PCI Express 6.0 Specification Finalized: x16 Slots to Reach 128GBps
by Ryan Smith on January 11, 2022 12:00 PM EST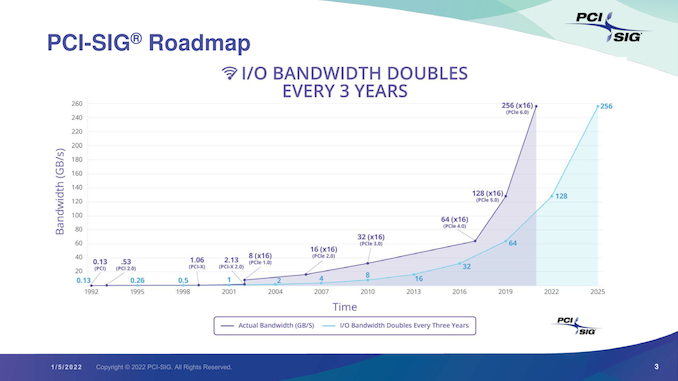
This morning the PCI Special Interest Group (PCI-SIG) is releasing the much-awaited final (1.0) specification for PCI Express 6.0. The next generation of the ubiquitous bus is once again doubling the data rate of a PCIe lane, bringing it to 8GB/second in each direction – and far, far higher for multi-lane configurations. With the final version of the specification now sorted and approved, the group expects the first commercial hardware to hit the market in 12-18 months, which in practice means it should start showing up in servers in 2023.
First announced in the summer of 2019, PCI Express 6.0 is, as the name implies, the immediate follow-up to the current-generation PCIe 5.0 specification. Having made it their goal to keep doubling PCIe bandwidth roughly every 3 years, the PCI-SIG almost immediately set about work on PCIe 6.0 once the 5.0 specification was completed, looking at ways to once again double the bandwidth of PCIe. The product of those development efforts is the new PCIe 6.0 spec, and while the group has missed their original goal of a late 2021 release by mere weeks, today they are announcing that the specification has been finalized and is being released to the group’s members.
As always, the creation of an even faster version of PCIe technology has been driven by the insatiable bandwidth needs of the industry. The amount of data being moved by graphics cards, accelerators, network cards, SSDs, and other PCIe devices only continues to increase, and thus so must bus speeds to keep these devices fed. As with past versions of the standard, the immediate demand for the faster specification comes from server operators, whom are already regularly using large amounts of high-speed hardware. But in due time the technology should filter down to consumer devices (i.e. PCs) as well.
By doubling the speed of a PCIe link, PCIe 6.0 is an across-the-board doubling of bandwidth rates. X1 links move from 4GB/second/direction to 8GB/second/direction, and that scales all the way up to 128GB/second/direction for a full x16 link. For devices that are already suturing a link of a given width, the extra bandwidth represents a significant increase in bus limits; meanwhile for devices that aren’t yet saturating a link, PCIe 6.0 offers an opportunity to reduce the width of a link, maintaining the same bandwidth while bringing down hardware costs.
| PCI Express Bandwidth (Full Duplex: GB/second/direction) |
||||||||
| Slot Width | PCIe 1.0 (2003) |
PCIe 2.0 (2007) |
PCIe 3.0 (2010) |
PCIe 4.0 (2017) |
PCIe 5.0 (2019) |
PCIe 6.0 (2022) |
||
| x1 | 0.25GB/sec | 0.5GB/sec | ~1GB/sec | ~2GB/sec | ~4GB/sec | 8GB/sec | ||
| x2 | 0.5GB/sec | 1GB/sec | ~2GB/sec | ~4GB/sec | ~8GB/sec | 16GB/sec | ||
| x4 | 1GB/sec | 2GB/sec | ~4GB/sec | ~8GB/sec | ~16GB/sec | 32GB/sec | ||
| x8 | 2GB/sec | 4GB/sec | ~8GB/sec | ~16GB/sec | ~32GB/sec | 64GB/sec | ||
| x16 | 4GB/sec | 8GB/sec | ~16GB/sec | ~32GB/sec | ~64GB/sec | 128GB/sec | ||
PCI Express was first launched in 2003, and today’s 6.0 release essentially marks the third major revision of the technology. Whereas PCIe 4.0 and 5.0 were “merely” extensions to earlier signaling methods – specifically, continuing to use PCIe 3.0’s 128b/130b signaling with NRZ – PCIe 6.0 undertakes a more significant overhaul, arguably the largest in the history of the standard.
