AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Performance Claims of Zen 2
At Computex, AMD announced that it had designed Zen 2 to offer a direct +15% raw performance gain over its Zen+ platform when comparing two processors at the same frequency. At the same time, AMD also claims that at the same power, Zen 2 will offer greater than a >1.25x performance gain at the same power, or up to half power at the same performance. Combining this together, for select benchmarks, AMD is claiming a +75% performance per watt gain over its previous generation product, and a +45% performance per watt gain over its competition.
These are numbers we can’t verify at this point, as we do not have the products in hand, and when we do the embargo for benchmarking results will lift on July 7th. AMD did spend a good amount of time going through the new changes in the microarchitecture for Zen 2, as well as platform level changes, in order to show how the product has improved over the previous generation.
It should also be noted that at multiple times during AMD’s recent Tech Day, the company stated that they are not interested in going back-and-forth with its primary competition on incremental updates to try and beat one another, which might result in holding technology back. AMD is committed, according to its executives, to pushing the envelope of performance as much as it can every generation, regardless of the competition. Both CEO Dr. Lisa Su, and CTO Mark Papermaster, have said that they expected the timeline of the launch of their Zen 2 portfolio to intersect with a very competitive Intel 10nm product line. Despite this not being the case, the AMD executives stated they are still pushing ahead with their roadmap as planned.
| AMD 'Matisse' Ryzen 3000 Series CPUs | |||||||||||
| AnandTech | Cores Threads |
Base Freq |
Boost Freq |
L2 Cache |
L3 Cache |
PCIe 4.0 |
DDR4 | TDP | Price (SEP) |
||
| Ryzen 9 | 3950X | 16C | 32T | 3.5 | 4.7 | 8 MB | 64 MB | 16+4+4 | 3200 | 105W | $749 |
| Ryzen 9 | 3900X | 12C | 24T | 3.8 | 4.6 | 6 MB | 64 MB | 16+4+4 | 3200 | 105W | $499 |
| Ryzen 7 | 3800X | 8C | 16T | 3.9 | 4.5 | 4 MB | 32 MB | 16+4+4 | 3200 | 105W | $399 |
| Ryzen 7 | 3700X | 8C | 16T | 3.6 | 4.4 | 4 MB | 32 MB | 16+4+4 | 3200 | 65W | $329 |
| Ryzen 5 | 3600X | 6C | 12T | 3.8 | 4.4 | 3 MB | 32 MB | 16+4+4 | 3200 | 95W | $249 |
| Ryzen 5 | 3600 | 6C | 12T | 3.6 | 4.2 | 3 MB | 32 MB | 16+4+4 | 3200 | 65W | $199 |
AMD’s benchmark of choice, when showcasing the performance of its upcoming Matisse processors is Cinebench. Cinebench a floating point benchmark which the company has historically done very well on, and tends to probe the CPU FP performance as well as cache performance, although it ends up often not involving much of the memory subsystem.
Back at CES 2019 in January, AMD showed an un-named 8-core Zen 2 processor against Intel’s high-end 8-core processor, the i9-9900K, on Cinebench R15, where the systems scored about the same result, but with the AMD full system consuming around 1/3 or more less power. For Computex in May, AMD disclosed a lot of the eight and twelve-core details, along with how these chips compare in single and multi-threaded Cinebench R20 results.
