Apple's Cyclone Microarchitecture Detailed
by Anand Lal Shimpi on March 31, 2014 2:10 AM EST
The most challenging part of last year's iPhone 5s review was piecing together details about Apple's A7 without any internal Apple assistance. I had less than a week to turn the review around and limited access to tools (much less time to develop them on my own) to figure out what Apple had done to double CPU performance without scaling frequency. The end result was an (incorrect) assumption that Apple had simply evolved its first ARMv7 architecture (codename: Swift). Based on the limited information I had at the time I assumed Apple simply addressed some low hanging fruit (e.g. memory access latency) in building Cyclone, its first 64-bit ARMv8 core. By the time the iPad Air review rolled around, I had more knowledge of what was underneath the hood:
As far as I can tell, peak issue width of Cyclone is 6 instructions. That’s at least 2x the width of Swift and Krait, and at best more than 3x the width depending on instruction mix. Limitations on co-issuing FP and integer math have also been lifted as you can run up to four integer adds and two FP adds in parallel. You can also perform up to two loads or stores per clock.
With Swift, I had the luxury of Apple committing LLVM changes that not only gave me the code name but also confirmed the size of the machine (3-wide OoO core, 2 ALUs, 1 load/store unit). With Cyclone however, Apple held off on any public commits. Figuring out the codename and its architecture required a lot of digging.
Last week, the same reader who pointed me at the Swift details let me know that Apple revealed Cyclone microarchitectural details in LLVM commits made a few days ago (thanks again R!). Although I empirically verified many of Cyclone's features in advance of the iPad Air review last year, today we have some more concrete information on what Apple's first 64-bit ARMv8 architecture looks like.
Note that everything below is based on Apple's LLVM commits (and confirmed by my own testing where possible).
| Apple Custom CPU Core Comparison | ||||||
| Apple A6 | Apple A7 | |||||
| CPU Codename | Swift | Cyclone | ||||
| ARM ISA | ARMv7-A (32-bit) | ARMv8-A (32/64-bit) | ||||
| Issue Width | 3 micro-ops | 6 micro-ops | ||||
| Reorder Buffer Size | 45 micro-ops | 192 micro-ops | ||||
| Branch Mispredict Penalty | 14 cycles | 16 cycles (14 - 19) | ||||
| Integer ALUs | 2 | 4 | ||||
| Load/Store Units | 1 | 2 | ||||
| Load Latency | 3 cycles | 4 cycles | ||||
| Branch Units | 1 | 2 | ||||
| Indirect Branch Units | 0 | 1 | ||||
| FP/NEON ALUs | ? | 3 | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 64KB I$ + 64KB D$ | ||||
| L2 Cache | 1MB | 1MB | ||||
| L3 Cache | - | 4MB | ||||
As I mentioned in the iPad Air review, Cyclone is a wide machine. It can decode, issue, execute and retire up to 6 instructions/micro-ops per clock. I verified this during my iPad Air review by executing four integer adds and two FP adds in parallel. The same test on Swift actually yields fewer than 3 concurrent operations, likely because of an inability to issue to all integer and FP pipes in parallel. Similar limits exist with Krait.
I also noted an increase in overall machine size in my initial tinkering with Cyclone. Apple's LLVM commits indicate a massive 192 entry reorder buffer (coincidentally the same size as Haswell's ROB). Mispredict penalty goes up slightly compared to Swift, but Apple does present a range of values (14 - 19 cycles). This also happens to be the same range as Sandy Bridge and later Intel Core architectures (including Haswell). Given how much larger Cyclone is, a doubling of L1 cache sizes makes a lot of sense.
On the execution side Cyclone doubles the number of integer ALUs, load/store units and branch units. Cyclone also adds a unit for indirect branches and at least one more FP pipe. Cyclone can sustain three FP operations in parallel (including 3 FP/NEON adds). The third FP/NEON pipe is used for div and sqrt operations, the machine can only execute two FP/NEON muls in parallel.
