Intel 12th Gen Core Alder Lake for Desktops: Top SKUs Only, Coming November 4th
by Dr. Ian Cutress on October 27, 2021 12:00 PM EST- Posted in
- CPUs
- Intel
- DDR4
- DDR5
- PCIe 5.0
- Alder Lake
- Intel 7
- 12th Gen Core
- Z690
A Hybrid/Heterogeneous Design
Developing a processor with two different types of core is not a new concept – there are billions of smartphones that have exactly that inside them, running Android or iOS, as well as IoT and embedded systems. We’ve also seen it on Windows, cropping up on Qualcomm’s Windows on Snapdragon mobile notebooks, as well as Intel’s previous Lakefield design. Lakefield was the first x86 hybrid design in that context, and Alder Lake is the more mass-market realization of that plan.
A processor with two different types of core disrupts the typical view of how we might assume a computer works. At the basic level, it has been taught that a modern machine is consistent – every CPU has the same performance, processes the same data at the same rate, has the same latency to memory, the same latency to each other, and everything is equal. This is a straightforward homogenous design that’s very easy to write software for.
Once we start considering that not every core has the same latency to memory, moving up to a situation where there are different aspects of a chip that do different things at different speeds and efficiencies, now we move into a heterogeneous design scenario. In this instance, it becomes more complex to understand what resources are available, and how to use them in the best light. Obviously, it makes sense to make it all transparent to the user.

With Intel’s Alder Lake, we have two types of cores: high performance/P-cores, built on the Golden Cove microarchitecture, and high efficiency/E-cores, built on the Gracemont microarchitecture. Each of these cores are designed for different optimization points – P-cores have a super-wide performance window and go for peak performance, while E-cores focus on saving power at half the frequency, or lower, where the P-core might be inefficient.
This means that if there is a background task waiting on data, or something that isn’t latency-sensitive, it can work on the E-cores in the background and save power. When a user needs speed and power, the system can load up the P-cores with work so it can finish the fastest. Alternatively, if a workload is more throughput sensitive than latency-sensitive, it can be split across both P-cores and E-cores for peak throughput.

For performance, Intel lists a single P-core as ~19% better than a core in Rocket Lake 11th Gen, while a single E-core can offer better performance than a Comet Lake 10th Gen core. Efficiency is similarly aimed to be competitive, with Intel saying a Core i9-12900K with all 16C/24T running at a fixed 65 W will equal its previous generation Core i9-11900K 8C/16T flagship at 250 W. A lot of that will be that having more cores at a lower frequency is more efficient than a few cores at peak frequency (as we see in GPUs), however an effective 4x performance per watt improvement requires deeper investigation in our review.
As a result, the P-cores and E-cores look very different. A deeper explanation can be found in our Alder Lake microarchitecture deep dive, but the E-cores end up being much smaller, such that four of them are roughly in the same area as a single P-core. This creates an interesting dynamic, as Intel highlighted back at its Architecture Day: A single P-core provides the best latency-sensitive performance, but a group of E-cores would beat a P-core in performance per watt, arguably at the same performance level.
However, one big question in all of this is how these workloads end up on the right cores in the first place? Enter Thread Director (more on the next page).
A Word on L1, L2, and L3 Cache
Users with an astute eye will notice that Intel’s diagrams relating to core counts and cache amounts are representations, and some of the numbers on a deeper inspection need some explanation.
For the cores, the processor design is physically split into 10 segments.
