Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTE1 Implementation & Performance Targets
The Neoverse E1 CPU being a small CPU core aimed at cost-effective and dense implementation naturally needs to be quite small, as well as power efficient.
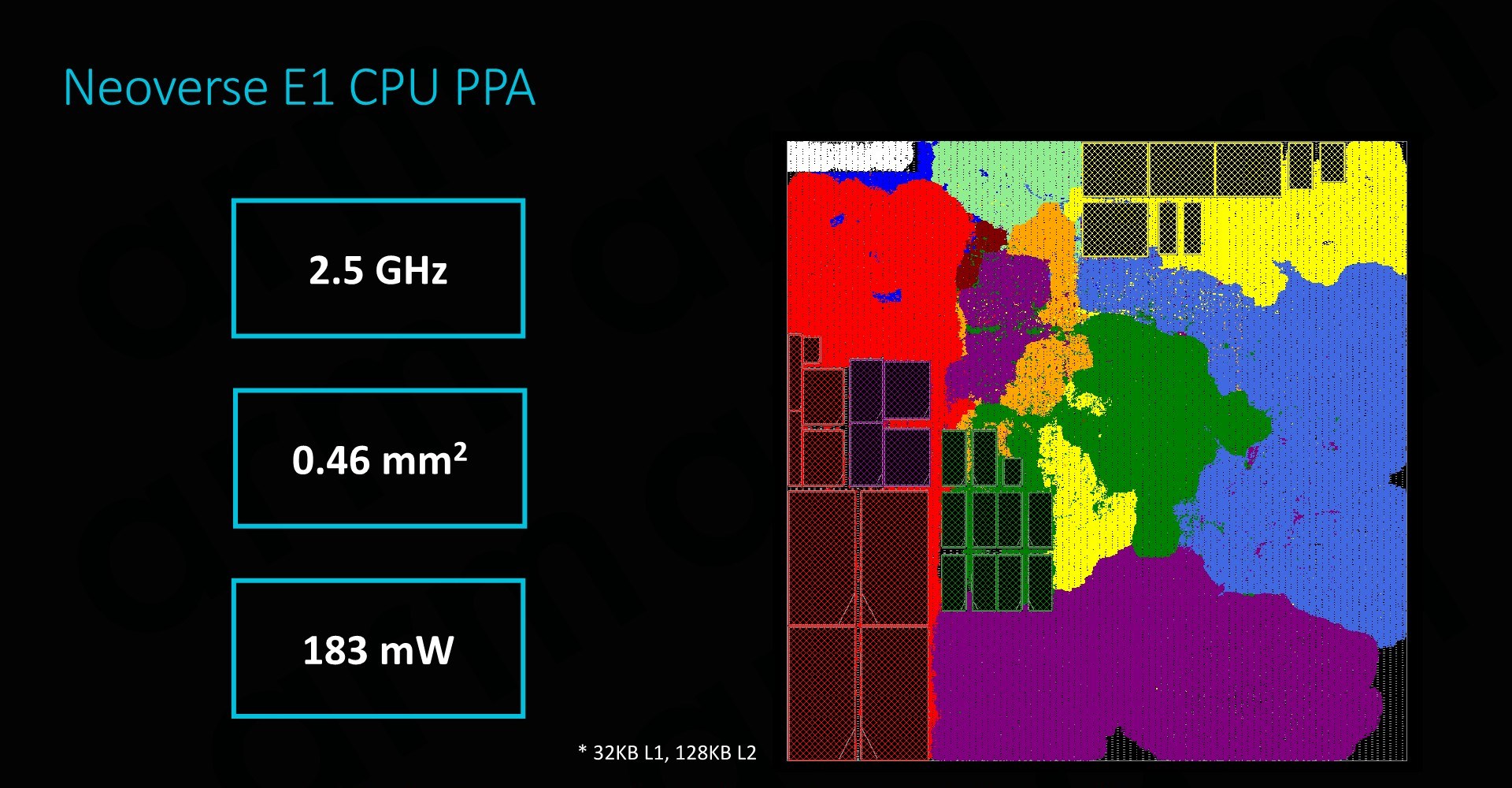
Implemented on a 7nm process, Arm physical design team is able to get an E1 CPU core with 32KB L1 and 128KB L2 cache down to 0.46mm² - all while reaching a high clock of 2.5GHz and a power consumption of 183mW. The higher clock was a surprise as it is quite notably higher than what we’ve seen vendors achieve on the A55 – although we are talking about different implementation targets.
