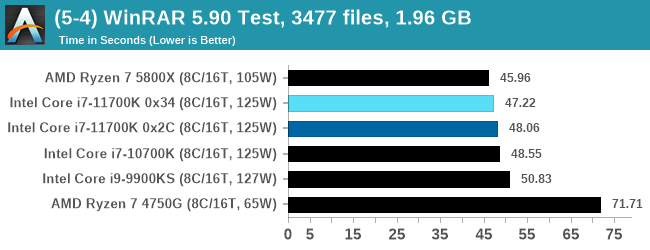
WinRAR 5.90: Link
For the 2020 test suite, we move to the latest version of WinRAR in our compression test. WinRAR in some quarters is more user friendly that 7-Zip, hence its inclusion. Rather than use a benchmark mode as we did with 7-Zip, here we take a set of files representative of a generic stack
- 33 video files , each 30 seconds, in 1.37 GB,
- 2834 smaller website files in 370 folders in 150 MB,
- 100 Beat Saber music tracks and input files, for 451 MB
This is a mixture of compressible and incompressible formats. The results shown are the time taken to encode the file. Due to DRAM caching, we run the test for 20 minutes times and take the average of the last five runs when the benchmark is in a steady state.
For automation, we use AHK’s internal timing tools from initiating the workload until the window closes signifying the end. This means the results are contained within AHK, with an average of the last 5 results being easy enough to calculate.
CPU Tests: Legacy and Web
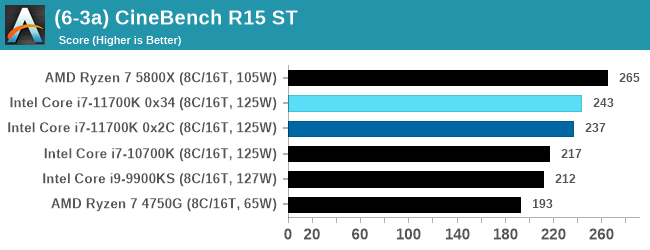
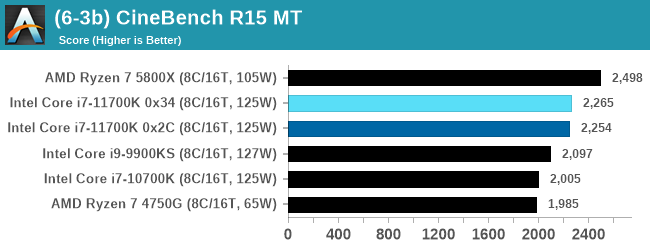
In order to gather data to compare with older benchmarks, we are still keeping a number of tests under our ‘legacy’ section. This includes all the former major versions of CineBench (R15, R11.5, R10) as well as x264 HD 3.0 and the first very naïve version of 3DPM v2.1. We won’t be transferring the data over from the old testing into Bench, otherwise it would be populated with 200 CPUs with only one data point, so it will fill up as we test more CPUs like the others.
The other section here is our web tests.
Web Tests: Kraken, Octane, and Speedometer
Benchmarking using web tools is always a bit difficult. Browsers change almost daily, and the way the web is used changes even quicker. While there is some scope for advanced computational based benchmarks, most users care about responsiveness, which requires a strong back-end to work quickly to provide on the front-end. The benchmarks we chose for our web tests are essentially industry standards – at least once upon a time.
It should be noted that for each test, the browser is closed and re-opened a new with a fresh cache. We use a fixed Chromium version for our tests with the update capabilities removed to ensure consistency.
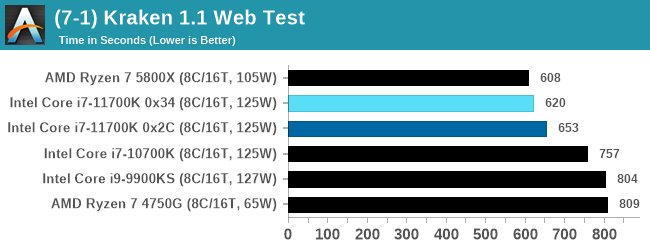
Mozilla Kraken 1.1
Kraken is a 2010 benchmark from Mozilla and does a series of JavaScript tests. These tests are a little more involved than previous tests, looking at artificial intelligence, audio manipulation, image manipulation, json parsing, and cryptographic functions. The benchmark starts with an initial download of data for the audio and imaging, and then runs through 10 times giving a timed result.

We loop through the 10-run test four times (so that’s a total of 40 runs), and average the four end-results. The result is given as time to complete the test, and we’re reaching a slow asymptotic limit with regards the highest IPC processors.
