Gemini Lake SFF PC Showdown: Intel's June Canyon (NUC7PJYH) and ECS's LIVA Z2 Reviewed
by Ganesh T S on December 20, 2018 8:00 AM ESTMiscellaneous Performance Metrics
This section looks at some of the other commonly used benchmarks representative of the performance of specific real-world applications.
3D Rendering - CINEBENCH R15
We use CINEBENCH R15 for 3D rendering evaluation. The program provides three benchmark modes - OpenGL, single threaded and multi-threaded. Evaluation of different PC configurations in all three modes provided us the following results.
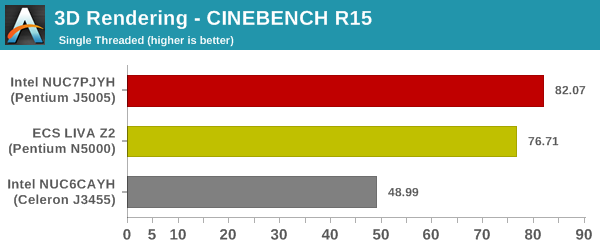
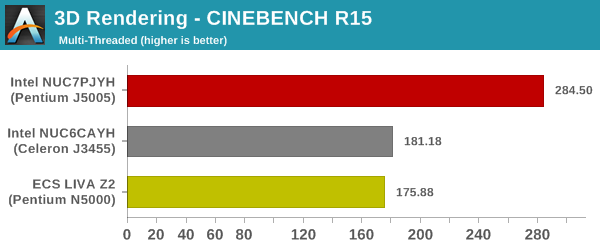
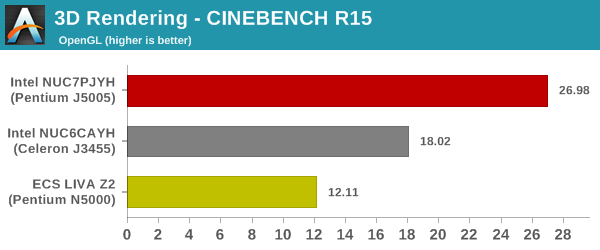
The ECS LIVA Z2 suffers a bit in the OpenGL case, but, is neck and neck with the Arches Canyon NUC in the multi-threaded, and far ahead in the single-threaded case.
x265 Benchmark
Next up, we have some video encoding benchmarks using x265 v2.8. The appropriate encoder executable is chosen based on the supported CPU features. In the first case, we encode 600 1080p YUV 4:2:0 frames into a 1080p30 HEVC Main-profile compatible video stream at 1 Mbps and record the average number of frames encoded per second.
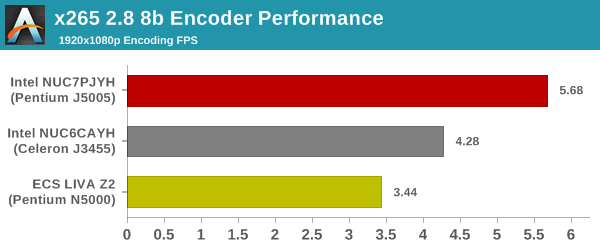
Our second test case is 1200 4K YUV 4:2:0 frames getting encoded into a 4Kp60 HEVC Main10-profile video stream at 35 Mbps. The encoding FPS is recorded. Unfortunately, both Gemini Lake systems were unable to complete this benchmark, exiting abruptly in the middle. The Arches Canyon encoded the 4K stream at 0.36 fps.
7-Zip
7-Zip is a very effective and efficient compression program, often beating out OpenCL accelerated commercial programs in benchmarks even while using just the CPU power. 7-Zip has a benchmarking program that provides tons of details regarding the underlying CPU's efficiency. In this subsection, we are interested in the compression and decompression rates when utilizing all the available threads for the LZMA algorithm.
