Seagate BarraCuda Pro 12TB HDD Review
by Ganesh T S on November 15, 2017 8:00 AM EST- Posted in
- Storage
- Seagate
- HDDs
- Helium HDD
Performance - Internal Storage Mode
The performance of an internal storage device is dependent on the performance characteristics of the device as well as the file system being used. In order to isolate the effects of the latter, we first benchmarked the raw drives using HD Tune Pro 5.70. It was then formatted in NTFS and subject to our standard direct-attached benchmark suite.
Raw Drive Performance
HD Tune Pro allows us to run a variety of tests to determine transfer rates and IOPS for various artificial workloads. In addition, it also allows us to visualize how the performance varies as the tracking head moves from the outer parts of the platter towards the center (i.e, transfer rates as a function of the block address).
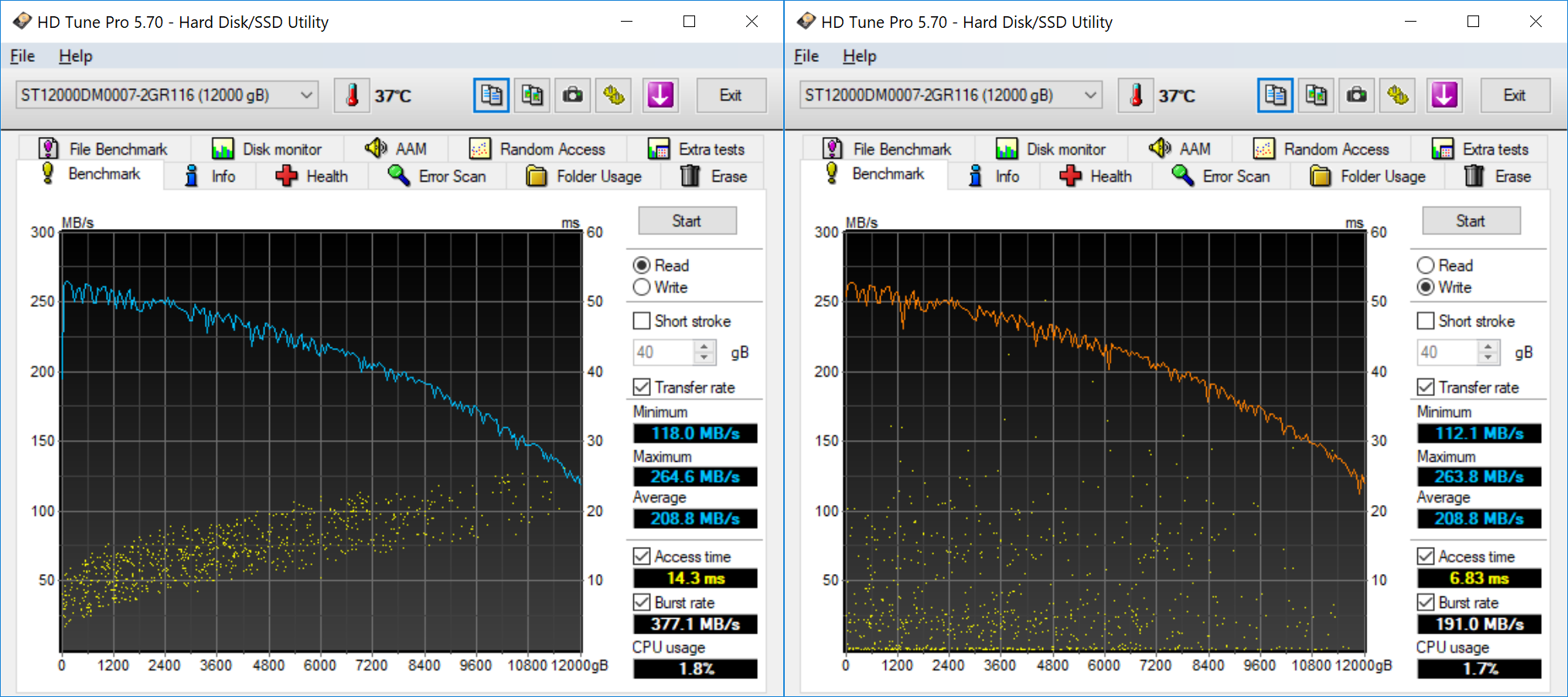
Empty drives are bound to perform very well, but, depending on the location of the data in the drive, we find that access rates can go as low as 112 MBps for sequential workloads. Write access times are a bit unpredictable due to the multi-segmented cache.
