Real-world virtualization benchmarking: the best server CPUs compared
by Johan De Gelas on May 21, 2009 3:00 AM EST- Posted in
- IT Computing
Analysis: "Nehalem" vs. "Shanghai"
The Xeon X5570 outperforms the best Opterons by 20% and 17% of the gain comes from Hyper-Threading. That's decent but not earth shattering. Let us first set expectations. What should we have expected from the Xeon X5570? We can get a first idea by looking at the "native" (non-virtualized) scores of the individual workloads. Our last Server CPU roundup showed us that the Xeon X5570 2.93GHz is (compared to a Xeon E5450 3GHz):
- 94% faster in Oracle Calling Circle
- 107% faster in a OLAP SQL Server benchmark
- 36% faster on the MCS eFMS web portal test
If we would simply take a geometric mean of these benchmarks and forget we are running on top of a hypervisor, we would expect a 65% advantage for the Xeon X5570. Our virtualization benchmark shows a 31% advantage for the Xeon X5570 over the Xeon 5450. What happened?
It seems like all the advantages of the new platforms such as fast CPU interconnects, NUMA, integrated memory controllers, and L3 caches for fast syncing have evaporated. In a way, this is the case. You have probably noticed the second flaw (besides ignoring the hypervisor) in the reasoning above. That second flaw consists in the fact that the "native scores" in our server CPU roundup are obtained on eight (16 logical) physical cores. Assuming that four virtual CPUs will show the same picture is indeed inaccurate. The effect of fast CPU interconnects, NUMA, and massive bandwidth increases will be much less in a virtualized environment where you limit each application to four CPUs. In this situation, if the ESX scheduler is smart (and that is the case) it will not have to sync between L3 caches and CPU sockets. In our native benchmarks, the application has to scale to eight CPUs and has to keep the caches coherent over two sockets. This is the first reason for the less than expected performance gain: the Xeon 5570 cannot leverage some of its advantages such as much quicker "syncing".
The fact that we are running on a hypervisor should give the Xeon X5570 a boost. The Nehalem architecture switches about 40% quicker back and forth to the hypervisor than the Xeon 54xx. It cannot leverage its best weapon though: Extended Page Tables are not yet supported in ESX 3.5 Update 4. They are supported in vSphere's ESX 4.0, which immediately explains why OEMs prefer to run VMmark on ESX 4.0. Most of our sources tell us that EPT gives a boost of about 25%. To understand this fully, you should look at our Hardware virtualization: the nuts and bolts article. The table below tells what mode the VMM (Virtual Machine Monitor), a part of the hypervisor, runs. To refresh your memory:
- SVM: Secure Virtual Machine, hardware virtualization for the AMD Opteron
- VT-x: Same for the Intel Xeon
- RVI: also called nested paging or hardware assisted paging (AMD)
- EPT: Extended Page Tables or hardware assisted paging (Intel)
- Binary Translation: well tweaked software virtualization that runs on every CPU, developed by VMware
| Hypervisor VMM Mode | ||
| ESX 3.5 Update 4 | 64-bit OLTP & OLAP VMs | 32-bit Web portal VM |
| Quad-core Opterons | SVM + RVI | SVM + RVI |
| Xeon 55xx | VT-x | Binary Translation |
| Xeon 53xx, 54xx | VT-x | Binary Translation |
| Dual-core Opterons | Binary Translation | Binary Translation |
| Dual-core Xeon 50xx | VT-x | Binary Translation |
Thanks to being first with hardware-assisted paging, AMD gets a serious advantage in ESX 3.5: it can always leverage all of its virtualization technologies. Intel can only use VT-x with the 64-bit Guest OS. The early VT-x implementations were pretty slow, and VMware abandoned VT-x for 32-bit guest OS as binary translation was faster in a lot of cases. The prime reason why VMware didn't ditch VT-x altogether was the fact that Intel does not support segments -- a must for binary translation -- in x64 (EM64T) mode. This makes VT-x or hardware virtualization the only option for 64-bit guests. Still, the mediocre performance of VT-x on older Xeons punishes the Xeon X5570 in 32-bit OSes, which is faster with VT-x than with binary translation as we will see further.