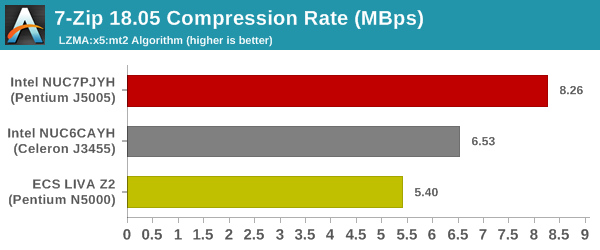
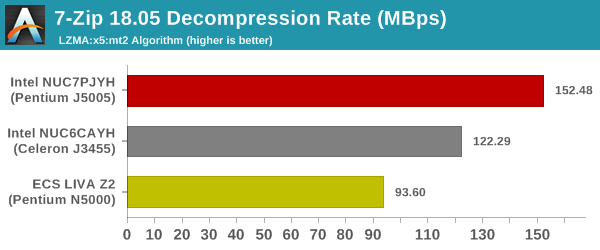
In addition to the CPU, the RAM also plays a role here. ECS's decision to equip only one of the two SODIMM slots with RAM could be the culprit here.
Cryptography Benchmarks
Cryptography has become an indispensable part of our interaction with computing systems. Almost all modern systems have some sort of hardware-acceleration for making cryptographic operations faster and more power efficient. In this sub-section, we look at two different real-world applications that may make use of this acceleration.
BitLocker is a Windows features that encrypts entire disk volumes. While drives that offer encryption capabilities are dealt with using that feature, most legacy systems and external drives have to use the host system implementation. Windows has no direct benchmark for BitLocker. However, we cooked up a BitLocker operation sequence to determine the adeptness of the system at handling BitLocker operations. We start off with a 2.5GB RAM drive in which a 2GB VHD (virtual hard disk) is created. This VHD is then mounted, and BitLocker is enabled on the volume. Once the BitLocker encryption process gets done, BitLocker is disabled. This triggers a decryption process. The times taken to complete the encryption and decryption are recorded. This process is repeated 25 times, and the average of the last 20 iterations is graphed below.
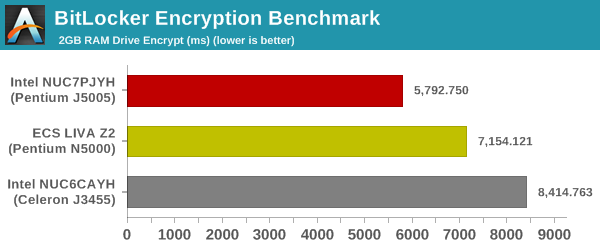
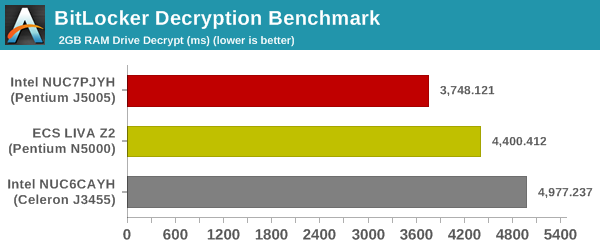
Since all the considered CPUs have AES-NI capabilities, the above benchmark is representative of the sustainable clock speed and also the RAM characteristics.
Creation of secure archives is best done through the use of AES-256 as the encryption method while password protecting ZIP files. We re-use the benchmark mode of 7-Zip to determine the AES256-CBC encryption and decryption rates using pure software as well as AES-NI. Note that the 7-Zip benchmark uses a 48KB buffer for this purpose.
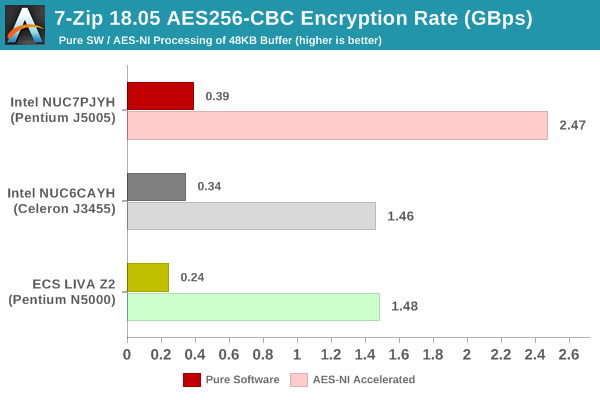
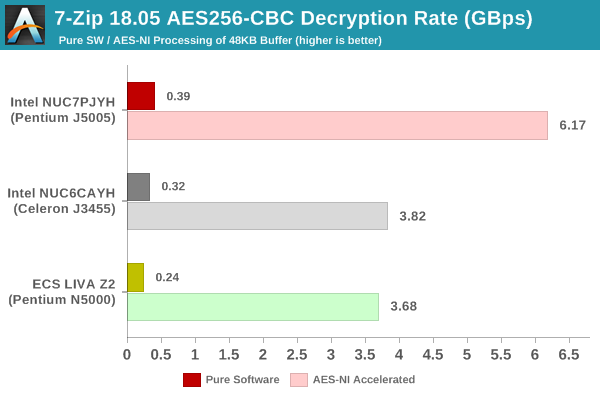
This shows that the relative numbers are similar to the ones observed in other benchmarks.