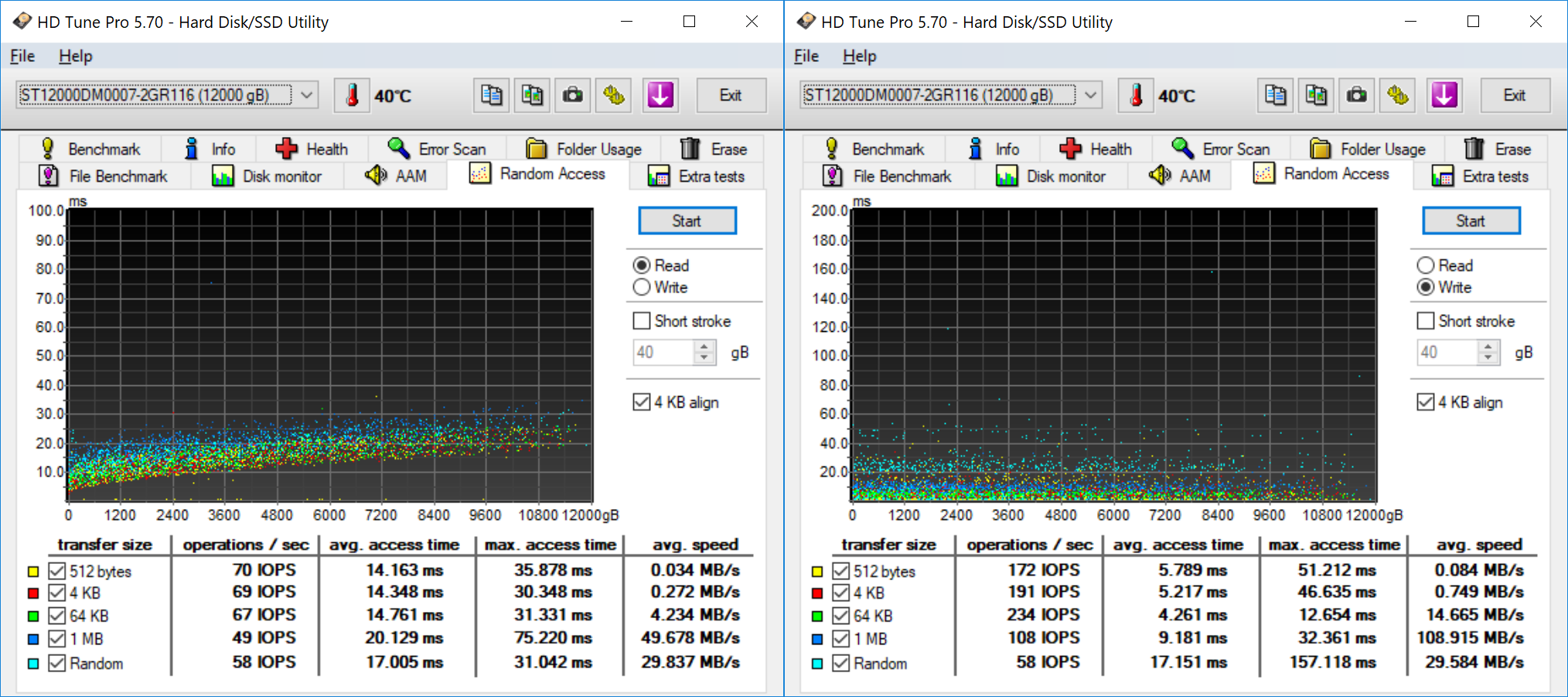
Random accesses are never the strong points of hard drives, and we see that the BarraCuda Pro delivers around 70 IOPS for 4K random reads and writes.
