ARM Challenging Intel in the Server Market: An Overview
by Johan De Gelas on December 16, 2014 10:00 AM ESTCavium Thunder-X
A few months ago, we talked briefly with the people of Cavium. Cavium is specialized in designing MIPS SoCs that enable intelligent networking, communications, storage, video, and security applications. The picture below sums it all up: present and future.
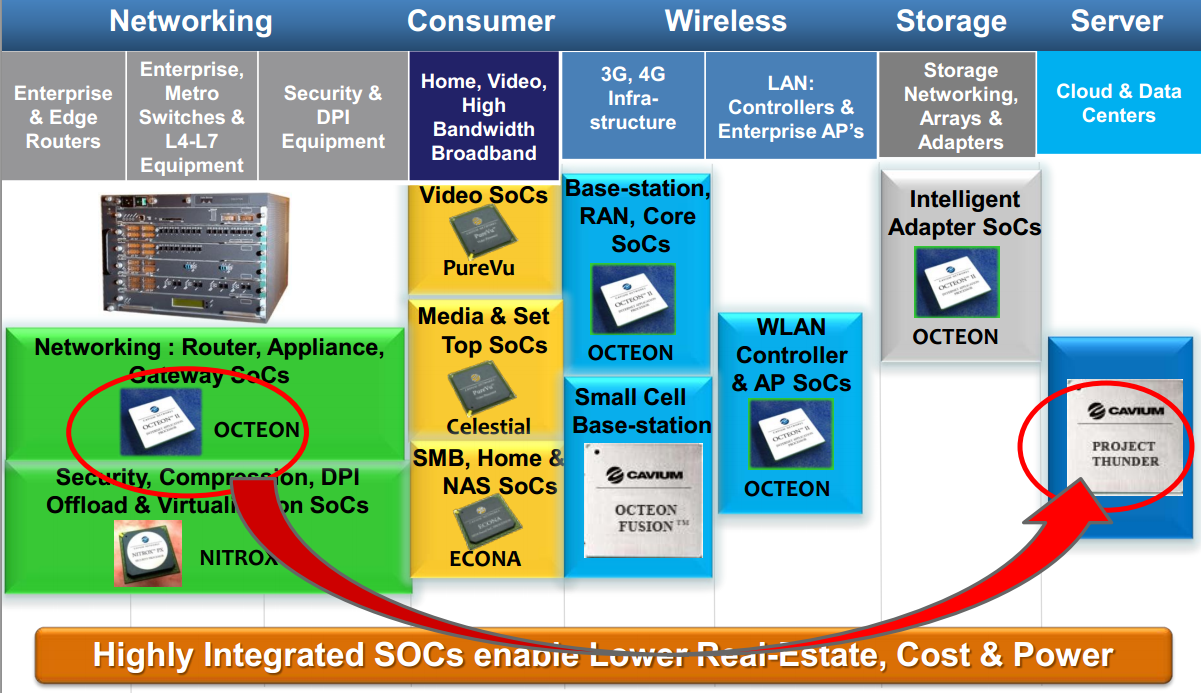
Cavium's "Thunder Project" started from Cavium's existing Octeon III network SoC, the CN78xx. Cavium's bread and butter has been integrating high speed network capabilities in SoCs, so you will be able to choose between SoCs that have 100 Gbit Ethernet and 10GBit Ethernet. PCI-Express roots and multiple SATA ports are all integrated. There is no doubt that Cavium can design a highly integrated feature-rich SoC, but what about the processing core?

The MIPS cores inside the Octeon are much simpler – dual-issue in-order – but also much smaller and need very little power compared to a typical server core. Four (28nm) MIPS cores can fit in the space of one (32nm) Sandy Bridge core.