I also found references to buffer sizes for each unit, which I'm assuming are the number of micro-ops that feed each unit. I don't believe Cyclone has a unified scheduler ahead of all of its execution units and instead has statically partitioned buffers in front of each port. I've put all of this information into the crude diagram below:
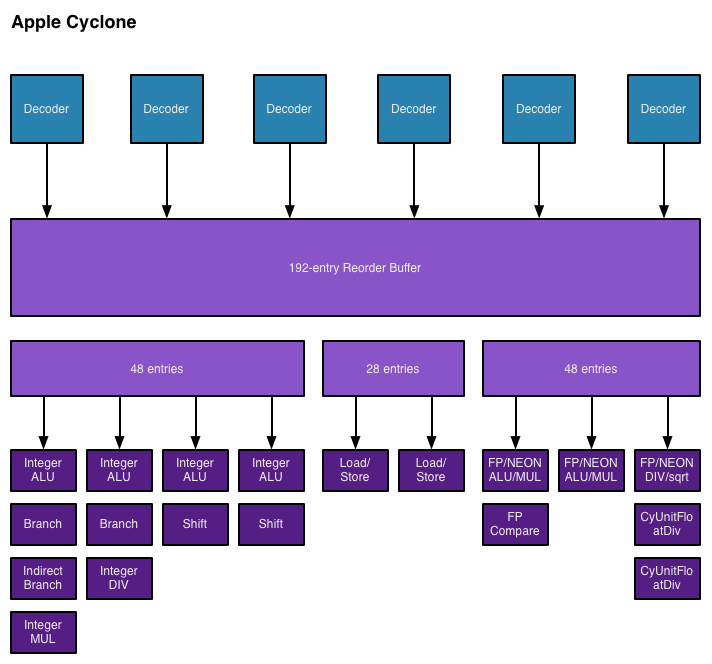
Unfortunately I don't have enough data on Swift to really produce a decent comparison image. With six decoders and nine ports to execution units, Cyclone is big. As I mentioned before, it's bigger than anything else that goes in a phone. Apple didn't build a Krait/Silvermont competitor, it built something much closer to Intel's big cores. At the launch of the iPhone 5s, Apple referred to the A7 as being "desktop class" - it turns out that wasn't an exaggeration.
Cyclone is a bold move by Apple, but not one that is without its challenges. I still find that there are almost no applications on iOS that really take advantage of the CPU power underneath the hood. More than anything Apple needs first party software that really demonstrates what's possible. The challenge is that at full tilt a pair of Cyclone cores can consume quite a bit of power. So for now, Cyclone's performance is really used to exploit race to sleep and get the device into a low power state as quickly as possible. The other problem I see is that although Cyclone is incredibly forward looking, it launched in devices with only 1GB of RAM. It's very likely that you'll run into memory limits before you hit CPU performance limits if you plan on keeping your device for a long time.

It wasn't until I wrote this piece that Apple's codenames started to make sense. Swift was quick, but Cyclone really does stir everything up. The earlier than expected introduction of a consumer 64-bit ARMv8 SoC caught pretty much everyone off guard (e.g. Qualcomm's shift to vanilla ARM cores for more of its product stack).
The real question is where does Apple go from here? By now we know to expect an "A8" branded Apple SoC in the iPhone 6 and iPad Air successors later this year. There's little benefit in going substantially wider than Cyclone, but there's still a ton of room to improve performance. One obvious example would be through frequency scaling. Cyclone is clocked very conservatively (1.3GHz in the 5s/iPad mini with Retina Display and 1.4GHz in the iPad Air), assuming Apple moves to a 20nm process later this year it should be possible to get some performance by increasing clock speed scaling without a power penalty. I suspect Apple has more tricks up its sleeve than that however. Swift and Cyclone were two tocks in a row by Intel's definition, a third in 3 years would be unusual but not impossible (Intel sort of committed to doing the same with Saltwell/Silvermont/Airmont in 2012 - 2014).
Looking at Cyclone makes one thing very clear: the rest of the players in the ultra mobile CPU space didn't aim high enough. I wonder what happens next round.








182 Comments
View All Comments
Alexey291 - Monday, March 31, 2014 - link
To be honest I'll believe in a working AND useful tegra chip when I see one.So far tegra (every single goddamn one) has been a flop. Tegras 1 and 2 don't bear mentioning, 3 was slow albeit cheap and thus somewhat popular (mostly due to N7 2012). Tegra 4 barely got ANY devices due to bad design decisions (read: too power hungry and not particularly fast compared to competition) and is thus a flop.