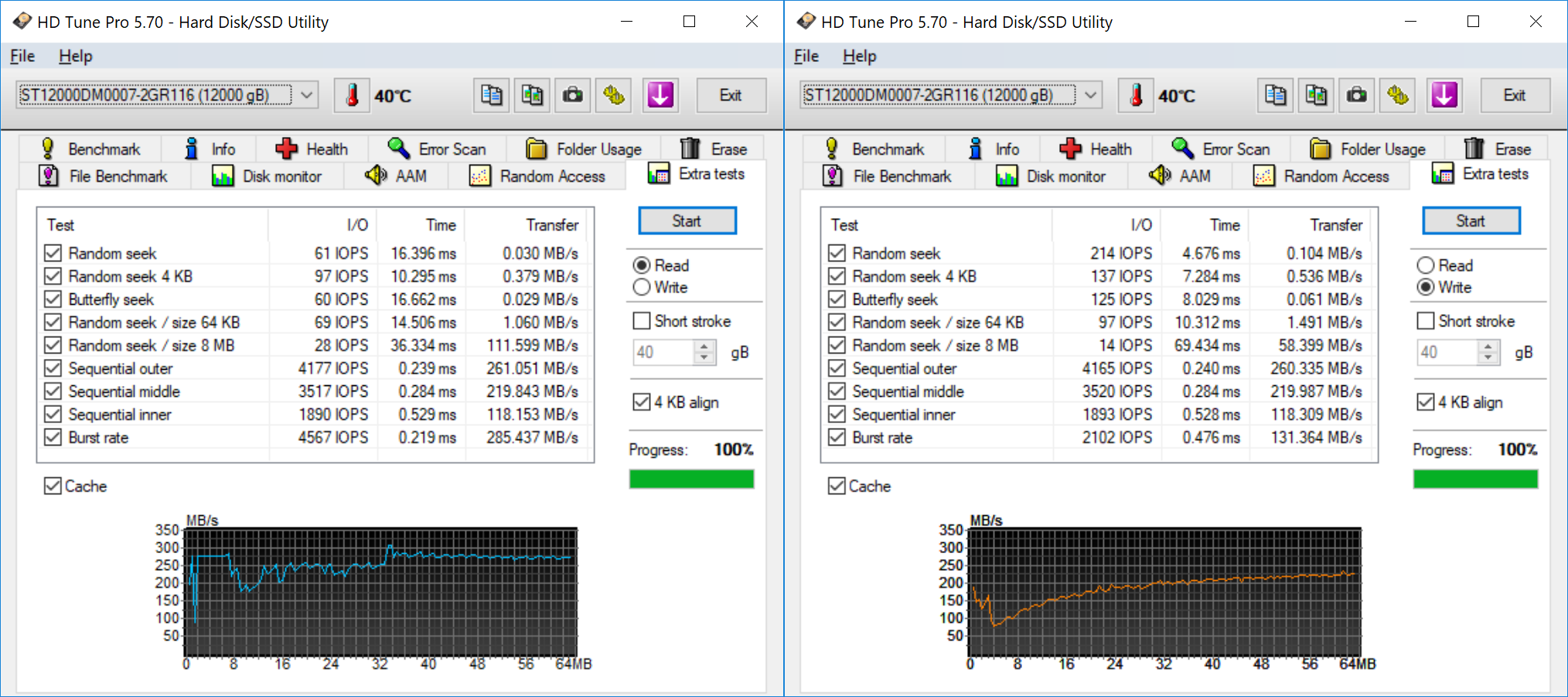
The extra tests help in putting some numbers to sequential accesses targeting different areas of the drive. It also provides some interesting numbers relevant to various random access workloads.
