Istanbul's Improvements
The cores inside “Istanbul” are not different from those found in Shanghai. Istanbul introduces only a few improvements: HT assist, slightly higher HT speeds, APML and x8 ECC.

X8 ECC: Each DRAM chip on a DIMM provides either 4 bits or 8 bits of a 64-bit data word. Chips that provide 4 bits are called x4 (by 4), and chips that provide 8 bits are called x8 (by 8). It takes eight x8 chips or sixteen x4 chips to make a 64-bit word, so at least eight chips are located on one or both sides of a DIMM. Istanbul’s memory controller now supports error correction for both x4 and x8 DIMMs.
APML Remote Power Management Interface: APML provides an interface that allows you to monitor and control platform power consumption via P-state limits. You need to have a CPU and BMC (management processor) that support APML on the server and you need to have some type of software (OS or management software) that supports APML and allows you to monitor power and make changes to power management parameters. Both hardware and software are in development, so this won’t be available on the servers that will be launched this month. APML is interesting as it would allow you to cap power without going into the BIOS. AMD’s PowerCap Manager allows you to limit power to a certain amount by making sure the CPU’s clock never goes beyond a certain limit, effectively underclocking the CPU. This is very useful in a datacenter that is cooling or power limited. Of course, BIOS options are not that handy in a datacenter with hundreds of servers. That is where APML could make the difference.
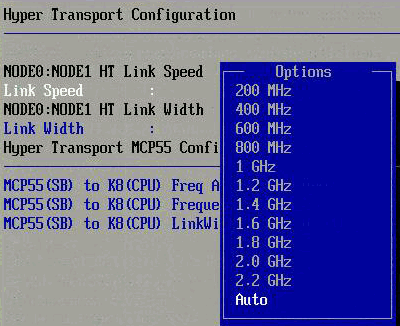
Higher HT Speeds: The later versions of the “Shanghai” Opteron versions support HyperTransport 3.0 or HT3. HT3 allows much higher clockspeeds than the HyperTransport links that all the older Opterons have been using so far (1GHz). The clockspeed was boosted to 2.2 GHz DDR, good for 8.8 GB/s in each direction. Istanbul pushes the clock of the HyperTransport up to 2.4GHz DDR, good for 9.6 GB/s in each direction. Or as fast as the QPI links which can be found on the slower “Nehalem” Xeons. Since the new Fiorano platform is not ready, we still have to test with an older NVIDIA MCP55 platform. But that does not matter; the CPU interconnect speed is handled by the CPUs, not the board or chipset. You can clearly see in the BIOS screenshot below:
The last improvement is HT Assist. We will discuss this feature in more detail.
HT Assist: Only for the Quad-Socket
HT assist is a probe or snoop filter AMD implemented. First, let us look at a quad Shanghai system. CPU 3 needs a cacheline which CPU 1 has access to. The most recent data is however in CPU’s 2 L2-cache.
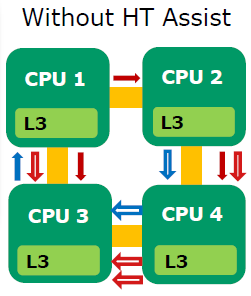
Start at CPU 3 and follow the sequence of operations:
1. CPU 3 requests information from CPU 1 (blue “data request” arrow in diagram)
2. CPU 1 broadcasts to see if another CPU has more recent data (three red “probe request” arrows in diagram)
3. CPU 3 sits idle while these probes are resolved (four red & white “probe response” arrows in diagram)
4. The requested data is sent from CPU 2 to CPU 3 (two blue and white “data response” arrows in diagram)
There are two serious problems with this broadcasting approach. Firstly, it wastes a lot of bandwidth as 10 transactions are needed to perform a relatively simple action. Secondly, those 10 transactions are adding a lot of latency to the instruction on CPU 3 that needs the piece of data (which was requested by CPU 3 to CPU 1).
The solution to is a directory-based system, that AMD calls HT Assist. HT assist reserves 1MB portion of each CPU’s L3 cache to act as a directory. This directory tracks where that CPU’s cache lines are used elsewhere in the system. In other words the L3-caches are only 5 MB large, but a lot of probe or snoop traffic is eliminated. To understand this look at the picture below:
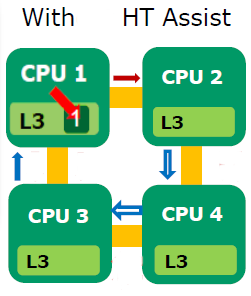
Let us see what happens. Start again with CPU 3:
1. CPU 3 requests information from CPU 1 (blue line)
2. CPU 1 checks its L3 directory cache to locate the requested data (Fat red line)
3. The read from CPU 1’s L3 directory cache indicates that CPU 2 has the most recent copy and directly probes CPU 2 (Dark red line)
4. The requested data is sent from CPU 2 to CPU 3 (blue and white lines)
Instead of 10 transactions, we have only 4 this time. A considerable reduction in latency and wasted bandwidth is the result. Probe “broadcasting” can be eliminated in 8 of 11 typical CPU-to-CPU transactions. Stream measurements show that 4-Way memory bandwidth improves 60%: 41.5GB/s with HT Assist versus 25.5GB/s without HT Assist.