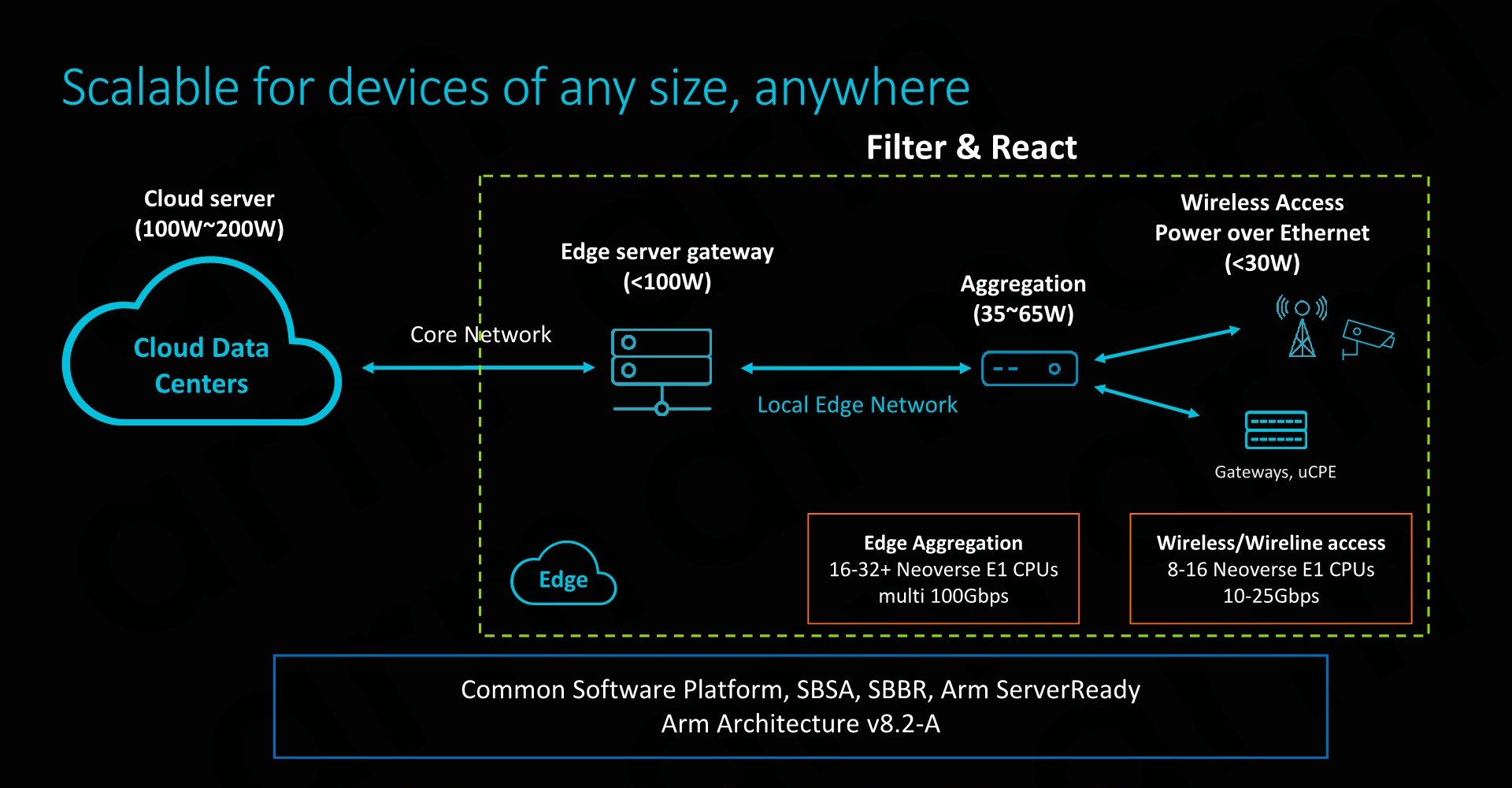
Arm envisions the most popular implementations of the E1 to be found in lower power edge applications. At the lower end, ranging from 8-16 cores would be a good for wireless access points and gateways, delivering data throughputs in the 10-25Gbps rang. A tier up we would see 16-32 core designs in use-cases such as edge data aggregation deployments, achieving data rates in the 100’s of Gbps.