DAS Benchmarks
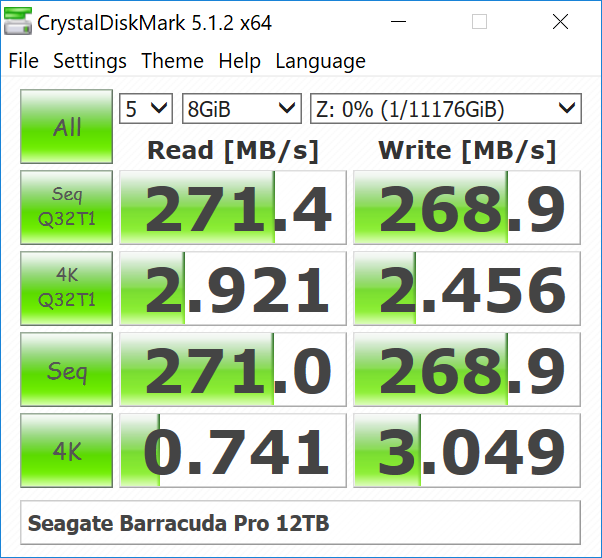
Consumers opting for drives such as the 12TB Seagate BarraCuda Pro typically need high-capacity local storage for holding and editing / processing large-sized multimedia files. Prior to taking a look at the real-life benchmarks, we first check what CrystalDiskMark has to report for the drive.
In order to tackle the real-life use-case of transferring large amounts of data back and forth from the drive, we created three test folders with the following characteristics:
- Photos: 15.6 GB collection of 4320 photos (RAW as well as JPEGs) in 61 sub-folders
- Videos: 16.1 GB collection of 244 videos (MP4 as well as MOVs) in 6 sub-folders
- BR: 10.7 GB Blu-ray folder structure of the IDT Benchmark Blu-ray (the same that we use in our robocopy tests for NAS systems)
| Seagate BarraCuda Pro 12TB robocopy Benchmarks (MBps) | ||
| Write Bandwidth | Read Bandwidth | |
| Photos | 219.23 | 205.51 |
| Videos | 231.42 | 219.46 |
| Blu-ray Folder | 234.05 | 230.02 |
These numbers are consistently around 15 - 20 MBps more than what we obtained for the 10TB drives last year.
While processing our DAS suite, we also recorded the instantaneous transfer rates and temperature of the drive. Compared to typical disk drives, the write transfers show higher instantaneous speeds due to a combination of the firmware and the 256 MB cache inside the drive. However, sustained write rates are comparable to other high-capacity drives when the cache is exhausted. The temperature of the unit at the end of the transfers (more than 250GB of traffic) rose by less than 5C, pointing to the power-efficiency of the platform.

For the use-case involving editing of multimedia files directly off the disk, we take advantage of PCMark 8's storage benchmark. The storage workload is a good example of a user workload, involving games as well as multimedia editing applications. The command line version allows us to cherry-pick storage traces to run on a target drive. We chose the following traces.
- Adobe Photoshop (Light)
- Adobe Photoshop (Heavy)
- Adobe After Effects
- Adobe Illustrator
Usually, PCMark 8 reports time to complete the trace, but the detailed log report has the read and write bandwidth figures which we present in our performance graphs. Note that the bandwidth number reported in the results don't involve idle time compression. Results might appear low, but that is part of the workload characteristic.
| Seagate BarraCuda Pro 12TB PCMark8 Storage Benchmarks (MBps) | ||
| Write Bandwidth | Read Bandwidth | |
| Adobe Photoshop (Light) | 250.22 | 9.06 |
| Adobe Photoshop (Heavy) | 246.88 | 11.48 |
| Adobe After Effects | 89.74 | 8.85 |
| Adobe Illustrator | 196.38 | 8.42 |
Compared to the results from the 10TB drive last year, we find that the read workloads are slightly worse off, but, the write workloads are much faster.








62 Comments
View All Comments
rtho782 - Wednesday, November 15, 2017 - link
I'd rather loose a 12TB Plex Library than a 100kB bitcoin wallet with 10 bitcoins in.The size of the data isn't really relevant.
BurntMyBacon - Wednesday, November 15, 2017 - link
@Glock24: "Who wants to lose 12TB of data? Yeah, not me."You will only loose as much data as you have stored on the drive. If you only have 3TB data, then it doesn't matter whether it's a 12TB drive or a 6TB drive (assuming the same failure rate). If you do have 12TB of data, then you'll need several smaller drives to hold that data (2x6TB, 3x4TB, etc.). That presents a trade-off for data protection. While a single catastrophic (total) drive failure won't take all your data with it, you've massively increased the probability of a catastrophic drive failure taking place. Then there's the fact that not all your data is of equal value. If Murphy has anything to say about it, it will be your most valuable data that gets lost. So all going with smaller really does is reduce the severity of a data loss (due to total drive failure) at the expense of increasing the certainty of data loss (and that data possibly being your most valuable data).
