Real-world virtualization benchmarking: the best server CPUs compared
by Johan De Gelas on May 21, 2009 3:00 AM EST- Posted in
- IT Computing
Analysis: "Nehalem" vs. "Shanghai"
The Xeon X5570 outperforms the best Opterons by 20% and 17% of the gain comes from Hyper-Threading. That's decent but not earth shattering. Let us first set expectations. What should we have expected from the Xeon X5570? We can get a first idea by looking at the "native" (non-virtualized) scores of the individual workloads. Our last Server CPU roundup showed us that the Xeon X5570 2.93GHz is (compared to a Xeon E5450 3GHz):
- 94% faster in Oracle Calling Circle
- 107% faster in a OLAP SQL Server benchmark
- 36% faster on the MCS eFMS web portal test
If we would simply take a geometric mean of these benchmarks and forget we are running on top of a hypervisor, we would expect a 65% advantage for the Xeon X5570. Our virtualization benchmark shows a 31% advantage for the Xeon X5570 over the Xeon 5450. What happened?
It seems like all the advantages of the new platforms such as fast CPU interconnects, NUMA, integrated memory controllers, and L3 caches for fast syncing have evaporated. In a way, this is the case. You have probably noticed the second flaw (besides ignoring the hypervisor) in the reasoning above. That second flaw consists in the fact that the "native scores" in our server CPU roundup are obtained on eight (16 logical) physical cores. Assuming that four virtual CPUs will show the same picture is indeed inaccurate. The effect of fast CPU interconnects, NUMA, and massive bandwidth increases will be much less in a virtualized environment where you limit each application to four CPUs. In this situation, if the ESX scheduler is smart (and that is the case) it will not have to sync between L3 caches and CPU sockets. In our native benchmarks, the application has to scale to eight CPUs and has to keep the caches coherent over two sockets. This is the first reason for the less than expected performance gain: the Xeon 5570 cannot leverage some of its advantages such as much quicker "syncing".
The fact that we are running on a hypervisor should give the Xeon X5570 a boost. The Nehalem architecture switches about 40% quicker back and forth to the hypervisor than the Xeon 54xx. It cannot leverage its best weapon though: Extended Page Tables are not yet supported in ESX 3.5 Update 4. They are supported in vSphere's ESX 4.0, which immediately explains why OEMs prefer to run VMmark on ESX 4.0. Most of our sources tell us that EPT gives a boost of about 25%. To understand this fully, you should look at our Hardware virtualization: the nuts and bolts article. The table below tells what mode the VMM (Virtual Machine Monitor), a part of the hypervisor, runs. To refresh your memory:
- SVM: Secure Virtual Machine, hardware virtualization for the AMD Opteron
- VT-x: Same for the Intel Xeon
- RVI: also called nested paging or hardware assisted paging (AMD)
- EPT: Extended Page Tables or hardware assisted paging (Intel)
- Binary Translation: well tweaked software virtualization that runs on every CPU, developed by VMware
| Hypervisor VMM Mode | ||
| ESX 3.5 Update 4 | 64-bit OLTP & OLAP VMs | 32-bit Web portal VM |
| Quad-core Opterons | SVM + RVI | SVM + RVI |
| Xeon 55xx | VT-x | Binary Translation |
| Xeon 53xx, 54xx | VT-x | Binary Translation |
| Dual-core Opterons | Binary Translation | Binary Translation |
| Dual-core Xeon 50xx | VT-x | Binary Translation |
Thanks to being first with hardware-assisted paging, AMD gets a serious advantage in ESX 3.5: it can always leverage all of its virtualization technologies. Intel can only use VT-x with the 64-bit Guest OS. The early VT-x implementations were pretty slow, and VMware abandoned VT-x for 32-bit guest OS as binary translation was faster in a lot of cases. The prime reason why VMware didn't ditch VT-x altogether was the fact that Intel does not support segments -- a must for binary translation -- in x64 (EM64T) mode. This makes VT-x or hardware virtualization the only option for 64-bit guests. Still, the mediocre performance of VT-x on older Xeons punishes the Xeon X5570 in 32-bit OSes, which is faster with VT-x than with binary translation as we will see further.