K1 looks nice on paper but then so did Tegra4 and they had to make their own tablet and their own handheld to get any sales out of that one. I sincerely doubt Nvidia's ability to produce anything useful with K1 as well.
Just my 2p.
grahaman27 - Monday, March 31, 2014 - link
That's just not true, and I would have expected better from the comment section of anandtech. The only tegra flop was tegra 3, that was a year they messed up on the chip. Tegra 2 was powerful for the time and set the standard, tegra 4 is still a beast to this day, and tegra k1 appears to be continuing that while maximizing graphics potential and optimizing efficiency.fteoath64 - Monday, March 31, 2014 - link
You got the Tegra history pretty close. Tegra 2 was king for a while in mobile, then Tegra 3 was eroded by Snapdragon and was good on tablets at one stage (remember Asus Transformer series tablets). Tegra4 being late was a "no show" in the market and when it did, Snapdragons 600/800 ruled the mobile market and still does. K1 being a kepler design was full-featured as opposed to ULP Tegra4 so a radical departure in terms of feature support. Maxwell evolve that further and granularized the cores much more. It supports all the features of desktop parts but not as fast in most ops. So roll-out to product form is vital for it to get into mainstream. Since QC has a full lock on major OEMs, it is a tough battle for NV. Their venture into the vehicle market is stonger than others, so that might be new market territory NV wants. It becomes easier to be an established leader and maintain it.toyotabedzrock - Tuesday, April 1, 2014 - link
The Tesla model S uses an NV part don't they?Alexey291 - Monday, March 31, 2014 - link
Sorry mate but it is true :) And as for "expected better". Well I could say the same to you.Tegra 2 was good clock for clock. Shame it never clocked anywhere near the competition. So it was sold on mid-low devices. You know the ones known for "android lag". But yeah given that that's where android sales ACTUALLY are it sold a lot.
I'm glad we agree on tegra 3. Worst soc of the generation. Yet sold like hot cakes for the same reason as above. There are a lot of cheap droid devices on shit socs. Nexus 7 2012 is probably the best example. Although all those asus fake-laptops are a good example as well. They ran like shit but showed pretty effects if you played those 3.5 games that supported tegra effects :)
Tegra 4 is a beast that hasn't sold, benchmarked below all of its direct competition (its nice clock for clock again but who cares about that?) and gives the worst battery life of the lot. Oh and its hot. I wonder why they were forced to make their own-ish tablet? To shift stock most likely.
Going by the track record K1 is going to be a flop again. And going by the sales trend it will be present on like 2 devices. Both of which will be NV's own homebrew. But we shall see. Hopefully not - Qualcomm is getting boring.
In before OMG I EXPECTED BETTUR! :)
djboxbaba - Monday, March 31, 2014 - link
I'm glad someone understands the truth about Tegragrahaman27 - Monday, March 31, 2014 - link
Alexey291,You must be not follow SoC news closely, or at least not for the past few years. I stand by my opinion.
Also, Look up the Sheild's benchmarks, it is competitive with the snapdragon 801 chip in many regards (gfxbench, javascript perf, geekbench).
itpromike - Tuesday, April 1, 2014 - link
The on topic question though is how does shield and snapdragon 801 compare to Cyclone? After all it's the competitor to beat it sounds like.Kidster3001 - Monday, April 7, 2014 - link
Competitive on GFBench: Yep, it hardly has any pixels to push. The Shield uses a ridiculously low resolution screen so it scores better. It wouldn't be so great on a 1080p screen.Competitive on Javascript: Javascript is just a measure of the javascript engine. Doesn't mean anything when comparing CPU's unless they are both running the same javascript engine. Still, the CPU cores in T4 are competitive performance-wise.
Competitive on Geekbench: Yeah, the cores are competitive.... IF you strap a big fat heatsink on them. Performance per watt? It is not good. If in a phone the battery life would be extremely poor.
Wolfpup - Monday, March 31, 2014 - link
Tegra 3 was awesome when it launched. It's still decent, but it's 3 years on. It runs Windows RT really well.