In order to pull of another bandwidth doubling, the PCI-SIG has upended the signaling technology entirely, moving from the Non-Return-to-Zero (NRZ) tech used since the beginning, and to Pulse-Amplitude Modulation 4 (PAM4).
As we wrote at the time that development on PCIe 6.0 was first announced:
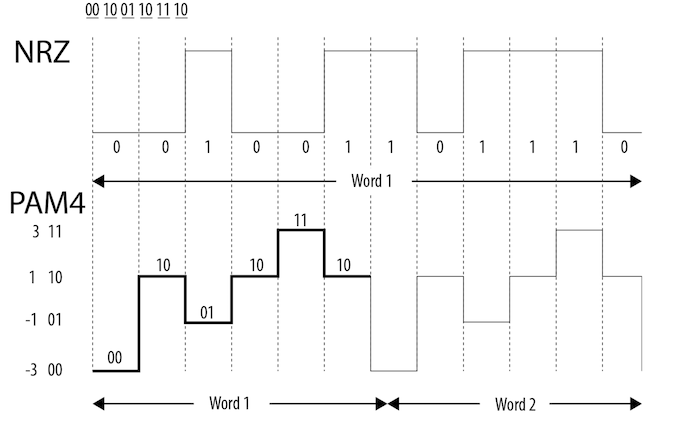
PAM4 itself is not a new technology, but up until now it’s been the domain of ultra-high-end networking standards like 200G Ethernet, where the amount of space available for more physical channels is even more limited. As a result, the industry already has a few years of experience working with the signaling standard, and with their own bandwidth needs continuing to grow, the PCI-SIG has decided to bring it inside the chassis by basing the next generation of PCIe upon it.
The tradeoff for using PAM4 is of course cost. Even with its greater bandwidth per Hz, PAM4 currently costs more to implement at pretty much every level, from the PHY to the physical layer. Which is why it hasn’t taken the world by storm, and why NRZ continues to be used elsewhere. The sheer mass deployment scale of PCIe will of course help a lot here – economies of scale still count for a lot – but it will be interesting to see where things stand in a few years once PCIe 6.0 is in the middle of ramping up.
Meanwhile, not unlike the MLC NAND in my earlier analogy, because of the additional signal states a PAM4 signal itself is more fragile than a NRZ signal. And this means that along with PAM4, for the first time in PCIe’s history the standard is also getting Forward Error Correction (FEC). Living up to its name, Forward Error Correction is a means of correcting signal errors in a link by supplying a constant stream of error correction data, and it’s already commonly used in situations where data integrity is critical and there’s no time for a retransmission (such as DisplayPort 1.4 w/DSC). While FEC hasn’t been necessary for PCIe until now, PAM4’s fragility is going to change that. The inclusion of FEC shouldn’t make a noticeable difference to end-users, but for the PCI-SIG it’s another design requirement to contend with. In particular, the group needs to make sure that their FEC implementation is low-latency while still being appropriately robust, as PCIe users won’t want a significant increase in PCIe’s latency.
It’s worth noting that FEC is also being paired with Cyclic Redundancy Checking (CRC) as a final layer of defense against bit errors. Packets that, even after FEC still fail a CRC – and thus are still corrupt – will trigger a full retransmission of the packet.
The upshot of the switch to PAM4 then is that by increasing the amount of data transmitted without increasing the frequency, the signal loss requirements won’t go up. PCIe 6.0 will have the same 36dB loss as PCIe 5.0, meaning that while trace lengths aren’t officially defined by the standard, a PCIe 6.0 link should be able to reach just as far as a PCIe 5.0 link. Which, coming from PCIe 5.0, is no doubt a relief to vendors and engineers alike.
