AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
64-bit MySQL (Linux 64-bit)
MySQL has released version 5.1.22, which supposedly can scale up to eight CPU cores. That would be a huge improvement considering that all versions earlier than 5.0.37 could only make good use of two CPU cores. In our experience, this new binary scales well up to four cores, but eight cores are easily 20% slower than four core systems. Thus, we tested with a maximum of four cores.
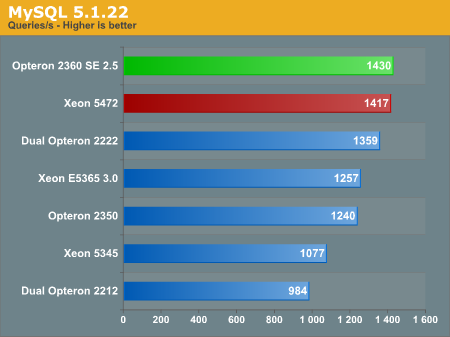
Please note that these results cannot be compared with our earlier MySQL results. MySQL v5.1.22 is a completely different binary than v5.0.2x we tested previously. Although it still doesn't scale beyond four cores, it is up to 70% (!!) faster than v5.0.26 that came standard with our SLES 10 SP1. For smaller servers with four cores, MySQL is once again an ultra fast database.
Moreover, the third generation of Opterons absolutely loves this new MySQL version. At 2.5GHz, it is just as fast (the margin of error is up to 4%) as the mighty Xeon 5472 at 3GHz. As we failed to profile MySQL in depth (CodeAnalyst for Linux still has some quirks), we cannot pinpoint the exact reason why the Opteron 23xx is so good at this. The MySQL database is mostly limited by synchronizing the locks, so we suspect that the slightly faster cache coherency syncing on the Opteron 23xx might be one of the reasons AMD's latest performs so well.
WinRAR 3.62 (Windows 32-bit)
WinRAR 3.62 is a completely different kind of workload.
| WinRAR 3.62 Profiling | |
| Profile | Total |
| Average IPC (on AMD 2350) | 0.36 |
| Instruction mix | |
| Floating Point | 0% |
| SSE | 0% |
| Branches | 9% |
| L1 datacache ratio | 1.13 |
| L1 I cache ratio | 0.35 |
| Performance indicators (on Opteron 2350) | |
| Branch misprediction | 7% |
| L1 datacache miss | 4% |
| L1 Instruction cache miss | 0% |
| L2 cache miss | 3% |
Notice that contrary to the other workloads we have profiled so far, WinRAR does not run perfectly in the L1 or L2 cache. Second, notice the huge amount of loads that happen: more than one per retired instruction.

The massive bandwidth that Barcelona can offer multi-threaded software pays off here. You can also see that the Seaburg chipset improves the score of the 3GHz quad-core Xeon by 7%.








43 Comments
View All Comments
befair - Friday, November 28, 2008 - link
ok .. getting tired of this! Intel loving Anandtech employs very unfair & unreasonable tactics to show AMD processors in bad light every single time. And most readers have no clue about the jargon Anandtech uses every time.1 - HPL needs to be compiled with appropriate flags to optimize code for the processor. Anandtech always uses the code that is optimized for Intel processors to measure performance on AMD processors. As much as AMD and Intel are binary compatible, when measuring performance even a college grad who studies HPC knows the code has to be recompiled with the appropriate flags
2 - Clever words: sometimes even 4 GFLOPS is described as significant performance difference
3- "The Math Kernel Libraries are so well optimized that the effect of memory speed is minimized." - So ... MKL use is justified because Intel processors need optimized libraries for good performance. However, they dont want to use ACML for AMD processors. Instead they want to use MKL optimized for Intel on AMD processors. Whats more ... Intel codes optimize only for Intel processors and disable everything for every other processors. They have corrected it now but who knows!! read here http://techreport.com/discussions.x/8547">http://techreport.com/discussions.x/8547
I am not saying anything bad about either processor but an independent site that claims to be fair and objective in bringing facts to the readers is anything but fair and just!!! what a load!