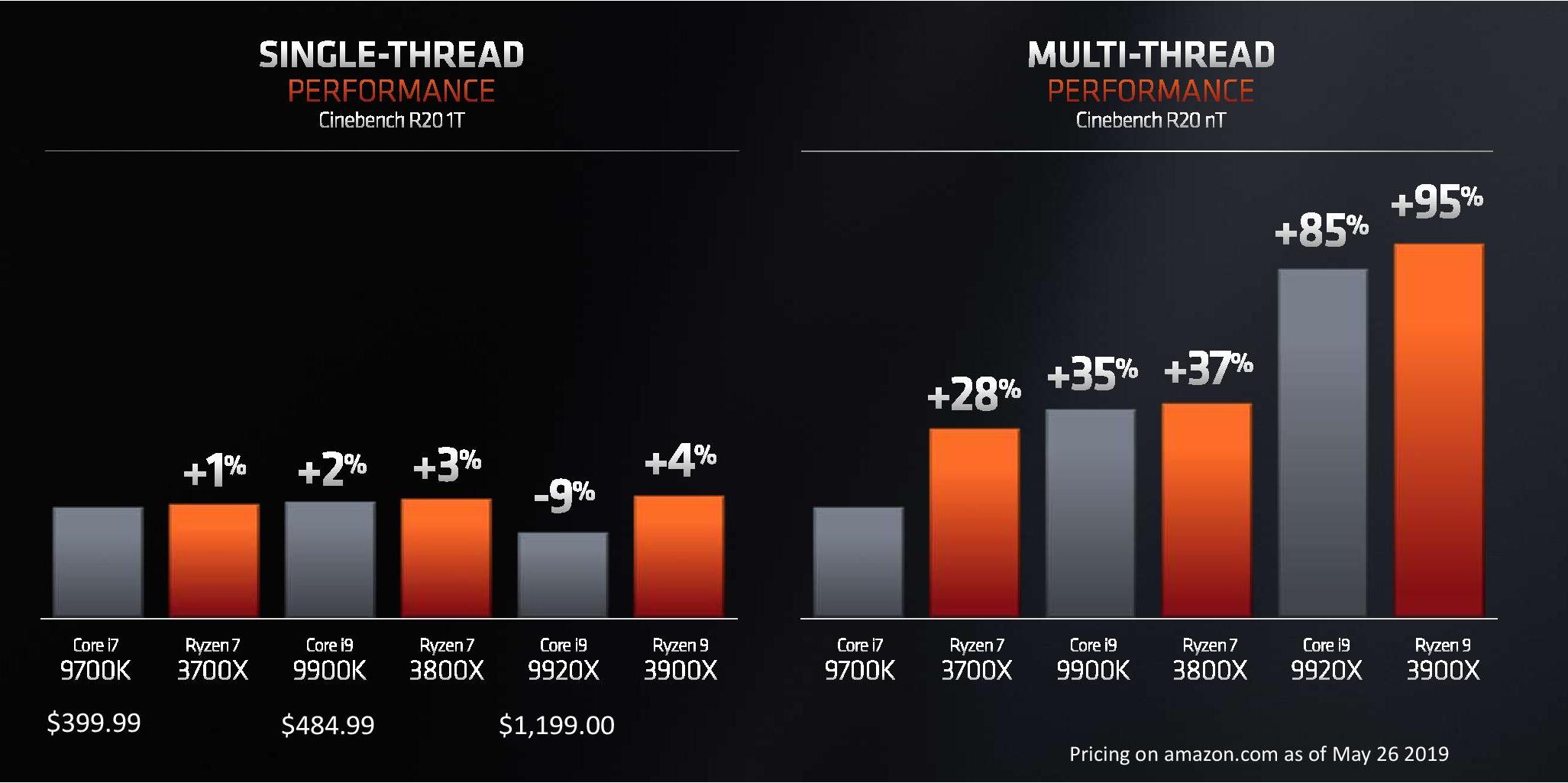
AMD is stating that its new processors, when comparing across core counts, offer better single thread performance, better multi-thread performance, at a lower power and a much lower price point when it comes to CPU benchmarks.
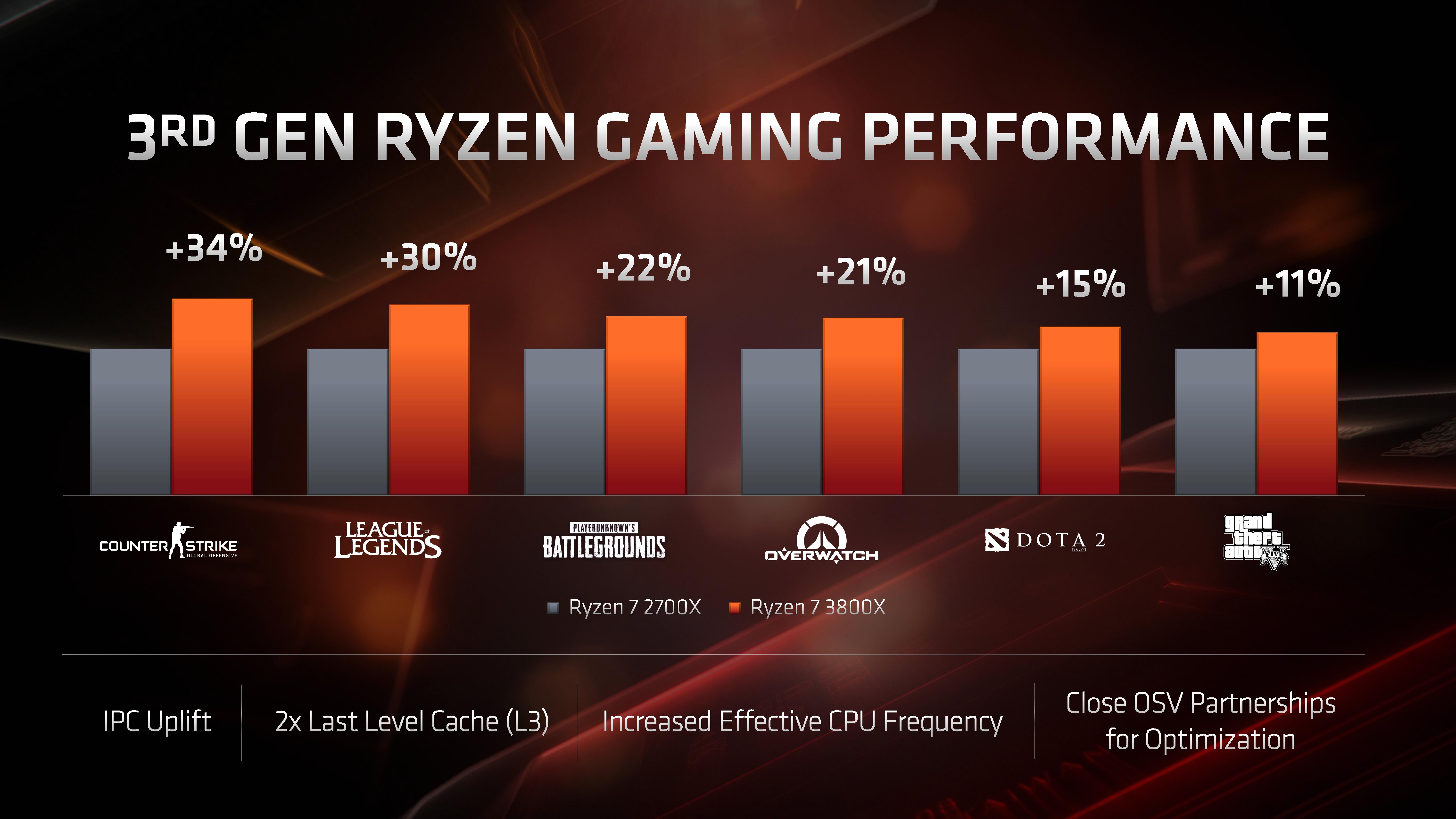
When it comes to gaming, AMD is rather bullish on this front. At 1080p, comparing the Ryzen 7 2700X to the Ryzen 7 3800X, AMD is expecting anywhere from a +11% to a +34% increase in frame rates generation to generation.
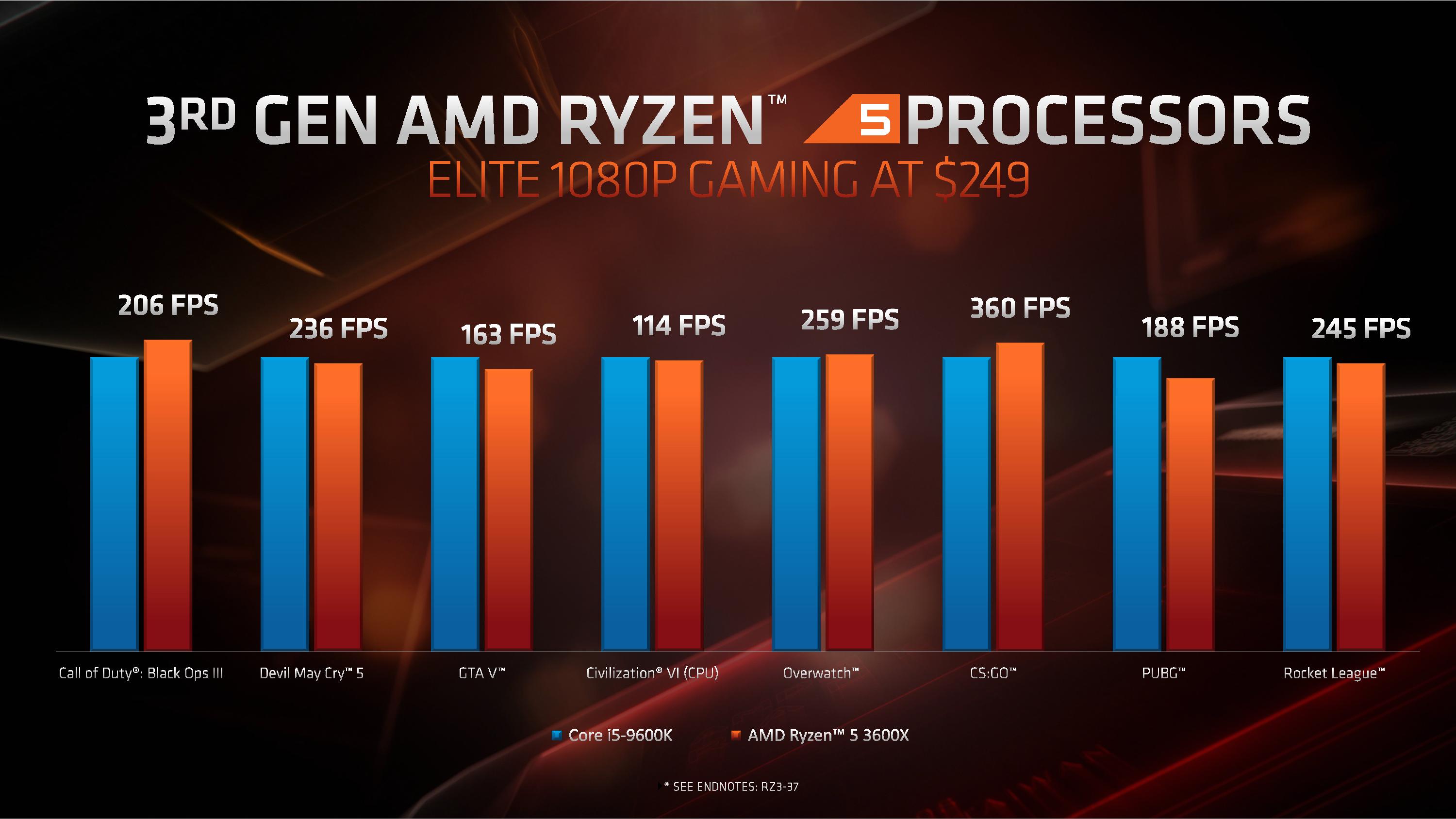
When it comes to comparing gaming between AMD and Intel processors, AMD stuck to 1080p testing of popular titles, again comparing similar processors for core counts and pricing. In pretty much every comparison, it was a back and forth between the AMD product and the Intel product – AMD would win some, loses some, or draws in others. Here’s the $250 comparison as an example:
Performance in gaming in this case was designed to showcase the frequency and IPC improvements, rather than any benefits from PCIe 4.0. On the frequency side, AMD stated that despite the 7nm die shrink and higher resistivity of the pathways, they were able to extract a higher frequency out of the 7nm TSMC process compared to 14nm and 12nm from Global Foundries.

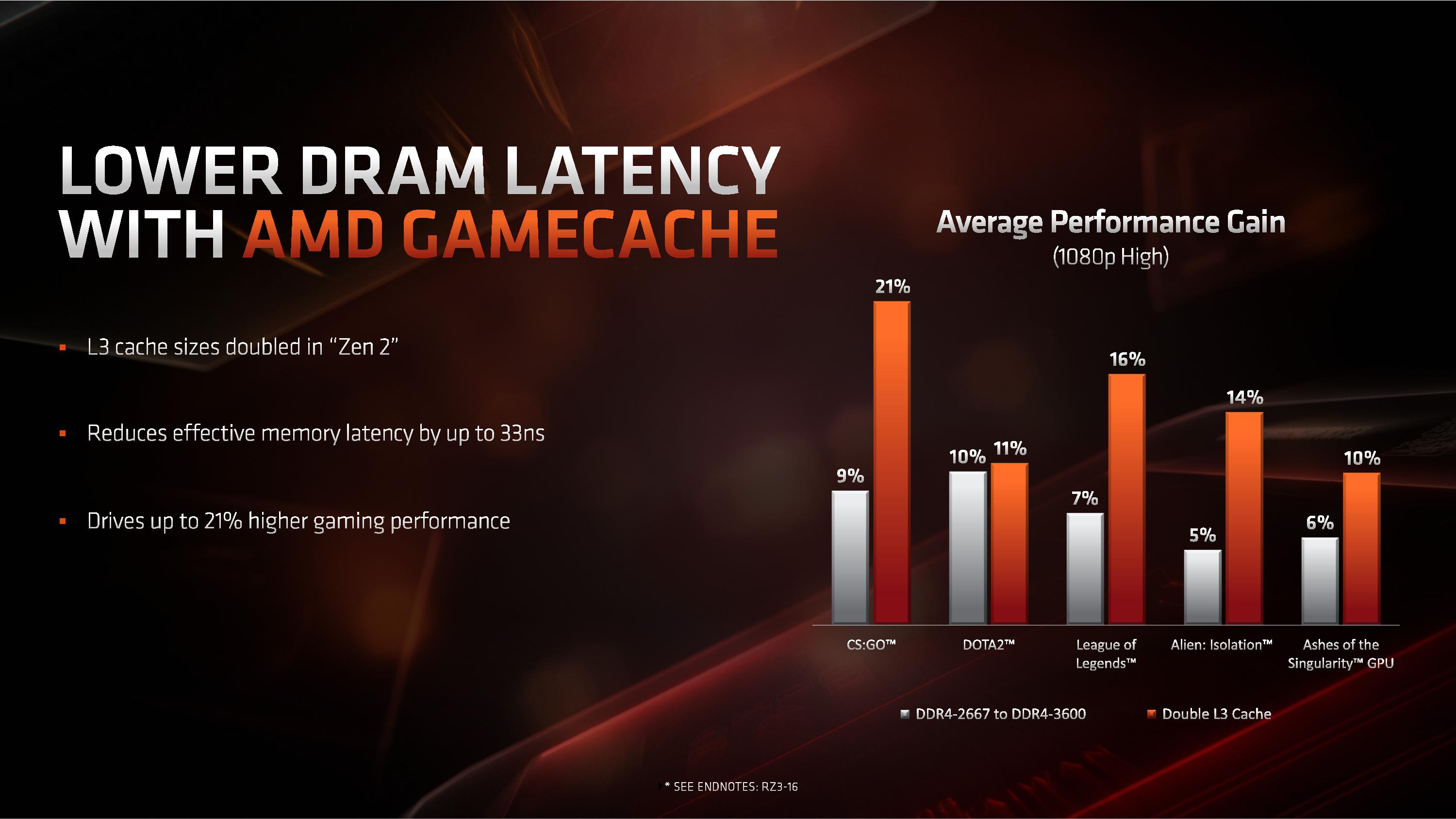
AMD also made commentary about the new L3 cache design, as it moves from 2 MB/core to 4 MB/core. Doubling the L3 cache, according to AMD, affords an additional +11% to +21% increase in performance at 1080p for gaming with a discrete GPU.
There are some new instructions on Zen 2 that would be able to assist in verifying these numbers.








216 Comments
View All Comments
mikato - Tuesday, June 11, 2019 - link
Hehe, yeah I saw that. That was a good one for the marketing team or whoever makes the slides.Atari2600 - Wednesday, June 12, 2019 - link
No, for each of those line items they should have said "Intel only"zalves - Tuesday, June 11, 2019 - link
