Original Link: https://www.anandtech.com/show/3506
How AMD's Istanbul might close the gap with Nehalem EP
by Johan De Gelas on February 25, 2009 12:00 AM EST- Posted in
- IT Computing general
The Istanbul cores are the same as those that can be found in the AMD's latest Shanghai CPU. But the "uncore" part of Istanbul is more interesting. By now, you have probably heard about AMD's "HT-assist" technology, a probe or snoop filter. Every time a new cacheline is brought into the L3-cache of for example CPU 1 on the current Shanghai Platform, a broadcast message is sent to all L3-caches of all CPUs, and CPU 1 has to wait until those CPUs answer.
In the case of Istanbul, the CPU will simply check it's snoop filter in it's own L3-cache, and if none of the other CPUs have that certain cacheline, it can go ahead. This lowers the latency of bringing in a new cacheline and raises the effective bandwidth.
To better understand this, we combined our own stream benchmarking with the one that AMD presented. All AMD systems are using DDR-2 800.
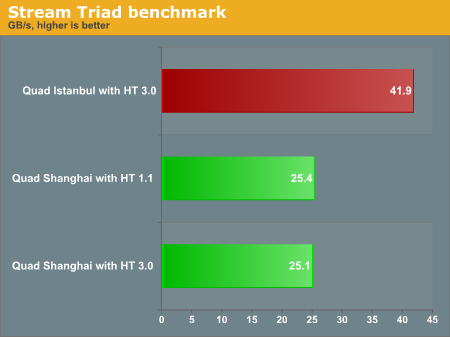
As each Stream thread works on its own data, there is no reason to send out coherency synchronization requests. These requests slow the process of getting new cachelines in the L3 and hence lower effective memory bandwidth. What is interesting is that this will not only benefit the applications that use the HT interconnects a lot for coherency traffic, but also applications like stream which do not need the HT interconnects. Also notice that HT 3.0 does not improve memory bandwidth, as Stream will try to keep its thread data local. Our testing used SUSE SLES 10 SP2 and AMD used Windows 2008. Both OSs are well optimized and NUMA aware.
This means that especially HPC applications, with many threads all working on their own data, will benefit from the higher effective bandwidth. Besides HT assist, AMD has now confirmed to us that the memory controller has been tuned quite a bit. This higher amount of bandwidth will allow the quad Istanbul to stay out of the reach of the dual Nehalem EP Xeons in many HPC applications.
HT assist might also improve the SAP and OLTP scores quite a bit, but for a different reason. SAP and OLTP applications perform a lot of cache coherency syncronization requests, so the snoop filter will substantially lower the average latency of such requests as in some cases:
- the CPU will only wait on one other CPU (instead of waiting for all responses to come back)
- the CPU won't have to wait at all, as the other CPUs don't have this line.
Secondly, this will also lower memory latency, which is a bonus for almost every multi-threaded application.
Lower memory latency, higher bandwidth, lower "cache coherency" latency and more interconnect bandwidth: the improved "uncore" of Istanbul will be vital to close the gap with Nehalem. Much will depend on how quickly Intel introduces its own hexacore 32 nm Xeons, but that probably won't happen before 2010. Istanbul is shaping up to be a really good alternative for Intel's quadcore Nehalem. We might see a good fight after all...
Don't forget to check it.anandtech.com (IT portal) often, as many of our blogposts (for example the VMworld 2009 coverage) are not published on the frontpage of Anandtech.com.