So, as kingpotnoodle said, have a backup plan in place. Redundancy via RAID1 (or other RAID not 0) is good practice for data protection. Also, if you are so inclined, you can use a file system that has built in redundancy features (I.E. ZFS) and store two or more copies of files on different parts of the drive. This would reduce the amount of data able to be stored on the drive, but significantly increase data resilience from failures that aren't total drive failures. It also makes data recovery more likely in the case of total drive failure.
In short, a 12TB drive can be both less likely to loose data and have no more data to lose than a 4TB drive if you set it up that way (ZFS or similar with triple redundancy at the file system level). Of course, this comes at the expense of cash, just like any other data redundancy solution (I.E. RAID1), so choose your methods wisely.
Arbie - Wednesday, November 15, 2017 - link
I suppose it can be sussed out of the performance data, but... can you please say if this drive is shingle technology or not? With any Seagate drive that's one of my first questions, and they seem to have stopped identifying it in the literature.ganeshts - Wednesday, November 15, 2017 - link
I already clarified in the introductory text with an edit, and also in a comment below - these are NOT shingled drives, but PMR platters in a sealed helium-filled enclosure.Fallen Kell - Wednesday, November 15, 2017 - link
Exactly. Now one thing that isn't being mentioned that is very important as we get into these bigger and bigger hard drives within use in RAID systems is the time to rebuild and single read failure rates. That 12TB drive in full use on a RAID 5 system will take over 18 hours just to read the other disks inside the RAID group, factor in 14 hours to write the parity data to the new disk and give a 10% overhead for calculating the parity, and you are looking at around 36 hours assuming no other activity is happening on the RAID set to rebuild from a failed disk. If during those 36 hours a single read failure occurs (on a RAID 5), you have just lost all your data.This is why as has been stated that things like RAID 6 has been developed, but we are now pushing the boundaries of what RAID 6 can protect against, and really need to be using RAID 5+1 or similar, but that costs double the amount of hard drives to implement.
wumpus - Thursday, November 16, 2017 - link
These issues have mostly been proven to be overkill, but I doubt I'd trust even Seagates even in RAID 6 (and then some) [having two arrays of RAID 5 means your software is a kludge. That's just fundamentally stupid and you should be really looking into some sort of Reed-Solomon based system with many ecc drives. But unfortunately "known good RAID 5" beats "insufficiently tested reed solomon encoding" so I understand how it gets used. Doesn't make it any less of a kludge] .Also remember that the bit error rate of 10^15 doesn't mean "expect 1 bit every 10^15 read/writes" but really "expect an aligned 4kbyte of garbage every 8*4096*10^15", so the calculations are a bit different. The internals of hard drives mean either the whole sector is good or it is entirely garbage, you don't individual bit errors.
And if "you just lost all your data" really happens, you have a pretty strange dataset that can't take a single aligned 4k group of garbage (most filesystems store multiple copies of critical data, so that wouldn't be an issue).
Even if you did, you would just break out the tapes and reload (which unfortunately is much, much longer than 36 hours). When *arrays* of 12TB make sense, you are definitely in tape backup land. Hopefully you have a filesystem/backup system that can tag the error to the file (presumably to the RAID sector size) and simply reload the failed RAID sector from tape (because otherwise you will be down for weeks).
GreenReaper - Sunday, September 2, 2018 - link
I think your sums are a little off - it doesn't have to be a serial operation. A good RAID solution will rebuild by reading and writing at the same time. However, I/O contention on reads *can* kill a rebuild, and this can easily turn an operation which "should" take a day into a week-long saga.bigboxes - Friday, November 17, 2017 - link
One more time... RAID is not backup. Doesn't matter if you have the drive mirrored. If a file gets corrupted/deleted on one drive, then you have the same issue on the mirrored drive.Pinn - Thursday, November 16, 2017 - link
Store less porn, Glock24.Samus - Thursday, November 16, 2017 - link
I'd put my family in a Ford Pinto before I put 12TB of data on a Seagate.