I really don't understand how one can compare these AMD CPU's with Intel's HEDT, they lack PCIe Lanes and don't support quad-channel memory. And that a huge deal breaker for anyone that wants and needs some serious IO and multi tasking.TheUnhandledException - Tuesday, June 11, 2019 - link
Well that is what Threadripper is for. Can't wait to see the 3000 series Threadrippers.John_M - Tuesday, June 11, 2019 - link
So, 5th generation EPYC codename is going to be either Turin, Bolognia or Florence as Palermo has already been used for Sempron.John_M - Tuesday, June 11, 2019 - link
*that's Bologna, of course. It would be nice to be able to edit posts for typos.WaltC - Tuesday, June 11, 2019 - link
Great read!John_M - Tuesday, June 11, 2019 - link
What is the advantage in halving the L1 instruction cache? Was the change forced by the doubling of its associativity? According to the (I suspect somewhat oversimplified) Wikipedia article on CPU Cache, doubling the associativity increases the probability of a hit by about the same amount as doubling the cache size, but with more complexity. So how is this Zen2 configuration better than that in Zen and Zen+?John_M - Tuesday, June 11, 2019 - link
Ah! It's sort of explained at the bottom of page 7. I had glossed over that because the first two paragraphs were too technical for my understanding. I see that it was halved to make room for something else to be made bigger, which on balance seems to be a successful trade off.arnd - Wednesday, June 12, 2019 - link
More importantly, 32K 8-way is a sweet spot for an L1 cache. This is what AMD is using for the D$ already and what all modern Intel L1 caches (both I and D) are. With eight ways, this is the largest size you can have for a non-aliasing virtually indexed cache using the 4KB page size of the x86 architecture. Having more than eight ways has diminishing returns, so going beyond 32KB requires extra complexity for dealing with aliasing or physically indexed caches like the L2.