So how much performance does the AMD Opteron extract from the improved VMM modes? We checked by either forcing or forbidding the use of "Hardware Page Table Virtualization", also called Hardware Virtualized MMU, EPT, NPT, RVI, or HAP.
 |
Let's first look at the AMD Opteron 8389 2.9GHz. When you disable RVI, memory page management is handled the same as all the other "privileged instructions" with hardware virtualization: it causes exceptions that make the hypervisor intervene. Each time you get a world switch towards the hypervisor. Disabling RVI makes the impact of world switches more important. When you enable RVI, the VMM exposes all page tables (Virtual, Guest Physical, and "machine" physical) to the CPU. It is no longer necessary to generate (costly) exceptions and switches to the hypervisor code.
However, filling the TLB is very costly with RVI. When a certain logical page address or virtual address misses the TLB, the CPU performs a lookup in the guest OS page tables. Instead of the right physical address, you get a "Guest Physical address", which is in fact a virtual address. The CPU has to search the Nested Pages ("Guest Physical" to "Real Physical") for the real physical address, and it does this for each table lookup.
To cut a long story short, it is very important to keep the percentage of TLB hits as high as possible. One way to do this is to decrease the number of memory pages with "large pages". Large pages mean that your memory is divided into 2MB pages (x86-64, x86-32 PAE) instead of 4KB. This means that Shanghai's L1 TLB can cover 96MB data (48 entries times 2MB) instead of 192 KB! Therefore, if there are a lot of memory management operations, it might be a good idea to enable large pages. Both the application and the OS must support this to give good results.
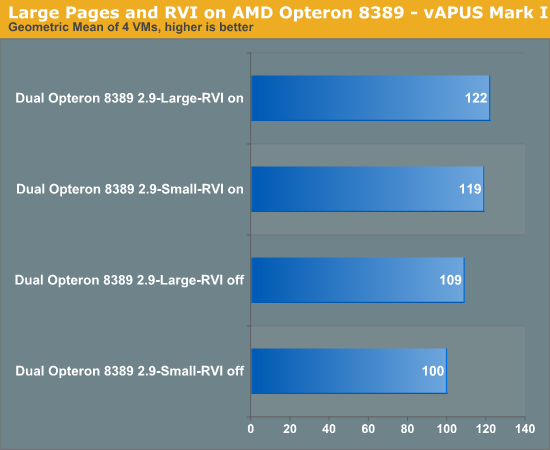
The effect of RVI is pretty significant: it improves our vApus Mark I score by almost 20%. The impact of large pages is rather small (3%), and this is probably a result of Shanghai's large TLB, consisting of a 96 entry (48 data, 48 instructions) L1 and a 512 entry L2 TLB. You could say there is less of a need for large pages in the case of the Shanghai Opteron.








66 Comments
View All Comments
JohanAnandtech - Friday, May 22, 2009 - link
We are definitely interesting in doing this, but of course we like to do this well. I'll update as soon as I can.pc007 - Thursday, May 21, 2009 - link
I agree, CPU & RAM usage are not really bottlenecks in my experience. Processes hamering slow disk and making everything else slower is the main concern.SeanG - Friday, May 22, 2009 - link
There are 300 million people in this country and you're surprised that some of them are ignorant/jerks/crazy? We're all supposed to be ashamed because not everyone from this country is mentally stable? It's insulting to people like me who care about this country to hear you talk about being ashamed over something that is a problem with humanity in general and not only in the US.lopri - Thursday, May 21, 2009 - link
It is said to see such a fascist persona in this comment section of such a fascinating article. I feel ashamed as one residing in the U.S.JohanAnandtech - Friday, May 22, 2009 - link
Don't be. Tshen must be the first US citizen that I have encountered that hates Belgians :-). All other US people I have met so far were very friendly. In fact, I am very much astonished how hospitable US people are. Sometimes we have only spoken over the phone or via e-mail with each other and the minute I arrive in the US, we are having a meal and chatting about IT. When you arrive in Silicon valley, one can only be amazed about the enormous energy and entrepreneurship this valley breathes.tshen83 - Friday, May 22, 2009 - link
You are a slave, Johan, whether you realize it or not. The people in Silicon Valley are "nice to you" because they are in the process of negotiating a purchased piece of publication from you.You don't know anything about the Silicon Valley nor are you qualified to talk about it. If anything is true, Silicon Valley is in the toilet right now with bankruptcies everywhere. The state is broke, with Arnold Schwarzenegger begging for Federal bailouts. The last two big "entrepreneurships" coming out of Silicon Valley: Facebook and Twitter are both advertising scams without a viable business model.
