Linux Desktop CPU Roundup: Cutting Edge Penguin Performance
by Kristopher Kubicki on September 19, 2004 8:00 PM EST- Posted in
- Linux
DDR2 versus DDR1
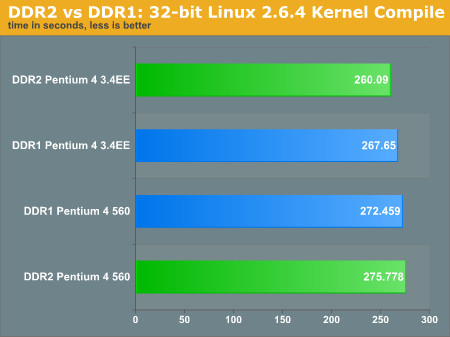
There are very few real-world benchmarks that completely demonstrate total memory bandwidth saturation. For real world applications, latency becomes critical - or at least logic dictates. Below, you can see what happens to our Intel processors when we run them on DDR2 and DDR1. We used the same low latency Mushkin PC-3200 (2-2-2) that we used for the AMD testbed as our DDR1 kit. Low latencies are something that DDR2 modules lack right now; and even though our Corsair XMS2 memory operates at ~675MHz, the timings are less than spectacular 4-4-4.Let's take a look at a kernel compile - a typical memory and CPU hog.
Below are the two different configurations of Intel processors running DDR1 and DDR2 during our Mental Ray 3.3.1 benchmark.
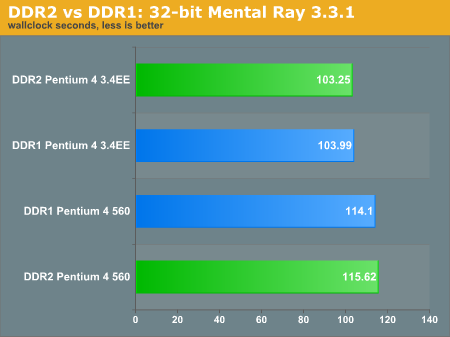
We are not really given a clear indication of which configuration runs better. The P4EE with DDR2 smidges past any other configuration, we expect more differentiation between the two. Let us look at some more content creation tests.
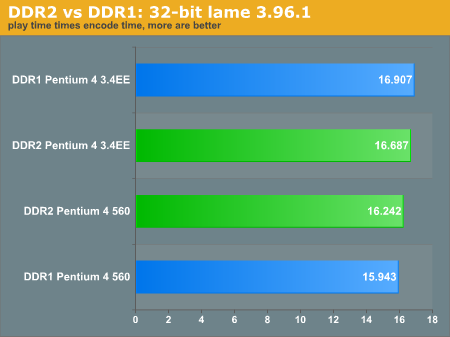
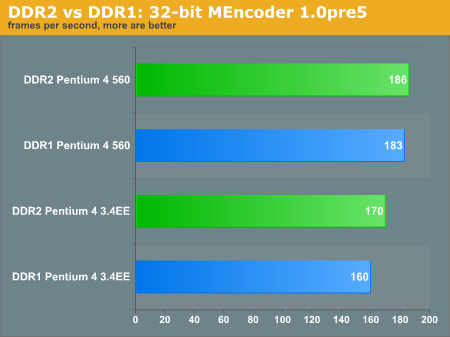

Notice that the MySQL test-select benchmark improves with DDR1 over DDR2. When we are making thousands of little queries to the database, we are relying more heavily on low latencies rather than the larger headroom of DDR2. However, consider our warning to take the sql-bench tests with a grain of salt. They do not entirely reflect SQL performance or workstation performance. The inconsistancy of which memory configuration from one benchmark to another definitely complicates issues. Price generally finishes the discussion for us.