So how much performance does the AMD Opteron extract from the improved VMM modes? We checked by either forcing or forbidding the use of "Hardware Page Table Virtualization", also called Hardware Virtualized MMU, EPT, NPT, RVI, or HAP.
 |
Let's first look at the AMD Opteron 8389 2.9GHz. When you disable RVI, memory page management is handled the same as all the other "privileged instructions" with hardware virtualization: it causes exceptions that make the hypervisor intervene. Each time you get a world switch towards the hypervisor. Disabling RVI makes the impact of world switches more important. When you enable RVI, the VMM exposes all page tables (Virtual, Guest Physical, and "machine" physical) to the CPU. It is no longer necessary to generate (costly) exceptions and switches to the hypervisor code.
However, filling the TLB is very costly with RVI. When a certain logical page address or virtual address misses the TLB, the CPU performs a lookup in the guest OS page tables. Instead of the right physical address, you get a "Guest Physical address", which is in fact a virtual address. The CPU has to search the Nested Pages ("Guest Physical" to "Real Physical") for the real physical address, and it does this for each table lookup.
To cut a long story short, it is very important to keep the percentage of TLB hits as high as possible. One way to do this is to decrease the number of memory pages with "large pages". Large pages mean that your memory is divided into 2MB pages (x86-64, x86-32 PAE) instead of 4KB. This means that Shanghai's L1 TLB can cover 96MB data (48 entries times 2MB) instead of 192 KB! Therefore, if there are a lot of memory management operations, it might be a good idea to enable large pages. Both the application and the OS must support this to give good results.
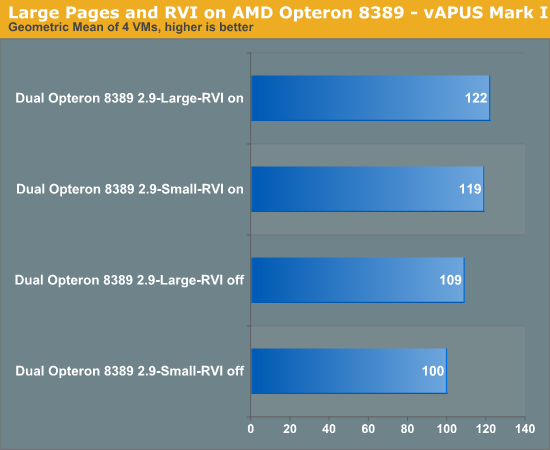
The effect of RVI is pretty significant: it improves our vApus Mark I score by almost 20%. The impact of large pages is rather small (3%), and this is probably a result of Shanghai's large TLB, consisting of a 96 entry (48 data, 48 instructions) L1 and a 512 entry L2 TLB. You could say there is less of a need for large pages in the case of the Shanghai Opteron.








66 Comments
View All Comments
binaryguru - Monday, June 1, 2009 - link
It seems to me, x86-based virutalization software is getting more and more complicated. Not only is x86 virtualization getting more complicated, it is getting more and more difficult to get reliable performance from it.Let me explain my point.
The industry is clearly trying to do more with less hardware these days. Getting raw VM performance on commodity hardware is getting to a point where there is no predictable way to plan for an efficient VM environment.
Current VM technology is trying to simulate the flexibility and performance of mainframes. To me, this is clearly an impossible goal to achieve with the current or future x86 platform model.
All of the problems the industry is experiencing with VM consolidation does not exist on the mainframe. Running 4 'large' VMs for 'raw' performance. How about running 40 'large' VMs for 'raw' performance. Clearly, we all know that is impossible to achieve with current VM setups.
Now I'm not saying that virtuallization is a bad idea, it clearly is the ONLY solution for the future of computing. However, I think that the industry is going about it the wrong way. Server farms are becoming increasingly more difficult to manage, never mind the challenge of getting 100s of blade servers to play nice with each other while providing good processing throughput.
This problem has been solved about 20 years ago; and yet, here we are, struggling again with the "how can I get MORE from my technology investment" scenario.