DonPMitchell - Friday, December 7, 2007 - link
I think a lot of us are intrigued by AMD's memory architecture, its ability to support NUMA, etc. A lot of benchmarch test how fast a small application runs with a high cash-hit rate, and that's not necessarily interesting to everyone.The MySQL test is the right direction, but I'd rather see numbers for a more sophisticated application that utilizes multiple cores -- Oracle or MS SQL Server, for example. These are products designed to run on big iron like Unisys multi-proc servers, so what happens when they are running on these more economical Harpertown or Barcelona.
kalyanakrishna - Thursday, November 29, 2007 - link
http://scalability.org/?p=453">http://scalability.org/?p=453kalyanakrishna - Thursday, November 29, 2007 - link
a much better review than the original one. But I still see some cleverly put sentences, wish it were otherwise.Viditor - Thursday, November 29, 2007 - link
Nice review Johan!On the steppimgs note you made, it's not the B2 stepping that is supposed to perform better, it's the BA stepping...
The BA stepping was the improved form for B1s, and the B3 stepping is the improved form of the B2. BA and B2 came out at the same time in Sept (though BA was the one launched, B1 was what was reviewed), B2 for Phenom and performance clockspeeds, BA for standard and low power chips.
Do you happen to have a BA chip to test (those are the production chips)?
BitByBit - Wednesday, November 28, 2007 - link
Despite K10's rather extensive architectural improvements, it looks likes its core performance isn't too different to K8. In fact, the gains we've seen so far could easily be attributable to the improved memory controller and increased cache bandwidth. It seems that introducing load reordering, a dedicated stack, improved branch prediction, 32B instruction fetch, and improved prefetching has had little impact, certainly far less than expected. The question is, why?JohanAnandtech - Wednesday, November 28, 2007 - link
Well, we are still seeing 5-10% better integer performance on applications that are runing in the L2, so it is more than just a K8 with a better IMC. But you are right, I expected more too.However, the MySQL benchmark deserves more attention. In this case the Barcelona core is considerably faster than the previous generation (+ 25%). This might be a case where 32 bit fetch and load reordering are helping big time. But unfortunately our Codeanalyst failed to give all the numbers we needed
BaronMatrix - Wednesday, November 28, 2007 - link
At any rate, it was the most in-depth review I've seen, especially with the code analysis. I too, thought it would be higher, but remember that Barcelona is NOT HT3 and doesn't have the advantage of "gangning\unganging." There was an interesting article recently that showed perf CAN be improved by unganging (maybe it was ganging, can't find it) the HT3 links.I really hate that OEMs decided to stand up to the big, bad AMD and DEMAND that Barcelona NOT have HT3 with ALL OF ITS BENEFITS.
I mean people complain that Barcelona uses more power, but HT3 would cut that somewhat. At least in idle mode, and even in cases where IMC is used more than the CPU or vice versa.
I also may as well use this to CONDEMN all of these "analysts" who insist on crapping on the underdog that keeps prices reasonable and technology advancing.
INSERT SEVERAL EXPLETIVES. REPEATEDLY. FOR A FEW DAYS. A WEEK. FOR A YEAR.
INSERT MORE EXPLETIVES.
donaldrumsfeld - Wednesday, November 28, 2007 - link
Conjecture regarding why AMD went quad core on the same die... and this has nothing to do with performance. I think one place where Intel is way ahead of AMD is package technology. Remember they were doing a type of Multichip module with the P6. Having 2 dice instead of a single die allows them to have an overall lower defect rate, higher yield, and higher GHz. This is vs. AMD's lower GHz but (it was hoped) greater data efficiency using an L3 die and lower latency of on-die communications amongst cores vs. Intel's solution of die to die communication.Can anyone confirm/deny this?
thanks
tshen83 - Tuesday, November 27, 2007 - link
Seriously, can you buy the 2360SE? Newegg doesn't even stock the 1.7Ghz 2344HEs.The same situation exist on the Phenom line of CPUs. I don't see the value of reviewing Phenom 9700, 9900s when AMD cannot deliver them. I have trouble locating Phenom 9500s.