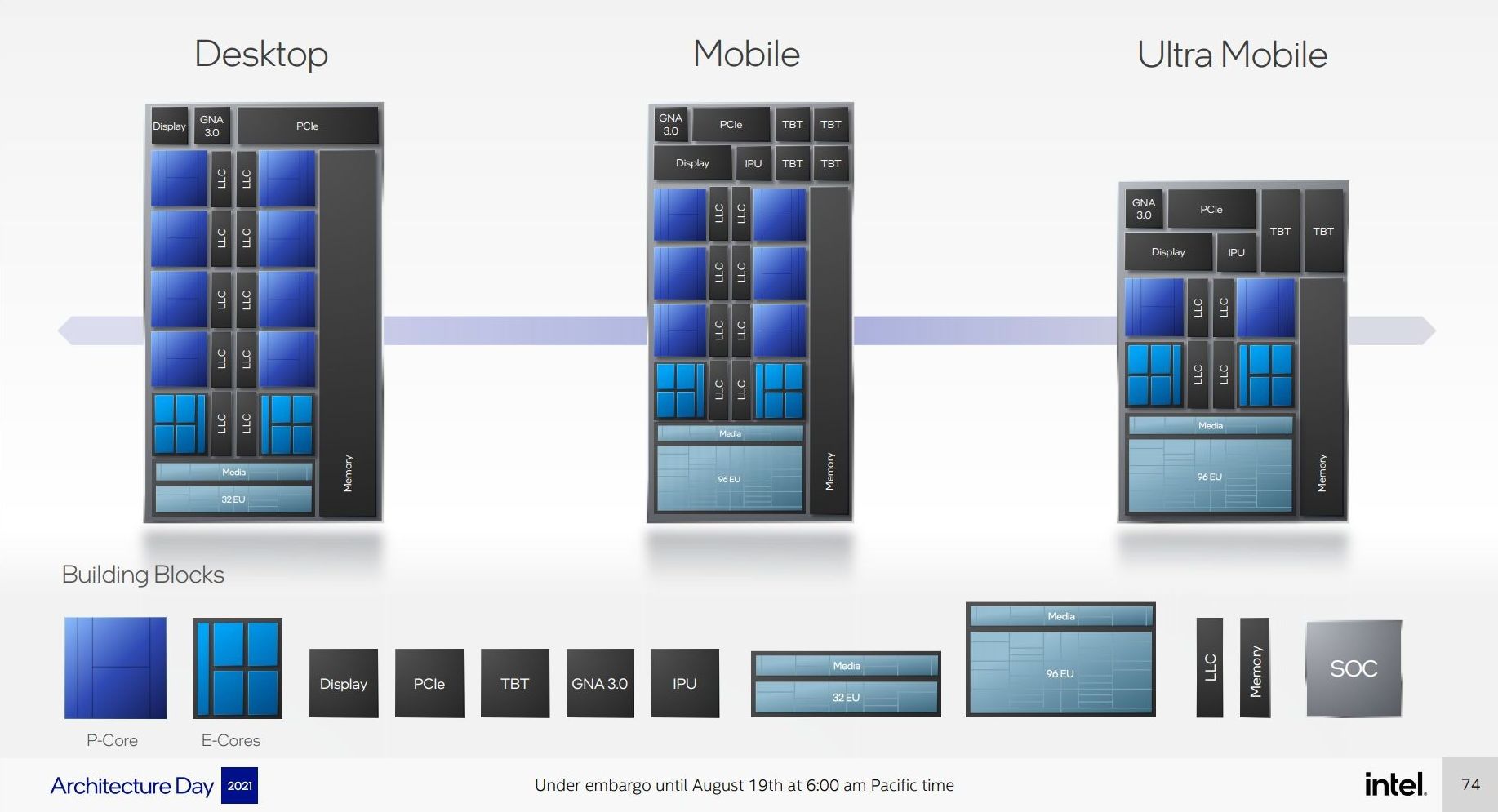
A segment contains either a P-core or a set of four E-cores, due to their relative size and functionality. Each P-core has 1.25 MiB of private L2 cache, which a group of four E-cores has 2 MiB of shared L2 cache.
This is backed by a large shared L3 cache, totaling 30 MiB. Intel’s diagram shows that there are 10 LLC segments which should mean 3.0 MiB each, right? However, moving from Core i9 to Core i7, we only lose one segment (one group of four E-cores), so how come 5.0 MiB is lost from the total L3? Looking at the processor tables makes less sense.
Please note that the following is conjecture; we're awaiting confirmation from Intel that this is indeed the case.
It’s because there are more than 10 LLC slices – there’s actually 12 of them, and they’re each 2.5 MiB. It’s likely that either each group of E-cores has two slices each, or there are extra ring stops for more cache.
Each of the P-cores has a 2.5 MiB slice of L3 cache, with eight cores making 20 MiB of the total. This leaves 10 MiB between two groups of four E-cores, suggesting that either each group has 5.0 MiB of L3 cache split into two 2.5 MiB slices, or there are two extra LLC slices on Intel’s interconnect.
| Alder Lake Cache | |||||||
| AnandTech | Cores P+E/T |
L2 Cache |
L3 Cache |
IGP | Base W |
Turbo W |
Price $1ku |
| i9-12900K | 8+8/24 | 8x1.25 2x2.00 |
30 | 770 | 125 | 241 | $589 |
| i9-12900KF | 8+8/24 | 8x1.25 2x2.00 |
30 | - | 125 | 241 | $564 |
| i7-12700K | 8+4/20 | 8x1.25 1x2.00 |
25 | 770 | 125 | 190 | $409 |
| i7-12700KF | 8+4/20 | 8x1.25 1x2.00 |
25 | - | 125 | 190 | $384 |
| i5-12600K | 6+4/20 | 6x1.25 1x2.00 |
20 | 770 | 125 | 150 | $289 |
| i5-12600KF | 6+4/20 | 6.125 1x200 |
20 | - | 125 | 150 | $264 |
This is important because moving from Core i9 to Core i7, we lose 4xE-cores, but also lose 5.0 MiB of L3 cache, making 25 MiB as listed in the table. Then from Core i7 to Core i5, two P-cores are lost, totaling another 5.0 MiB of L3 cache, going down to 20 MiB. So while Intel’s diagram shows 10 distinct core/LLC segments, there are actually 12. I suspect that if both sets of E-cores are disabled, so we end up with a processor with eight P-cores, 20 MiB of L3 cache will be shown.