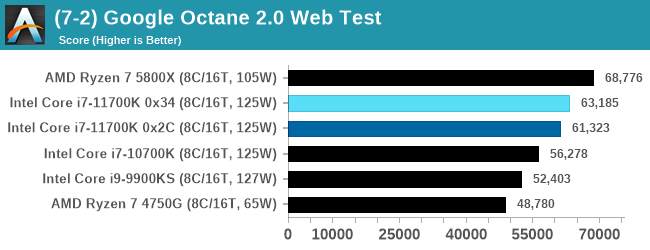
Google Octane 2.0
Our second test is also JavaScript based, but uses a lot more variation of newer JS techniques, such as object-oriented programming, kernel simulation, object creation/destruction, garbage collection, array manipulations, compiler latency and code execution.
Octane was developed after the discontinuation of other tests, with the goal of being more web-like than previous tests. It has been a popular benchmark, making it an obvious target for optimizations in the JavaScript engines. Ultimately it was retired in early 2017 due to this, although it is still widely used as a tool to determine general CPU performance in a number of web tasks.
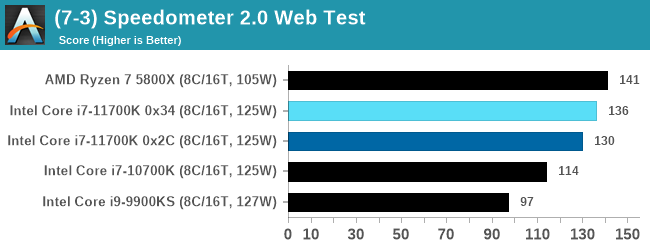
Speedometer 2: JavaScript Frameworks
Our newest web test is Speedometer 2, which is a test over a series of JavaScript frameworks to do three simple things: built a list, enable each item in the list, and remove the list. All the frameworks implement the same visual cues, but obviously apply them from different coding angles.
Our test goes through the list of frameworks, and produces a final score indicative of ‘rpm’, one of the benchmarks internal metrics.
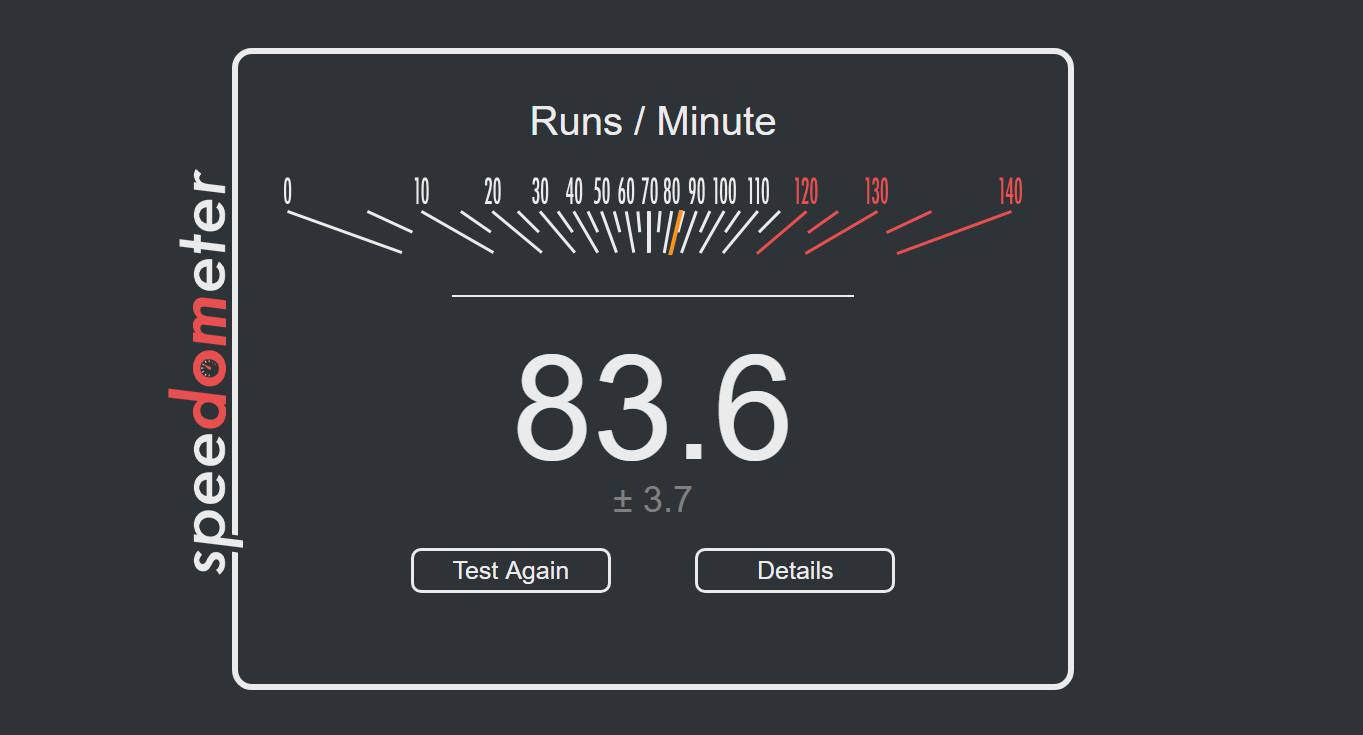
We repeat over the benchmark for a dozen loops, taking the average of the last five.