I don't hate Belgians. I do hate retards like you whether you come from Belgium or not.
[BANNED]
[FROM JARRED: We are proponents of free speech, but repeated name calling and insults with little to no factual information to back up claims will not be tolerated. There was worse, and I'm leaving this text so you can see how it started.]
tshen83 - Thursday, May 21, 2009 - link
As what I have expected, Johan, your sorry ass came up with a benchmark that invalidates VMmark.On page 9 "Nehalem vs Shanghai" http://it.anandtech.com/IT/showdoc.aspx?i=3567&...">http://it.anandtech.com/IT/showdoc.aspx?i=3567&...
Where is the Nehalem vs Shanghai benchmarks? All I see is a chart pumping Opteron 8389.
Let me dissect the situation for you [EDITED FOR VULGARITY].
The 100% performance per watt advantage witnessed by the Nehalem servers was the result of 3 factors: triple channel DDR3 IMC, HyperThreading, and Turbo Boost. The fact that Opterons can no longer compete because they lack the raw bandwidth and the "fake Hyper Threaded" cores that performs like a real core.
What would AMD do in this situation? Of course, invalidate an industrially accepted benchmark by substituting it with a "paid third party" benchmark that isn't available to the the public. I wonder what kind of "optimizations" were done?
You know what killed the GPU market? HardOCP.com. That's right, they invalidated the importance of 3DMark by doing game by game FPS analysis. The problem with this approach is that the third party game developers really don't have the energy or resources to make sure that each GPU architecture is properly optimized for. As long as the games run about 30fps on both Nvidia and ATI GPUs, they are happy. What results from this lackluster effort is that there is no Frames per Second differentiation on the GPU vendors, causing prices to free fall and the idiots choosing an architecturally inferior ATI GPU that gave a similar FPS performance.
Same methodology can be applied here. Since the Opterons lack raw memory bandwidth and core count visible to the OS, why not have a benchmark that isn't threaded well enough, and stress on high CPU utilization situations where memory bandwidth and core count matter less? That is what this new benchmark is doing, hiding Opteron architectural difficiencies.
The reason why VMmark stresses high number of VMs is to guage the hardware acceleration of VM switching. Having lesser number of VMs doing high CPU workload helps the worse performer(Opteron) by hiding and masquerading the performance difficiency. Nobody runs 100 VMs on one physical machine, but the VMmark does show you a superior hardware implementation. Nobody really prevents AMD from optimizing their CPUs for VMmark.
Let me be even more brutal with my assessment of your ethics, Johan. Why do you feel you are qualified to do what you do? The people who actually know about hardware are doing the CPU designs themselves in the United States, so the Americans would be the first to know about hardware. When the CPU samples are sent to Taiwan for motherboard design, the Asians would be the second batch of people dealing with hardware. By the time hardware news got to freaking Europe(Fudzilla, The Inq), the information usually was fudged up to the wazoos by Wall Street analysts. Consider yourself lucky that the SEC isn't probing you [EDITED FOR VULGARITY] because you reside in Belgium.
So Johan, my suggestion for you personally, is that you should consider the morality of your publications. In today's day and age, every word you ever say is recorded for eternity. Thirty years from now, do you want people to call you a [EDITED FOR VULGARITY] for pumping an inferior architecture by fudging benchmark results? Of course, I personally run the same risks. What I can guarantee you is that by June of next year, Johan, you [EDITED FOR VULGARITY] would be pumping Via instead.
JohanAnandtech - Friday, May 22, 2009 - link
As long as you are not able to discuss technical matters without personal attacks, I won't waste much time on you. Leave the personal attacks out of your comments, and I'll address every concern you have.But for all other readers, I'll show how shallow your attacks are (but they probably figured that one out a long time ago).
"Why not have a benchmark that isn't threaded well enough"
Yes, Tshen. In your world, Oracle and MS SQL server have few threads. In the realworld however...
"http://it.anandtech.com/IT/showdoc.aspx?i=3567&...">http://it.anandtech.com/IT/showdoc.aspx?i=3567&...