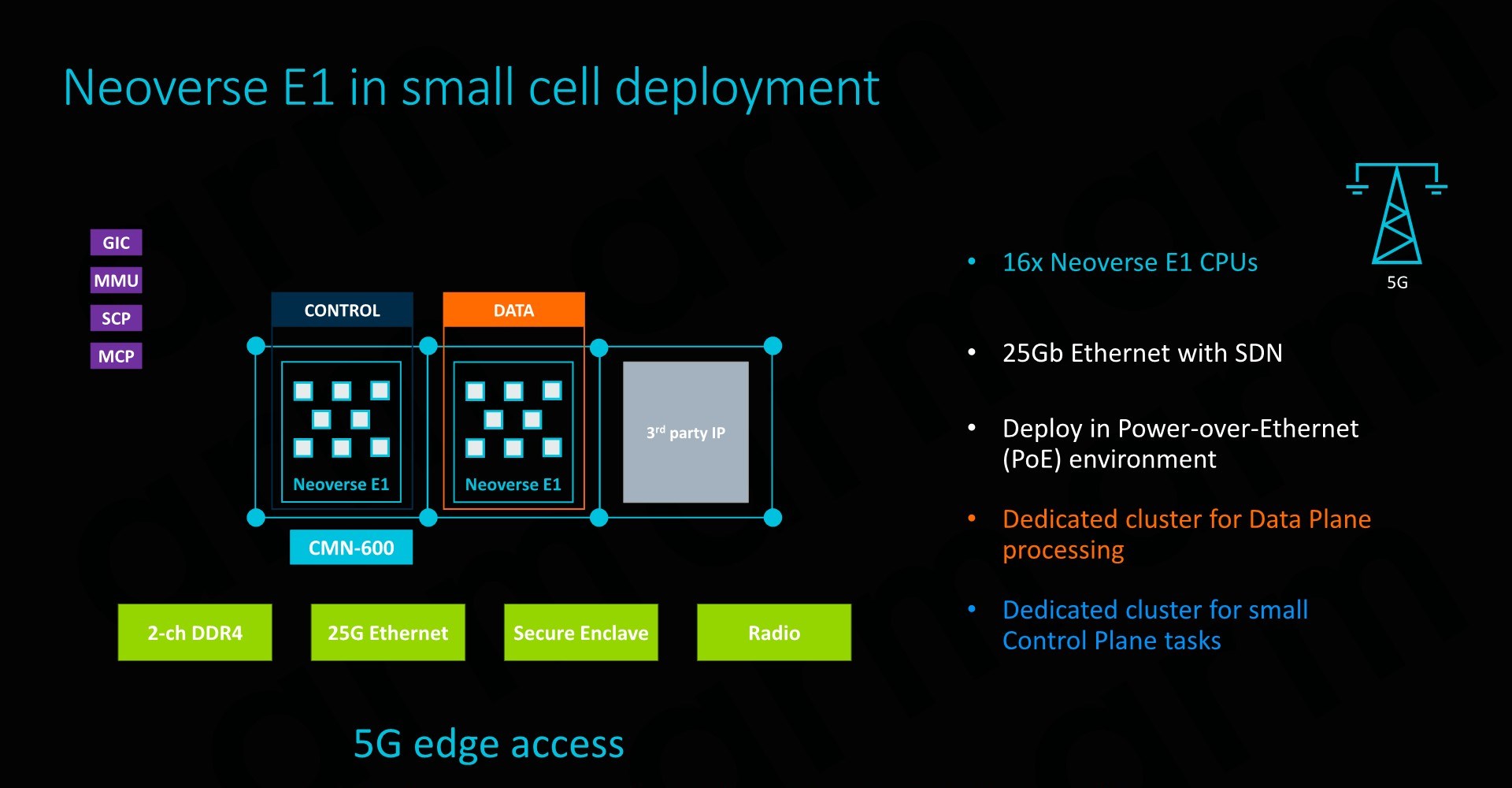
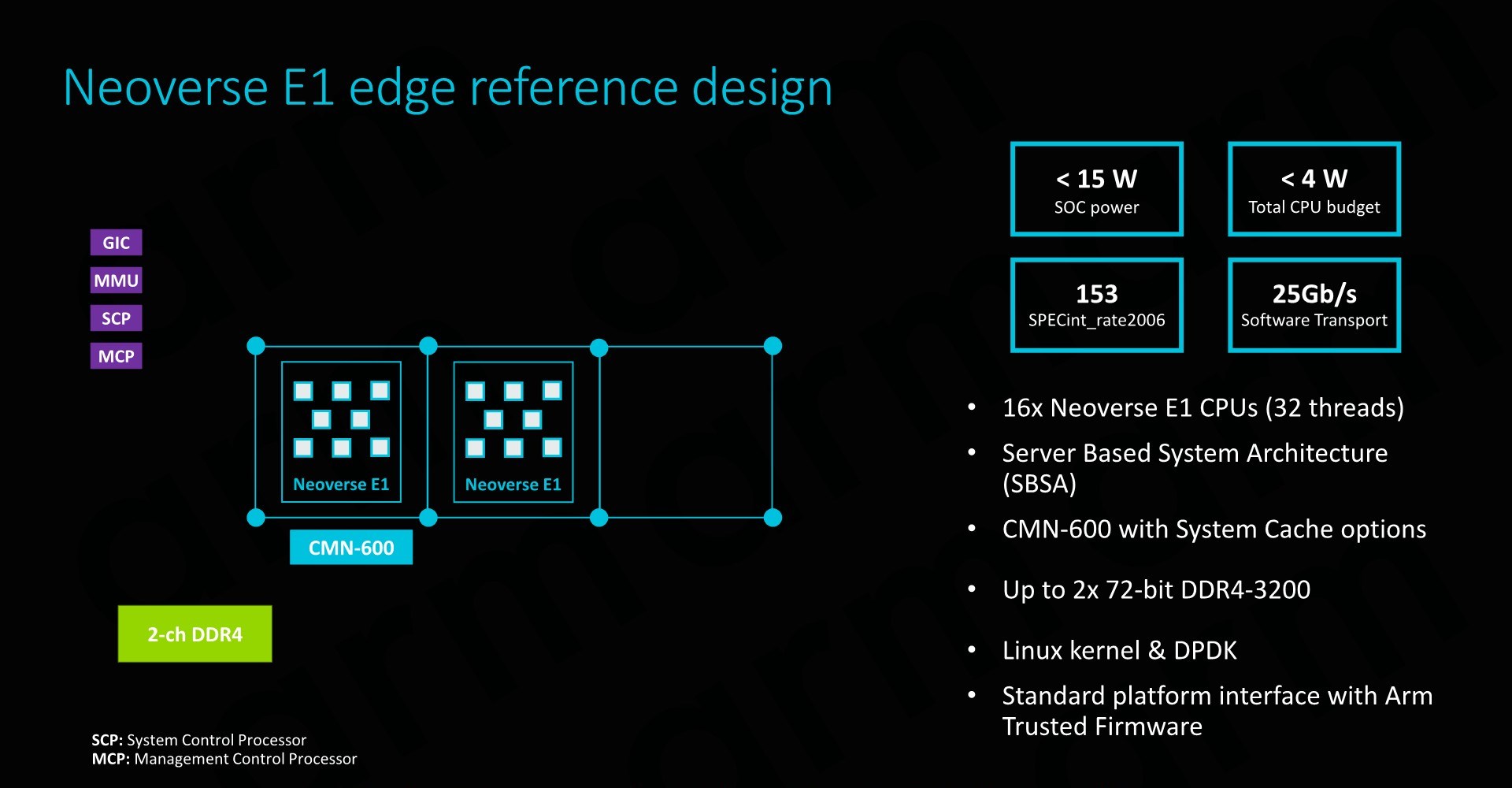
The Neoverse E1 reference design that Arm offers and sees as being the most popular “sweet-spot” is based on a 16 core design. Here we have to clusters of 8 cores in a small CMN-600 2x4 mesh network, allowing for system cache options as well as integration of possible additional third-part IP. The envisioned memory system would be a 2-ch DDR4 configuration.