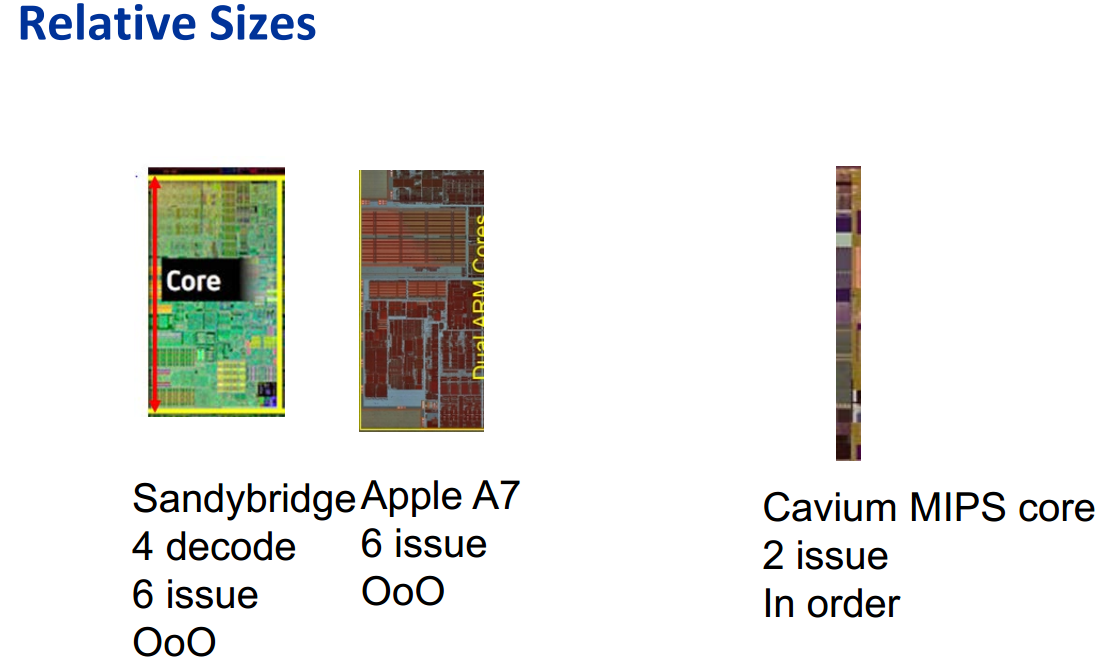
Replace the MIPS decoders with ARMv8 decoders and you are almost there. However, while the Cavium Thunder-X is definitely not made to run SAP, server workloads are bit more demanding than network processing, so Cavium needed to beef up the Octeon cores. The new Thunder-X cores are still dual-issue, but they're now out-of-order instead of in-order, and the pipeline length has been increased from eight to nine stages to allow for higher clocks. Each core has a 78KB L1 Instruction cache and a 32KB data cache.
The 37-way 78KB L1 I cache is certainly odd, but it might be more than just "network processor heritage". Our own testing and a few academic studies have shown that scale-out workloads such as memcached have a higher than normal (meaning the typical SPECIntRate2006 characterization) I-cache miss rate. The reason is that these applications run a lot of kernel code, and more specifically the code of the network stack. As a result, the software footprint is much higher than expected.
Another reason why we believe Cavium has done it's homework is the fact that more die area is spent on cores (up to 48) than on large caches; an L3 cache is nowhere to be found. The Thunder-X has only one centralized relatively low latency 16MB L2 cache running at full core speed. A lot of academic studies have confirmed that a large L3 cache is a waste of transistors for scale-out workloads. Besides the most used instructions that reside in the I-cache, there is a huge amount of less frequently used kernel code that does not fit in an L3 cache. In other words, an L3 cache just adds more latency to requests that missed the L1 cache and that will end up in the DRAM anyway. That is also the reason why Cavium made sure that a beefy memory controller is available: the Thunder-X comes with four DDR3/4 72-bit memory controllers and it currently supports the fastest DRAM available for servers: DDR4-2133.