Where is the Nehalem vs Shanghai benchmarks? All I see is a chart pumping Opteron 8389. "
All other readers have seen a chart that tries to show how the benchmark reacts to cache size and memory bandwidth. All other readers understand that we only have one Nehalem Xeon, and that is a little hard to show empirically how for example different cache sizes influence the benchmark results.
Lastly, as long as I publish AMD vs Intel comparisons, some people will call me and Anandtech biased. This article shows that Nehalem is between 50 to 80% faster in typical server apps.
http://it.anandtech.com/IT/showdoc.aspx?i=3536&...">http://it.anandtech.com/IT/showdoc.aspx?i=3536&...
For some people that meant that we were biased towards Intel. In your case, we are biased towards AMD if Intel does not win by a huge percentage. For the rest of the world, it just means that we like to make our benches as realworld as possible and we report what we find.
whatthehey - Friday, May 22, 2009 - link
At least we can be grateful he's kind enough to include his IQ in his user name. You know what's interesting? tshen83 isn't exactly a common user name, and he happens to troll elsewhere:http://www.google.com/search?hl=en&q=tshen83">http://www.google.com/search?hl=en&q=tshen83
"Thirty years from now, do you want people to call you a fucking asshole...?" No need for you to wait 30 years, tshen; we'll be happy to call you a fucking asshole right now. As the saying goes: if the shoe fits....
JarredWalton - Thursday, May 21, 2009 - link
Frankly, you make me sad to be an American - as though just because someone is located in Belgium they are not qualified to do anything with hardware? Let's see, Belgium has higher average salaries than the US, so they surely have to be less qualified. And with you as a shining example we can certainly tell EVERYONE in the US is more qualified than in Europe.To whit, your assertion that HardOCP - or any other site - "killed the GPU market" is absurd in the extreme. The GPU market has seen declining prices because of competition between ATI and NVIDIA, and because the consumer isn't interested in spending $500 every 6-12 months on a new GPU. However, ATI and NVIDIA are hardly dying... though ATI as part of AMD is in a serious bind right now if things don't improve. Thankfully, AMD has helped the CPU market reach a similar point, but with Core i7 we're going back to the old way of things.
Your linking to page nine of this article as though that's somehow proof of bias is even better. Johan shows that Nehalem isn't properly optimized for in ESX 3.5, while Shanghai doesn't have that problem. That's a potential 22% boost for AMD in that test, which we outright admit! Of course, as Johan then points out, there are a LOT of companies that aren't moving to ESX 4.0 for a while yet, so ESX 3.5 scores are more of a look at the current industry.
Again, we know that VMmark does provide one measurement of virtualization performance. Is it a "catch-all"? No more so than the vApus Mark I tests. They both show different aspects of how a server/CPU can perform in a virtualized environment. We haven't even looked at stuff like Linux yet, and you can rest assured that the performance of various CPUs with that environment are all over the place (due to optimizations or lack of optimizations). Anyhow, I expect Nehalem will stretch its legs more in 2-tile and 3-tile testing, even with our supposedly biased test suite.
Since you're so wise, let me ask you something: what would happen if a large benchmark became highly used as a standard measurement of performance in an industry where companies spend billions of dollars? Do you think, just maybe, that places like Intel, Dell, HP, Sun, etc. might do a bunch of extra optimizations targeted solely at improving those scores? No, that could never happen, especially not in the great USA where we alone are qualified to know how hardware works. Certainly NVIDIA and ATI never played any optimization games with 3DMark.
In short, the responses to your comments should give you a good idea of how reasoned your postings are. Cool your jets and learn to show respect and thoughtful posting. I don't know why you're so worried about people showing Intel in the best light possible, but you post on (practically) every Intel or AMD article pumping the joys of Intel, and lambasting AMD.
The fact is, many reviews of Nehalem show inflated benefits for the architecture relative to the real world. VMmark with ESX 4.0 definitely falls into that category - or do you think a range of 14.22@10 tiles with ESX 3.5 Update 4 to 24.24@17 tiles with ESX 4.0 is perfectly normal? I'm not sure anyone actually runs a real workload that mimics VMmark to the point where simply an update to ESX 4.0 would boost performance and virtualization potential by 70%.
Does Intel make the currently better CPU? Of course they do. Does that mean AMD isn't worth a look? Hardly. There are numerous reasons an architecture might perform better/worse. VMmark - or any benchmark - will at best show one facet of performance, and thus what we really need are numerous tests showing how systems truly perform.