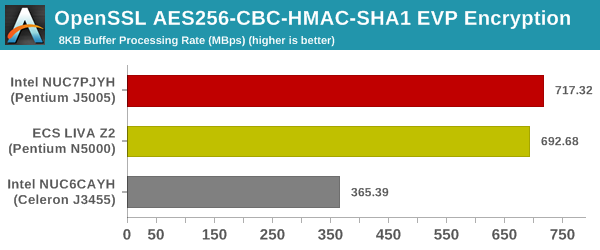
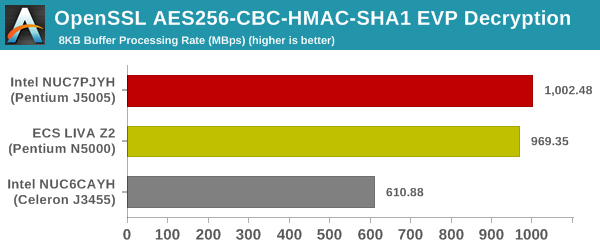
Yet another cryptography application is secure network communication. OpenSSL can take advantage of the acceleration provided by the host system to make operations faster. It also has a benchmark mode that can use varying buffer sizes. We recorded the processing rate for a 8KB buffer using the hardware-accelerated AES256-CBC-HAC-SHA1 feature.
Agisoft Photoscan
Agisoft PhotoScan is a commercial program that converts 2D images into 3D point maps, meshes and textures. The program designers sent us a command line version in order to evaluate the efficiency of various systems that go under our review scanner. The command line version has two benchmark modes, one using the CPU and the other using both the CPU and GPU (via OpenCL). We present the results from our evaluation using the CPU mode only. The benchmark (v1.3) takes 84 photographs and does four stages of computation:
- Stage 1: Align Photographs (capable of OpenCL acceleration)
- Stage 2: Build Point Cloud (capable of OpenCL acceleration)
- Stage 3: Build Mesh
- Stage 4: Build Textures
We record the time taken for each stage. Since various elements of the software are single threaded, and others multithreaded, it is interesting to record the effects of CPU generations, speeds, number of cores, and DRAM parameters using this software.
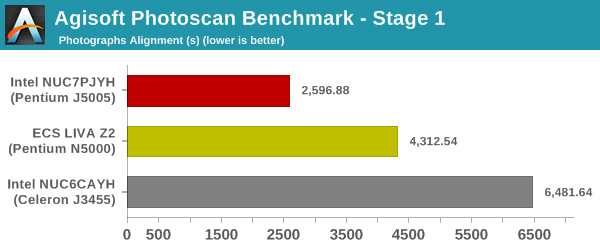
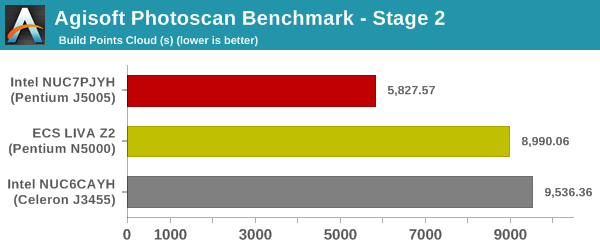
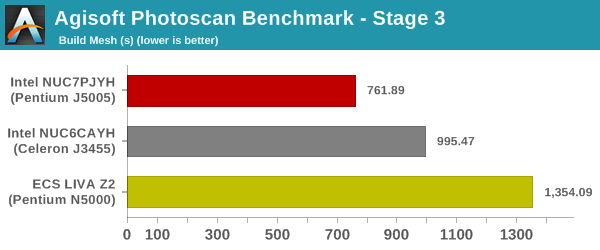
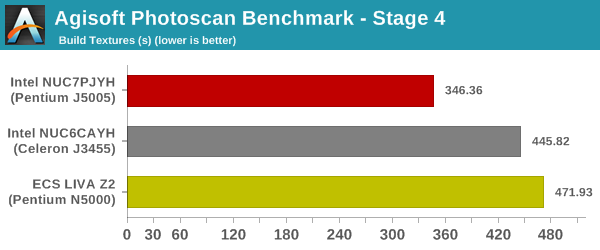
Stage 3 is likely memory performance-limited, unlike the first two stages that are reflective of the single-threaded performance capabilities.