Alongside PAM4 and FEC, the final major technological addition to PCIe 6.0 is its FLow control unIT (FLIT) encoding method. Not to be confused with PAM4, which is at the physical layer, FLIT encoding is employed at the logical level to break up data into fixed-size packets. It’s by moving the logical layer to fixed size packets that PCIe 6.0 is able to implement FEC and other error correction methods, as these methods require said fixed-size packets. FLIT encoding itself is not a new technology, but like PAM4, is essentially being borrowed from the realm of high-speed networking, where it’s already used. And, according to the PCI-SIG, it’s one of the most important pieces of the specification, as it’s the key piece to enabling (continued) low-latency operation of PCIe with FEC, as well as allowing for very minimal overhead. All told, PCI-SIG considers PCIe 6.0 encoding to be a 1b/1b encoding method, as there’s no overhead in the data encoding itself (there is however overhead in the form of additional FEC/CRC packets).

As it’s more of an enabling piece than a feature of the specification, FLIT encoding should be fairly invisible to users. However, it’s important to note that the PCI-SIG considered it important/useful enough that FLIT encoding is also being backported in a sense to lower link rates; once FLIT is enabled on a link, a link will remain in FLIT mode at all times, even if the link rate is negotiated down. So, for example, if a PCIe 6.0 graphics card were to drop from a 64 GT/s (PCIe 6.0) rate to a 2.5GT/s (PCIe 1.x) rate to save power at idle, the link itself will still be operating in FLIT mode, rather than going back to a full PCIe 1.x style link. This both simplifies the design of the spec (not having to renegotiate connections beyond the link rate) and allows all link rates to benefit from the low latency and low overhead of FLIT.
As always, PCIe 6.0 is backwards compatible with earlier specifications; so older devices will work in newer hosts, and newer devices will work in older hosts. As well, the current forms of connectors remain supported, including the ubiquitous PCIe card edge connector. So while support for the specification will need to be built into newer generations of devices, it should be a relatively straightforward transition, just like previous generations of the technology.

Unfortunately, the PCI-SIG hasn’t been able to give us much in the way of guidance on what this means for implementations, particularly in consumer systems – the group just makes the standard, it’s up to hardware vendors to implement it. Because the switch to PAM4 means that the amount of signal loss for a given trace length hasn’t gone up, conceptually, placing PCIe 6.0 slots should be about as flexible as placing PCIe 5.0 slots. That said, we’re going to have to wait and see what AMD and Intel devise over the next few years. Being able to do something, and being able to do it on a consumer hardware budget are not always the same thing.
Wrapping things up, with the PCIe 6.0 specification finally completed, the PCI-SIG tells us that, based on previous adoption timelines, we should start seeing PCIe 6.0 compliant hardware hit the market in 12-18 months. In practice this means that we should see the first server gear next year, and then perhaps another year or two for consumer gear.






Source: PCI-SIG








77 Comments
View All Comments
Ethos Evoss - Thursday, January 13, 2022 - link
Of course it is not new technology and they on purpose didn't implemented it earlier because they making money and not rushing for ordinary customersTo skip speed straight away..
They already have done even pcie7 or pcie 8 but they won't tell you they keeping it for later.. Just to keep business going
mode_13h - Thursday, January 13, 2022 - link
Do you have any evidence to support those claims, or merely cynicism?The PCI-SIG is not a secret society. They have many members and are quite public about their progress. Indeed, it's in their interest to do so.
https://pcisig.com/newsroom
Are you aware that technology move incrementally for *reasons*? Faster interconnect standards depend on numerous technological advancements, most notably advancements in semiconductor fabrication. That stuff takes time. And then, once the technological foundations are in place, engineers have to work out reliable and cost-effective ways to use it. After that, companies need to build and test IP, supporting chips (like retimers and switches), and even the test equipment, itself. Finally, end-products can come to market that embrace the new standard. All of that takes a lot of time, and you can't really speed it up any further, without exponentially increasing development costs while probably only hastening the pace of advancements a little bit.