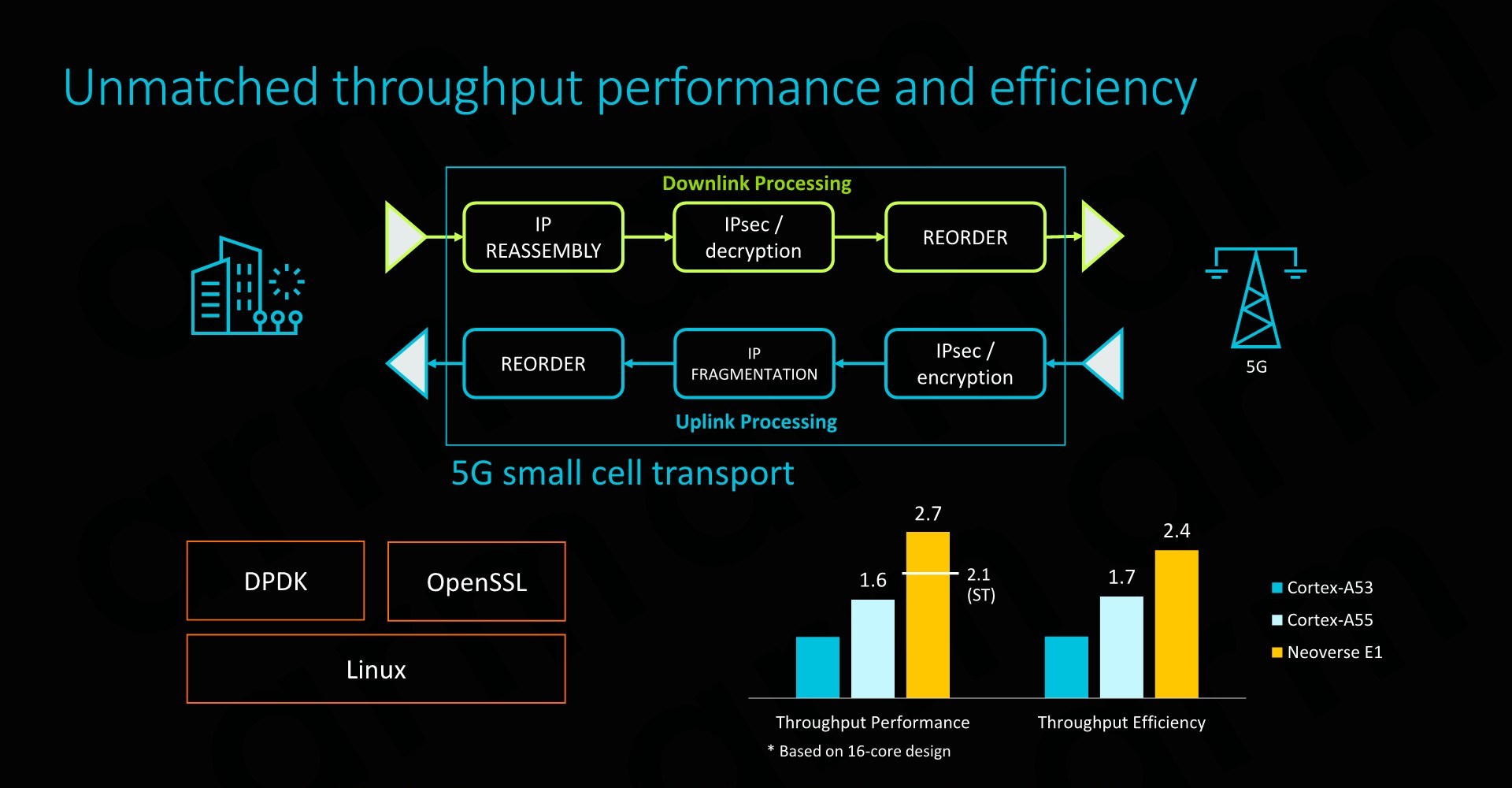
Such as SoC would have a power consumption of less than 15W, of which less than 4W would actually be used by the CPU cores. SPECint2006 rate scores would come in at 153 – which given the actual size and power consumption of the platform is quite impressive. The system would also be capable of 25Gb/s network throughput, enabled solely by a software transport layer (Meaning no hardware acceleration).