Dolphin Emulator
Wrapping up our application benchmark numbers is the new Dolphin Emulator (v5) benchmark mode results.
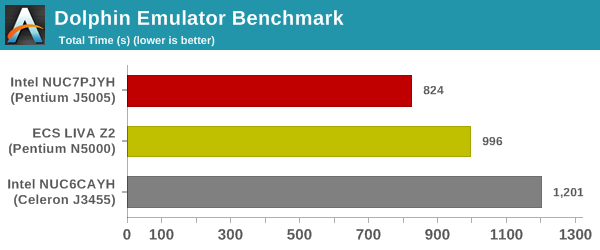
This is again a test of the CPU capabilities, and the ordering expected based on the previous results is seen here too.








59 Comments
View All Comments
mode_13h - Friday, December 21, 2018 - link
I think the main reason for Intel doubling last-level cache vs. Apollo Lake is all the cheapo systems using this in single-channel mode.IntelUser2000 - Thursday, December 20, 2018 - link
"Doubling the internal cache has led to significant performance increase in many real-life workloads."Come on. It's not due to cache. Goldmont Plus cores in Gemini Lake has substantial architectural improvements. Doubled caches are usually responsible for maybe 5% increase in performance.
shelbystripes - Friday, December 21, 2018 - link
Ummm... that’s not really a valid assumption. Sure, if the system already has enough cache, adding more cache will not substantially increase performance.But the cache size is actually small enough to restrain performance (which can happen with these smaller, lower-cost parts). The “doubling” here is going from 2MB to 4MB L2 cache, which for the quad-core designs compared here, means effectively from 0.5MB per core to 1MB of L2 cache per core.
That sounds like a lot of L2 cache, until you realize there’s no L3 cache. That’s it, 0.5-1MB per core of last-level cache, and then you’re going to system RAM.
Is there even an Intel Core CPU made today with only 0.5MB of last level cache? Those tend to have only 256KB of L2, but then at least 1MB of L3 per core. That’s enough cache that adding more cache won’t help you much. Given the smaller, simpler design of Atom, I’m not surprised going up to 1MB of L2 cache per core would yield substantial performance benefits.
Brunnis - Friday, December 21, 2018 - link
Goldmont Plus has substantial architectual enhancements that are much more likely to account for the lion’s share of the performance increase. The article makes it seem Goldmont Plus is mainly about larger L2, which is a bit misleading. See this link:https://en.wikichip.org/wiki/intel/microarchitectu...
Brunnis - Friday, December 21, 2018 - link
Even smaller compute heavy benchmarks perform 20-30% faster, which is usually not the case for a mere L2 size increase (I’ve never seen that, at least).mode_13h - Friday, December 21, 2018 - link
The performance impact of cache is highly workload-dependent. However, it does sound like there are some significant improvements:https://en.wikichip.org/wiki/goldmont_plus#Key_cha...
Smell This - Thursday, December 20, 2018 - link
So ...How many tens of billions of dollars has Chipzilla spent subsidizing the 'Next Units' and Atom 'Fails'?
The 'new' NUCs are not, really, all that. An AMD Ryzen V1000 SoC mini-ITX FP5 BGA at 12/14nm would 'Temash' the Atom at 10-12w.
ZOLTAC ... make it so.
Death666Angel - Thursday, December 20, 2018 - link
I'd take some more AM4 mSTX motherboards. There are quite a few Intel ones, but the beefier iGPU for AMD would make for a more well rounded system.Alien88 - Saturday, December 22, 2018 - link
Check out the Udoo Bolt...LMonty - Friday, December 21, 2018 - link
Hello Ganesh, could you pls. confirm whether the NUC operates in dual channel mode when using 32GB of RAM? I saw one review on Amazon complaining that his J5005 NUC was running in single channel mode, when using 2x8GB sticks (16GB total).