33 Comments
View All Comments
- Saturday, October 24, 2009 - link
sell:nike shoes$32,ed hardy(items),jean$30,handbag$35,polo shirt$13,shox$34Hugh R - Thursday, September 23, 2004 - link
Thanks for this article. It has been needed for about a year. Every previous benchmark of AMD 64 seemed to be 32-bit mode which is rather missing the point.Firefox 1.0PR on LINUX did not show the 64-bit results until I went to edit:preferences:web features:enable java advanced... and turned on lots of crap (I don't know which item made the difference).
The information was fascinating but the presentation was very awkward.
When you see a surprising benchmark result, it is a good idea to analyze why you were surprised. For example, I would guess that the poor showing for 64-bit code on John the Ripper might be due to hand-coded x86 assembly code. Note: just a guess.
The fact that Wine is only 32-bit seems pretty uninteresting/unsurprising: Win32 binaries are also only 32-bit.
Few things in the LINUX world are binary-only, so almost anything for which CPU performance matters can and should be run in 64-bit mode on a 64-bit processor.
bobbozzo - Tuesday, September 21, 2004 - link
You should be running all the compilation test with -j2 or higher, as otherwise the CPU is waiting for the disk more often.uyu - Tuesday, September 21, 2004 - link
Consider re-evaluating the test with the icc compiler:http://www.intel.com/software/products/compilers/c...
I do not think it will only favor the result of intel processors..
Zebo - Tuesday, September 21, 2004 - link
Why separate the graphs? Afriad of people easily visualizing major A64 ownage? Gawd that's hard to compare that way... I had to get out pen and paper.Shalmanese - Tuesday, September 21, 2004 - link
"throw an alternative opterating system"I like the attempt at subliminal advertising :D.
TrogdorJW - Monday, September 20, 2004 - link
On the LAME encoding benchmark, isn't the actual value really "Play time divided by encoding time"? Or perhaps "Relative encoding rate"? Anyway, the text explains the graph better (in 1 second the 64-bit FX-53 encoded 25 seconds of audio). Otherwise, good stuff.injinj - Monday, September 20, 2004 - link
Crafty does have a bit of hand tuned asm for both x86 and x86_64. Most of the operations are done with boards packed into bit representations. For example, like this:while (moves) {
to=FirstOne(moves);
*move++=temp|(to<<6)|(PcOnSq(to)<<15);
Clear(to,moves);
}
The FirstOne() function utilizes the bitscan ops of x86 (bsr = bit scan reverse), but notice the cmpl at the top:
cmpl $1, 8(%esp)
sbbl %eax, %eax
movl 8(%esp,%eax,4), %edx
bsr %edx, %ecx
jz l4
andl $32, %eax
subl $31, %ecx
subl %ecx, %eax
ret
l4: movl $64, %eax
The cmpl splits a 64 bit word into a 32 bit hi and lo words, so crafty will naturally exploit 64 bit instructions.
This same function on x86_64 can be done much fewer instructions:
asm (
" bsrq %0, %1" "\n\t"
" jnz 1f" "\n\t"
" movq $-1, %1" "\n\t"
"1: movq $63, %0" "\n\t"
" subq %1, %0" "\n\t"
: "=r&" (dummy), "=r&" (dummy2)
: "0" ((long) (word))
: "cc");
These are critical functions in crafty and if you see benchmarks comparing 64 bit crafty to 32 bit crafty, this is primarily why 64 bits is faster.
mczak - Monday, September 20, 2004 - link
what's up with the encryption benchmarks? "OpenSSL's crypt libraries are probably heavily optimized for 32-bit operation; we see the difference in the two architectures very clearly."But the results show that 64bit mode is more than two times as fast as 32bit mode in one case (RSA), and 50% faster in the other case (AES)?
(and btw I haven't looked at johntheripper, but it might contain hand-optimized assembly for x86, but only generic c code for other architectures such as x86_64.)
PrinceGaz - Monday, September 20, 2004 - link
The mouseover images work fine for me (Firefox 0.9.3)