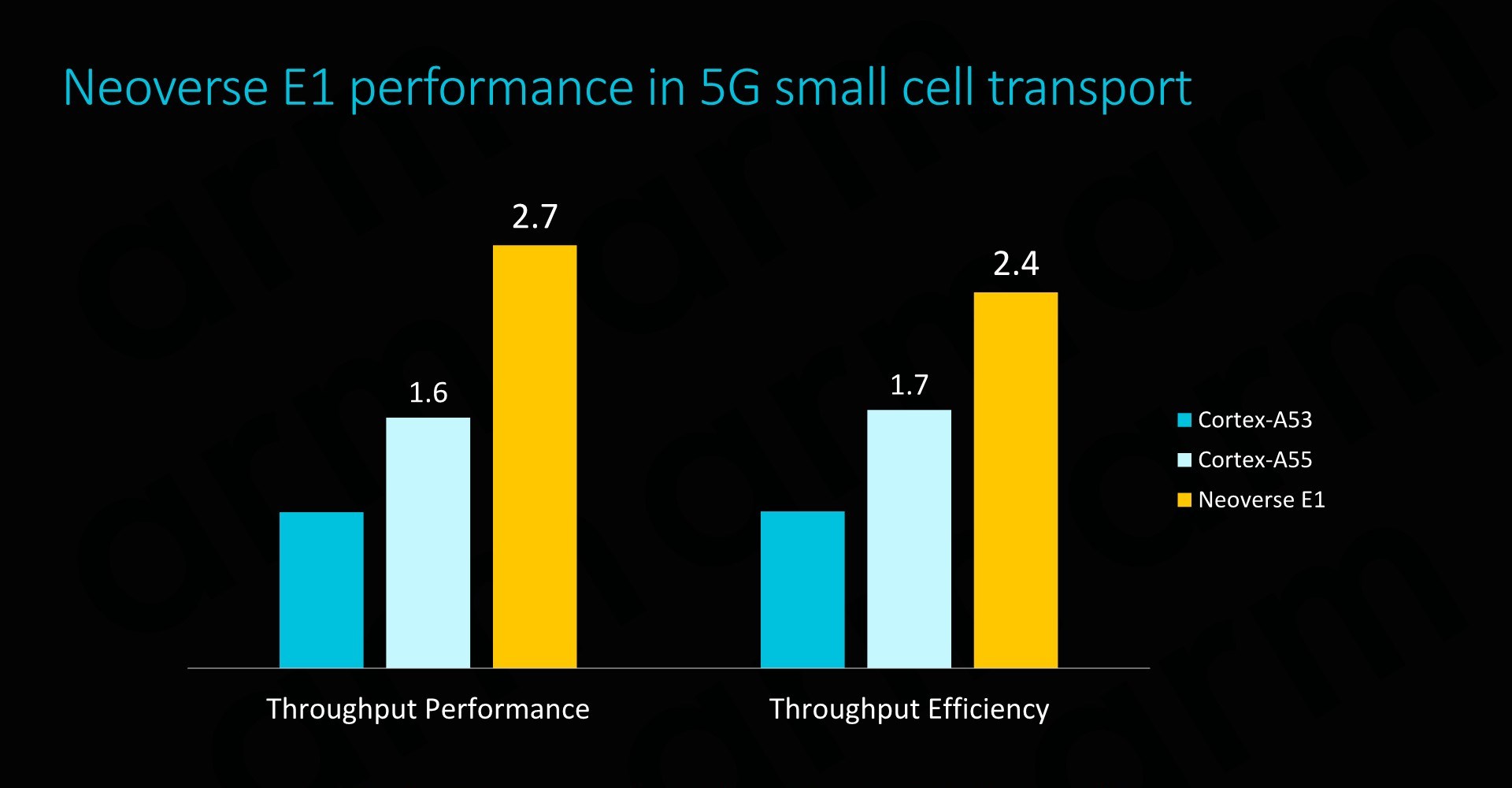
On a per-core comparison to the Cortex A53 and A55, the new E1 CPU would again offer significant throughput performance benefits, but also very importantly it would represent an efficiency boost compared to its predecessors (ISO process comparison).