395 Comments
View All Comments
Spunjji - Friday, October 29, 2021 - link
62MTr/mm^2 (Renoir) vs 53MTr/mm^2 (Ice Lake).Efficiency comparisons between those two chips aren't flattering, either - same goes for Tiger Lake and Cezanne. If you limit both to 15W, AMD win more often than not. Intel need 28W+ (4C) and 60W+ (8C) to open up a performance lead.
Wrs - Saturday, October 30, 2021 - link
Comparing apples and oranges. Renoir was 8 Zen2 cores with HT disabled. Ice Lake-U was 4 Sunny Cove with HT enabled. Of course Renoir was better at MT, but slower at ST. It's a basic design tradeoff. An exaggerated example would be Intel shipping 12 Atom cores instead of 4 Willow Cove. Similar die area, but higher efficiency! Also more complaints about slowdowns.Also note Zen3's are on the same process as Zen 2, whereas ADL is on a newer process than I
Wrs - Thursday, October 28, 2021 - link
And the power density difference is obvious and deliberate. Zen3 power is concentrated on the CCDs, ADL on the other hand is one piece of silicon over twice the size. Then measure the elevation difference between PCB and IHS on a Ryzen 5000, compare to reviewers doing the same on ADL. Thinner interface = better heat dissipation. That assumes other factors equal. Intel specifically talks about thin solder and thicker IHS, which is a further bonus because copper IHS has 5x the thermal conductivity of indium solder.Oxford Guy - Thursday, October 28, 2021 - link
Indium is also expensive and a depleting resource. Copper is rather more abundant.mode_13h - Friday, October 29, 2021 - link
Is it plausible that the thick IHS is there mostly as extra thermal mass to facilitate the PL2 turbo boost?I wonder if we'll ever see a CPU use a vapor chamber instead of solder + IHS. Just etch capillaries directly into the die surface and use some non-conductive liquid. Even solid copper is no match for the thermal conductivity of a vapor chamber!
Wrs - Tuesday, November 2, 2021 - link
@mode_13h The thicker IHS is to reduce the bending moment, to compensate for the thinner solder leaving the die more fragile. Solder is a soft metal, but the chip is ceramic, cracks like a ceramic tile. And if they needed more thermal mass they'd fill in the void between IHS and substrate, where the chip isn't.On the vapor chamber idea... install heatsink wrong, chip explodes?
mode_13h - Friday, November 5, 2021 - link
> if they needed more thermal mass they'd fill in the void between IHS and substrate,> where the chip isn't.
Compared to the added volume of the IHS, I don't see that extra space as being very significant.
> On the vapor chamber idea... install heatsink wrong, chip explodes?
Huh? Vapor chambers are like heat pipes. Yes, it'd have to be mechanically strong, but I don't see why this approach would be significantly weaker than the CPUs we have today. And so what you're saying is that if you push down too hard on this, it'd fail just like if you push down too hard on a conventional CPUs. The risk is in breaking the substrate.
Now, if you don't know about heatpipes, they're significantly *below* atmospheric pressure, at room temperature. So, while a CPU is cold, the real risk would be cracking it and creating a leak. The fluid would have to be something not terribly hazardous, in case it did leak out. However, I think phase-change cooling systems already commonly employ relatively benign fluids for similar purposes.
Spunjji - Friday, October 29, 2021 - link
I'm aware of how these things work. As I said on your other comments, Intel are doing these things (die thinning, solder thinning) because they have to, thanks to the amount of power they need to dissipate to stay competitive. Up until Comet Lake they were slapping thermal paste under the IHS and calling it a day. I approve of these changes and I have little doubt that AMD will start implementing similar techniques as and when they need to (TDPs in general are on an upward trend).GC2:CS - Wednesday, October 27, 2021 - link
Well exciting times coming up will all the new CPU competition ramping up.I am jsut curious how can the “little core” drop off only about 20% perf while being 1/4 the size ?
That is not a little core at all. More like lower clocked P core. If I remember corectly Apple little cores are only 1/3 of P cores and quite insignificant in MT workloads.
nandnandnand - Wednesday, October 27, 2021 - link
Who knows. I think we still need official word or die shots to confirm the relative die size of the efficiency cores. They have 40% of the L2 cache and no hyper-threading which should make a difference."A segment contains either a P-core or a set of four E-cores, due to their relative size and functionality. Each P-core has 1.25 MiB of private L2 cache, which a group of four E-cores has 2 MiB of shared L2 cache."