Finally, PCIe derives its benefit from its incredibly wide adoption. It's an example of the "network-effect" in action. This further complicates the standardization, implementation, and testing phases, but it's more than worth it, in order to have such incredibly wide compatibility across devices and generations. About the only thing I can think of that's in the same league as PCIe is Ethernet.
mode_13h - Thursday, January 13, 2022 - link
I thought of another point, which is that even *if* the technology existed to go straight from PCIe 3.0 to what we have in 5.0, in a cost-effective way, or to skip 5 and go to 6, or to condense the sequence of 4, 5, 6 into 2 iterations, there's a further benefit from moving it a deliberate and step-wise manner.The rationale is that you can find many *new* products shipping with only PCIe 2.0 or 3.0, for instance. Particularly embedded CPUs and ASICs made on an older process node, or where energy-efficiency is at a greater premium. It's therefore fundamentally worthwhile to have a ladder where the gaps between the rungs aren't too wide, so that each product can rather precisely dial in the spec that makes the most sense for it.
Also, a fairly even doubling in speeds makes life simpler when you're dealing with lane aggregation, splitting, step-downs, etc.
GNUminex_l_cowsay - Monday, February 7, 2022 - link
>As always, PCIe 6.0 is backwards compatible with earlier specifications; so older devices will work in newer hosts, and newer devices will work in older hosts.Correction. Newer devices might work in older hosts; depending on the features used in the device and whether the vendor chooses to implement backwards compatibility. Let's not forget that PCIe 2.2+ allows greater power draw than 2.0 and a new packet format that results in newer devices not always working in older hosts even if they can work with newer hosts running in lower pcie version modes.
pogsnet - Monday, February 7, 2022 - link
We haven't fully utilized PCIe 5.0 now we have 6. That's too fast. Our hardware is already obsolete before we bought them :(penguinslovebananas - Monday, April 18, 2022 - link
Like so many have said before we are hitting a real limit to what can be accomplished with copper interconnects. A look at modern networking is a good demonstration of this fact. Ethernet connections using 25g or higher require optical transmission for any meaningful length beyond a single rack. While DAC, direct attach copper, cables, using coax or biaxial cabling, are possible, they are much more expensive, less modular, and come with severe length restrictions, limiting their use to inter-rack components. When the 10G BASE-T, 10 gig Ethernet over twisted pair, standard was released I remember reading predictions, it would be the last stop for BASE-T, although 25G BASE-T does exist, I have never seen actual hardware. The integration of optical interconnects into pc hardware, on pcbs; motherboards, between cpus and even for internet to external, are a major focus of current research and many prototypes have been demonstrated with commercialization, I predict, within 5, but likely closer to 3, especially in the data center space. I think the major push to get to PCIE 6 was to enable cache coherent technology, CLX CCIX etc., which will completely revolutionize the cloud, data center,HPC computing landscape. With CLX as an example, with PCIE 5 enabling the first version 1.1, major uplift will come with version 2.0. CXL 2.0 allows switching, connecting multiple devices to one host, and pooling, one/multiple devices to multiple hosts, in addition to encryption and various integrity/root of trust methods. This will allow the major change in computer architecture I mentioned. Memory pooling, both conventional, and PCIE card based, think of it like a JBOD, but for memory instead of storage, will be a major use case. TLDR CXL 2.0 will make all aspects of servers disaggregated. Does your organization need to expand memory, get one of the devices I describe above, good on memory, but lacking in compute, get devices that do only that, storage, same, get the idea? With this disaggregation manufactures will be able to specialize single task products, bringing greatly improved performance/efficiency from the ability to optimize those products to their sole function instead of moderate performance on multiple functions. One can only imagine the possible ways to take advantage of this technology. Now that we have a roadmap, through PCIE 6, that enables full implementation of CXL, the timeline to the next standard can afford to wait a little longer for optical interconnects to come to market and mature.penguinslovebananas - Monday, April 18, 2022 - link
BTW, to anyone who think it is a conspiracy to make more money. PCI-SIG is a nonprofit and not a manufacturer or producer of anything aside from the standards themselves. The individuals design these standards are experts in their particular field, with some being the top, and you would be hard pressed to find a tech expert who would intentionally advocate for the halting of progress. In addition to the highly respected individuals who do the day to day, many hundreds of companies, I think it is getting close to 1000, are members of PCI-SIG. it is simply not possible to get that many diverse organizations cooperating at a level high enough for a plot of this magnitude to take place.