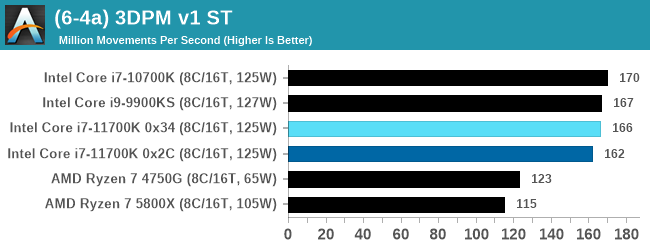
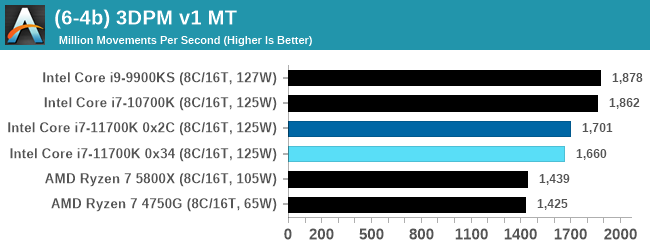
Legacy Tests








541 Comments
View All Comments
blppt - Saturday, March 13, 2021 - link
They did try to at least 'ride it out' until Zen could get done, and that required smoothing out the rough edges, so they did devote some resources.BD/PD never did any better than a low-end solution for the desktop/laptop market, but they had to offer something until Zen was done.
Oxford Guy - Sunday, March 28, 2021 - link
'They did try to at least 'ride it out' until Zen could get done, and that required smoothing out the rough edges, so they did devote some resources.'Wow... watch the goal posts move.
Riding out = doing nothing. Piledriver was not improved. The entire higher-performance & supercomputer market was unchanged from Piledriver to Zen. All AMD did was ship cheap knock-off APU rubbish and console trash.
The fact that AMD succeeded with Zen is probably mostly a testament to one largely ignored feature of monopoly power: the monopolist can become so slow and inefficient that a nearly dead competitor can come back to best it. That's not symptomatic of a well-run economic system. It's a trainwreck.
AMD should have been wealthy enough to do proper R&D and bulldozer would have never happened in the first place. But, Intel was a huge abusive monopolist and everyone went right along, content to feed the problem. After AMD did Bulldozer and Piledriver the company should have been dead. If there had been adequate competition it would have been. So, ironically, AMD can thank Intel for being its only competition, for resting on its laurels because of its extreme monopolization.
GeoffreyA - Wednesday, March 10, 2021 - link
Oxford Guy. I don't remember the exact details and am running largely from memory here. Yes, I agree, Bulldozer had far lower IPC than Phenom, but, according to their belief, was supposed to restore them to the top and knock Intel down. In practice, it failed miserably and was worse even than Netburst. Credit must be given, however, for their raising Bulldozer's IPC a lot each generation (something like 20-30% if I remember right), and curtailing power. It also addressed weaknesses in K10 and surpassed K10's IPC eventually. Anyway, working against such a hopeless design surely taught them a lot; and pouring that knowledge into a classic x86 design, Zen, took it further than Skylake after just one iteration.AMD would have done better had they just persisted with K10, which wasn't that far behind Nehalem. But, perhaps we wouldn't have had Zen: it took AMD's going through the lowest depths, passing through the fire as it were, to become what they are today, leaving Intel baffled. I agree, they were truly idiotic in the last decade but no more. May it stay that way!
Concerning CMT, I don't know much about it to comment, but think Bulldozer's principal weakness came from sharing execution units---the FP units I believe and others---between modules. Zen kept each core separate and gave it full (and weighty) resources, along with a micro-op cache and other improvements. As for Jaguar, it may be junk from a desktop point of view, yes, but was excellent in its domain and left Atom in the dust.