In conclusion, I think we need to go back to utilizing huge monolithic computing designs; not computing clusters.
mikidutzaa2 - Friday, May 29, 2009 - link
Hello,It would be useful (if possible) to have latency numbers/response times on the tests as well because rarely we are interested in throughput on our servers. What we usually care more is how long it takes the server to respond to user actions.
What is your opinion?
JohanAnandtech - Friday, May 29, 2009 - link
I agree. I admit it is easier for us or any benchmark person to use throughput as immediately comparable (X is 10% faster than Y) and you have only one datapoint. That is why almostResponsetime however can only be understood by drawing curves relative to the current throughtput / User concurrency. So yes, we are taking this excellent suggestion into consideration. The trade off might that articles get harder to read :-).
mikidutzaa2 - Friday, May 29, 2009 - link
Looking forward to your new articles then, glad to hear :).The articles don't necessarily have to be harder to read, you could put the detailed graphs on a separate page and maybe show only one response time for a "decent"/medium user concurrency.
Also, I would find interesting (if you have time) to have the same benchmarks with 2vcpu machines, I think this is a more common setup for virtualization. Very few people I think virtualize their most critical/highly used platforms - at least that's how we do it. We need virtualization for lightly used platforms (i.e. not very many users) but we are still very much interested in response time because the users perceive latency, not throughput.
So the important question is: if you have a virtual server (as opposed to a physical one) will the users notice? If so, by how much is it slower?
Thank you.
RobAm - Tuesday, May 26, 2009 - link
It's good to see some unbiased analysis with respect to virtualization. It's also especially interesting that your workloads (which look much more like real world apps my company runs as opposed to SPECjbb, vmark, vconsolidate) shows a much more competitive landscape than vmware and Intel portray. Also, doesn't vmware prohibit benchmarking without their permission. Did they give you permission? Has VMware called offering to re-educate you? :-)Brovane - Tuesday, May 26, 2009 - link
I was hoping for a some benchmarks on the Xeon x7xxx CPU for the Quad Socket Intel boxes. We are currently have Dell R900's and we where looking at adding to our ESX cluster. We where debating between the R900 with Hex cores our Xeon x55xx series CPU's in the R710. I see the x55xx series where bench marked but nothing on the Xeon MP series unless I am missing that part of the article.JohanAnandtech - Tuesday, May 26, 2009 - link
Expect a 24-core CPU comparison soon :-).Brovane - Tuesday, May 26, 2009 - link
You also might want to a 12-core comparison also. We have found that with a 4-socket box that you usually run out of memory before you run out CPU power. With the R900 having 32-Dimm Sockets, the R900's we purchased last year have 64GB of RAM and just use 2x2.93Ghz CPU's we max memory before CPU easily in our environment. Since Vmware licensing and Data Center licensing is done per Socket we only populate 2 of the sockets with CPU's and this seems to do great for us. You basically double your licensing costs if you go with all 4 sockets occupied. Just a thought as to how sometimes virtualization is done in the real world. There is such a price premium for 8GB memory Dimm's it isn't worth it to put 256GB in one box with all 4 sockets occupied. The 4GB Dimm's did reach price parity this year so we were looking at going for 128GB of memory on our new R900's however Intel also released Hex-core so we still don't see much reason to occupy all 4 sockets.yasbane - Tuesday, May 26, 2009 - link
I know positive feedback is always appreciated for the hard work put in but it seems very rare that we see any non-microsoft benchmarks for server stuff these days on Anandtech. Is there any particular reason for this...? I don't mean to carp but I recall the days when non-microsoft technologies actually got a mention on Anandtech. Sadly, we don't seem to see that anymore :(Cheers
JohanAnandtech - Tuesday, May 26, 2009 - link
Yasbane, my first server testing articles (DB2, MySQL) were all pure Linux benches. However, we have moved on to a new kind of realworld benchmarks and it takes a while to master the new benchmarks we have introduced. Running Calling Circle and Dell DVD store posed more problems on Linux than on Windows: we have lower performance, a few weird error messages and so on. In our lab, about 50% of the servers are running linux (and odd machines is running OS-X and another Solaris :-) and we definitely would love to see some serious linux benchmarking again. But it will take time.Xen benchmarks are happening as I write this BTW.