On the flip side, having 48 cores with a relatively small 32KB D-cache that access one centralized 16MB L2 cache also means that the Thunder-X is less suited for some "traditional" server workloads such as SQL databases. So a Thunder-X core is simpler and probably quite a bit weaker than an ARM Cortex-A57 in some ways, let alone an X-Gene core. The fact that the Thunder-X spends a lot less transistors on cache than on cores clearly indicates that it is targeting other workloads. Single-threaded performance is likely to be lower than that of the AMD Seattle and X-Gene, but it could be close enough: the Thunder-X will run at 2.5GHz, courtesy of Global Foundries' 28nm process technology. Cavium is claiming that even the top SKU will keep the TDP below 100W.
There is more. The Thunder-X uses Cavium's proprietary Coherent Processor Interconnect (CCPI) and can thus work in a dual socket NUMA configuration. As a result, a Thunder-X based server can have up to 96 cores and is capable of supporting 1TB of memory, 512GB per socket. Multiple 10/40GBE, PCIe Root Complex, and SATA controllers are integrated in the SoC. Depending on SKU, TCP/IP Sec offload and SSL accelerators are also integrated.

The recent launch of Cavium's Thunder-X SKUs make it clear that Cavium is trying to compete with the venerable Xeon E5 in some niche but large markets:
- ThunderX_CP: For cloud compute workloads such as public and private clouds, web caching, web serving, search, and social media data analytics.
- ThunderX_ST: For cloud storage, big data, and distributed databases.
- TunderX_NT: For telecom/NFV server and embedded networking applications.
- ThunderX_SC: For secure computing applications
Considering Cavium's background and expertise, it is pretty obvious that ThunderX_NT and SC should be very capable challengers to the Xeon E5 (and Xeon-D), but only a thorough review will tell how well the ThunderX_CP will do. One of the strongest points of Calxeda was the highly integrated fabric that lowered the total power consumption and network latency of such a server cluster. Just like AMD/Seamicro, Cavium is well positioned to make sure that the Thunder-X based server clusters also have this high level of network/compute integration.








78 Comments
View All Comments
hojnikb - Tuesday, December 16, 2014 - link
Wow, i have never motherboard that simple :)CajunArson - Tuesday, December 16, 2014 - link
OK you devote another huge block of text to the typical x86 complexity myth* followed by: Oh, but the ARM chips are superior because they have special-purpose processors that overcome their complete lack of performance (both raw & performance per watt).Uhm... WTF?? I need to have a proprietary, poorly documented add-on processor to make my software work well now? How is that a "standard"? How is requiring a proprietary add-on processor that's not part of any standard and requires boatloads of software cruft working in a "reduced instruction set architecture" exactly?
I might as well take the AVX instruction set for modern x86... which is leagues ahead of anything that ARM has available, and say that x86 is now a "RISC" architecture because the AVX part of x86 is just as clean or cleaner than anything ARM has. I'll just conveniently forget about the rest of x86 just like the ARM guys conveniently forget about all the non-standard "application accelerators" that are required to actually make their chips compete with last-year's Atoms.
* Maybe in a micro-controller setting where you are using a PIC or Arduino the x86 decoding is a real issue, but in a server? Please. Considering the only hard numbers you have show a 2013-model Atom beating a 2015-model ARM server processor, you'll have to try harder.
hlmcompany - Tuesday, December 16, 2014 - link
The article describes ARM chips as becoming more competitive, but still lagging behind...not that they're superior.Kevin G - Tuesday, December 16, 2014 - link
The coprocessor idea is something stems from mainframe philosophy. Historically things like IO requests and encryption were always handled by coprocessors in this market.The reason coprocessors faded away outside of the mainframe market is that it was generally cheaper to do a software implementation. Now with power consumption being more critical than ever, coprocessors are seen as a means to lower overall platform power while increasing performance.