Oxford Guy - Sunday, March 28, 2021 - link
'Credit must be given, however, for their raising Bulldozer's IPC a lot each generation (something like 20-30% if I remember right), and curtailing power.'Piledriver was a small IPC improvement and regressed in AVX. Piledriver's AVX was so extremely poor that it was faster to not use it. Piledriver was a massive power hog. The 32nm SOI process node, according to 'TheStilt' was improved over time which is probably the main source of power efficiency improvement in Piledriver versus Bulldozer. I do not recall the IPC improvement of Piledriver over Bulldozer but it was nothing close to 20% I think. Instead, it merely made it possible to raise clocks further, along with the aforementioned node improvement. And, 'TheStilt' said the node got better after Piledriver's first generation. The 'E' parts, for instance, were quite a lot improved in leakage — but the whole line (other than the 9000 series which he said should have been sent to the scrapper) improved in leakage. What didn't improve, sadly, is the bad Piledriver design. AMD never bothered to fix it.
While Piledriver, when clocked high (like 4.7 GHz) could be relevant against Sandy in multi-thread (including well-threaded games like Desert of Kharak) it was extremely pitiful in single-thread. And, it sucked down boatloads of power to get to 4.7, even with the best-leakage chips.
And, going back to your 20–30% claim. Steamroller, which was considered a serious disappointment, featured only 4 of the CMT quasi cores, not 8. Excavator cut things in cache land even further. Both were cost-cutting parts, not performance improvements. Piledriver killed both of them simply by turning up the clocks high. The multi-thread performance of Steamroller and Excavator was not competitive because of the lack of cache, lack of cores, and lack of clock. Single-thread was a bit improved but, again, the only thing one could really do was blast current through Piledriver. It was a disgusting situation due to the single-threaded performance, which was unacceptable in 2012 and an abomination for the later years AMD kept peddling Piledriver in.
The only credit AMD deserves for the construction core period is not going out of business, despite trying so hard to do that.
GeoffreyA - Sunday, March 28, 2021 - link
Oxford Guy, while I respect your view, I do not agree with it, and still stand by my statement that AMD deserves credit for improving Bulldozer and executing yearly. Agreed, my 20-30% claim was not sober but I just meant it as a recollection and did qualify my statement.I don't think it's fair to put AMD down for embarking on Bulldozer. When they set out, quite likely they thought it was going to go further than the aging Phenom/K10 design, and the fact is, while falling behind in IPC compared with K10, it improved on a lot of points and laid the foundation. Its chief weakness was the idea of sharing resources, like the fetch, decode, and FP units, as well as going for a deeper pipeline. (The difference from Netburst is that Bulldozer was decently wide.)
Piledriver refined the foundation, raising IPC and adding a perceptron branch predictor, still used in Zen by the way, and I believe finally surpassed K10's IPC (and that of Llano). While being made on the same 32 nm process, it dropped power by switching to hard-edge flip flops, which took some work to put in. They used that lowered power to raise clock speeds, bringing power to the same level as Bulldozer. And Trinity, the Piledriver APU, surpassed Llano. I need to learn more about Steamroller and Excavator before I comment, but note in passing that SR improved the architecture again, giving each integer core its own fetch/decode units, among other things; and Excavator switched to GPU libraries in laying out the circuitry, dropping power and area, the tradeoff being lower frequency.
GeoffreyA - Sunday, March 28, 2021 - link
Also, the reviews show that things were not as bad as we remember, though power was terrible.https://www.anandtech.com/show/6396/the-vishera-re...
https://www.anandtech.com/show/5831/amd-trinity-re...
Oxford Guy - Tuesday, April 6, 2021 - link
I don't need to look at reviews agaih. I know how bad the IPC was in Bulldozer, Piledriver, Steamroller, and Excavator. Single-thread in Cinebench R15, for instance, was really low even at 5.2 GHz in Piledriver. It takes chilled water to get it to bench at that clock.GeoffreyA - Wednesday, March 10, 2021 - link
Lack of competition, high prices, lack of integrity. I agree it's one big mess, but there's so little we can do, except boycotting their products. As it stands, the best advice is likely: find a product at a decent price, buy it, be happy, and let these rotten companies do what they want.Oxford Guy - Sunday, March 28, 2021 - link
'find a product at a decent price, buy it, be happy'Buy a product you can't buy so you can prop up monopolies that cause the problem of shortage + bad pricing + low choice (features to choose from/i.e. innovation, limited).
GeoffreyA - Sunday, March 28, 2021 - link
The only solution is a worldwide boycott of their products, till they drop their prices, etc.