101 Comments
View All Comments
blu42 - Thursday, February 21, 2019 - link
Yep. While ISA may not matter as an aggregate over the set of all tasks, ISAs matter very much when it comes to the performance of any individual task, just the same way as ASICs matter versus gen-purpose CPUs for any given task. One can think of ASICs as an extreme-case specialization of gen-purpose ISAs.Meteor2 - Wednesday, February 20, 2019 - link
Indeed, and reality is that all architectures are converging in terms of performance. It’s just a question of how much money any given manufacturer wants to invest. Intel cut R&D and the results are plain. AMD invested wisely. What Apple has achieved with the ARM ISA is phenomenal. Goodness knows what they could do if they turned their attention away from mobile but goodness knows how much it cost, too.Vitor - Wednesday, February 20, 2019 - link
Although the article is about servers and such, I can't help thinking that in less than a decade RISC CPUs can overtake the deskop/notebook market.And, corretct if I'm wrong, RISC is inherently more efficient than X86 derivates.
SarahKerrigan - Wednesday, February 20, 2019 - link
The evidence for "inherently more efficient" is pretty shaky, although I'd venture that validation of ARM cores is considerably simpler than validation of x86.That being said, ARM has been delivering rapidly and consistently on uarch, and Intel has not.
hMunster - Wednesday, February 20, 2019 - link
ARM is playing catch-up to Intel which got to the point of "no more low hanging fruit" much earlier.Wilco1 - Wednesday, February 20, 2019 - link
Well as an example Intel was unable to design competitive SoCs for the mobile market despite having a process advantage, investing $10+ Billion and even paying various companies to use their chips - "contra-revenue". There is no doubt the complexity of x86 translates into a significant overhead in design and verification, area, power and (at the low end) performance.hMunster - Wednesday, February 20, 2019 - link
The RISC vs. CISC debate does not really matter much anymore.HStewart - Wednesday, February 20, 2019 - link
A lot of this is because CISC process can now handle multiple microinstructions per clock cycle taking advantage of RISC smaller instruction away.But software compatibility is the major concern with this and Microsoft has many failed attempts to try to change this dependency.
FunBunny2 - Wednesday, February 20, 2019 - link
"A lot of this is because CISC process can now handle multiple microinstructions per clock cycle taking advantage of RISC smaller instruction away."that's a testable assertion. not by me, however. the execution of multiple microinstructions by CISC ISA machines doesn't mean, ceteris paribus, that the overlying CISC instruction runs as efficiently as a native RISC instruction; it just must run through the microinstructions. to the extent that CISC ISAs are really executed as some RISC machine on the silicon, that doesn't mean, apples to apples, that said CISC machine executes as efficiently as a native RISC machine. (native RISC does make headaches for the compiler writer, no doubt.) I'd wager that the real reason for RISC microarch was the desire to continue with X86 object code with a bit more performance back when the transistor budget began expanding, but not enough to build the entire ISA in silicon. and to keep the compiler writer from having to continually update as the real ISA (RISC) keeps changing. die shots of current cpu show that the 'core' is a diminishing percent of the real estate.
the still unanswered question: why did Intel/AMD not use the exploding transistor budget to execute the entire instruction set in hardware, but to create these behind-the-scenes RISC machines?
wumpus - Wednesday, February 20, 2019 - link
From memory, Dec was able to make VAX four times faster by pipelining the microcode from VAX instructions compared to "executing the VAX instruction all at once faster". VAX was about the CISCisest CISC that ever CISCed (and sold successfully. I think Intel's BiiN was worse).Dec also made Alpha, which even the first iteration was another 4 times faster than the "pipelined microcode" VAX.
And this was all single issue. Don't even think of trying to issue multiple "full CISC" instructions at once.