Philosophically, there is nothing that would prevent the x86 line from doing so and for the exact same reasons. In fact with PCIe based storage and NVMe on the horizon in servers, I can see Intel incorporating a coprocessor to do parity calculations for RAID 5/6 in there SoCs.
kepstin - Tuesday, December 16, 2014 - link
Intel has already added some instructions in avx and avx2 that vastly improve the performance of software raid5 and 6; the Haswell chip in my laptop has the Linux software raid implementation claiming 24GiB/s raid5 with avx, and 23GiB/s raid6 with avx2 (per core).MrSpadge - Tuesday, December 16, 2014 - link
Of course additional power draw for more complex instruction deconding mattes in servers: today they are driven by power-efficiency! The transistors may not matter as much, but in a multi-core environment they add up. Using the quoted statement from AMD of "only 10% more transistors" means one could place 11 RISC cores in the same area for the same cost as 10 otherwise identical x86 cores. Johan said it perfectly with "the ISA is not a game changer, but it matters".And you completely misunderstood him regarding the accelerators. Intel is producing "CPUs for everyone" and hence only providing few accelerators or special instructions. In the ARM ecosystem it's obvious that vendors are searching niches and are willing to provide custom solutions for it - hence the chance is far higher that they provide some accelerator which might be game-changing for some applications.
This doesn't mean the architecture has to rely entirely on them, neither does it mean they have to be undocumented. The accelerators do not even have to be faster than software solutions, as long as they're easy enough to work with and provide significant power savings. Intel is doing just that with special-purpose hardware in their own GPUs.
And don't act as if much would have changed in the Atom space ever since 22 nm Silvermont cores appeared. It doesn't matter if it's from 2013 or 2015 - it's all just the same core.
OreoCookie - Tuesday, December 16, 2014 - link
What's with all the unnecessary piss and vinegar?All CPU vendors rely increasingly on specialized silicon, newer Intel CPUs feature special crypto instructions (AES-NI) and Quick Sync, for instance. Adding special purpose hardware to augment the system (in the past usually done for performance reasons) is quite old, just think of hardware RAID cards and video »accelerators« (which are not called GPUs). The reason that Intel doesn't add more and more of these is that they build general purpose CPUs which are not optimized for a specific workload (the article gives a few examples). In other environments (servers, mobile) the workload is much more clearly defined, and you can indeed take advantage of accelerators.
The biggest advantage of ARM cpus is flexibility -- the ARM ecosystem is built on the idea to tailor silicon to your demands. This is also a substantial reason why Intel's efforts in the mobile market have been lackluster. Recently, Synology announced a new professional NAS (the DS2015xs) which was ARM-based rather than Intel-based. Despite its slower CPU cores, the throughput of this thing is massive -- in part, because it sports two (!) 10 GBit ethernet ports out of the box. Vendors are looking for niches where ARM-based servers could gain a foothold, so they are trying a lot of things and see what sticks.
goop666666 - Saturday, December 20, 2014 - link
LOL! Most of the comments here like this one seem to be written by people who think computers should all be like gaming machines or something.Here'a tip: no-one cares about "complexity," "standardization," "RISC," or anything else you mention. All they care about in the target market for ARM server chips is price, performance and power, and I mean ALL THREE.
On this Intel cannot compete. They sell wildly overpriced legacy hardware propped up by massive R&D expenditures and they're wedded to that model. The rest of the industry is wedded to the new and cheap model. Just like how the industry moved to mobile devices and Intel stood still, this change will also wash over Intel while they sit still in denial.
There's a reason why Intel stock has gone no-where for years.
nlasky - Monday, December 22, 2014 - link
Jan 8, 2010, Intel stock price $20.83. Dec 19, 2010, Intel stock price $36.37. If by gone no-where in for years you mean increased by 70% I guess you would be correct. Intel can't compete because they are wedded to their model? They have a profit margin of 20% and an operating margin of 27%. They could easily cut prices to compete with any ARM offerings. Servers have been around forever, unlike the mobile computing platform. Intel has an even larger stranglehold on this industry than ARM has in the mobile space. Here's a tip - stop spewing a bunch of uniformed nonsense just to make an argument.nlasky - Monday, December 22, 2014 - link
*Dec 19, 2014