But it must be clear that HT assist is only useful in a quad-socket system and of the utmost importance in octal CPU systems. In a dual system, broadcast is the same as a unicast as there is only one other CPU. HT assist also lowers the hitrate of L2-caches (5 MB instead of 6) so it should be disabled on 2P systems. If you look in the BIOS...
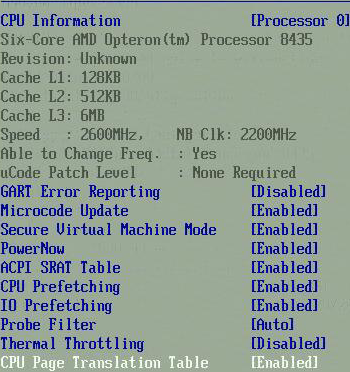
...you get 3 options next to probe filter: “auto”, “disabled” and “MP”. In automatic mode the probe filter or HT Assist will be turned off for 2P systems. You can force “HT assist” by setting “MP”, indicating there are more than 2 processors.








40 Comments
View All Comments
iocedmyself - Wednesday, June 17, 2009 - link
Well something that was failed to be mentioned was that the 2P opteron machine costs about $6700, where as the nehalem 2p machine is very near to $16,000.as for power consumption a straight up comparison would be HP380 Xeon and HP 385 Opteron. At idle, both are 140W. With 100% CPU / Ram, 385 is around 300W, 380 (Xeon) is about 450W.
another thing not discussed here - 4P Istanbul is 70-80% faster than 2P Nehalem, and there is no 4P Nehalem. 8P Istanbul is over 3 times as fast as 2P Nehalem. so until next gen Nehalem, there is no competition in the high end which probably has something to do with istanbul orders being through the roof.
I also have to wonder if these benchmarks were conducted using one of Intel's little helpful optimized compilers.
yasbane - Wednesday, June 10, 2009 - link
would be nice to see some unix or linux benchmarks...riskyburden - Thursday, June 4, 2009 - link
I might be naive here but surely the majority of these applications are favouring clock speed and no more than two cores, should there not be a bench for those companies that run multiple apps such as SQL and AD or IPFX etc all from one server and make a comparison there. I don't suggest it to be good network practice but that would interest me more.mino - Friday, June 5, 2009 - link
For this part of SMB market pretty much any dual core CPU will do.Their bottleneck is almost allways on the storage side, sometimes with insufficient memory.
And most also run default install where basic SW tweaks would make 100's percents in performance.
befair - Wednesday, June 3, 2009 - link
Johan never proves me wrong. Even an article meant to talk about AMD Opteron starts with a good deal of "Intel is the king!" stuff, as usual.alpha754293 - Wednesday, June 3, 2009 - link
What happened to them?I would have to loved to have seen what the new 6-core AMDs would be able to do in this arena since it is (presumably) a much more competitive offering than the fastest Xeons all around.
lopri - Tuesday, June 2, 2009 - link
A Question: Is the 'snoop-filter' a hardware-based? I read that it can be enabled/disabled via BIOS, and since the cores are same as Shanghai cores.. But my question is, whether it's hardware-based or software-based (BIOS), shouldn't this work for inter-core communication as well if AMD decides to implement it?JohanAnandtech - Tuesday, June 2, 2009 - link
I have to check, but I am pretty sure it is both. The "uncore" part has changed somewhat on Istanbul."shouldn't this work for inter-core communication as well if AMD decides to implement it"
Since the L3-cache keeps copies of shared L2-cachelines, I don't think that will help. There is already a very fast way of communicating with little overhead.
tygrus - Monday, June 1, 2009 - link
I would like to know the performance difference when using a cell size of 3 not 6 on the 6-core units or of 8 not 4 on Xeon 4Core8Thread ?Will have to wait for latter for more raw performance numbers (eg. memory local/system, SPEC CPU, task switching, OS/IO task servicing).
How long before they update the boards for DDR3 based memory and better IO onboard ?
It's a pity the ESX 4.0 update hasn't helped AMD .. are the improvements only available for Intel or was it to correct a previous Intel only problem ? What can AMD/partners do to improve performance ?
JohanAnandtech - Tuesday, June 2, 2009 - link
"I would like to know the performance difference when using a cell size of 3 not 6 on the 6-core units?"A cell size of 3 will not do any good if your VMs are MP. Eventhough ESX features "relaxed co-scheduling", there might quite a few cases where the Scheduler is not able to use all "slots" as some of vCPUs of the VMs might be behind. From the momemt you use more than 2 vCPUs, you will get situations where only one VM with 2 CPUs is scheduled on a cell of 3 CPUs. 8-cell: I have to try it.
"How long before they update the boards for DDR3 based memory and better IO onboard ? "
The AMD's Fiorano platform that will be available in a few weeks should have better I/O (PCIe gen 2) but will still be DDR-2 based.
DDR-3 CPUs are scheduled for 2010.
"It's a pity the ESX 4.0 update hasn't helped AMD .. are the improvements only available for Intel or was it to correct a previous Intel only problem ? "
VMware's docs tell us they that CPU locking goes more quickly and that the scheduler is "cache aware", but most of the biggest improvements are EPT and better support for Hyperthreading.