AMD’s Mobile Revival: Redefining the Notebook Business with the Ryzen 9 4900HS (A Review)
by Dr. Ian Cutress on April 9, 2020 9:00 AM ESTRenoir: Latency, Caching, and Turbo
Chiplets vs Monolithic
To date, AMD has launched Desktop Ryzen 3000, Threadripper 3000, and EPYC 7002 (Rome) with Zen 2 cores. For all these products, it has placed its Zen 2 cores inside chiplets that connect to a central IO die, which then talks to other chiplets or the main system. In Ryzen 3000 Desktop, we have one or two chiplets paired with an IO die that can handle 24 PCIe 4.0 lanes and two memory channels. In Threadripper 3000, we have up to eight chiplets with an IO die that can handle 64 PCIe 4.0 lanes and four memory channels. In EPYC 7002 (Rome), we have up to eight chiplets with an IO die that can handle 128 PCIe 4.0 lanes and eight memory channels.
For Ryzen Mobile 4000, there are no chiplets – instead we have a traditional single die, which is referred to as a monolithic design. Both the chiplet design and monolithic designs have various benefits and weaknesses.
For the chiplet design, going that route for expensive processors actually helps with costs, yields, and frequency binning. This has also enabled AMD to launch these products earlier, with the end result being better per-core performance (through binning), taking advantage of different process nodes, and providing an overall chip with more die area than a single chip can provide.
The downside of this chiplet design is often internal connectivity. In a chiplet design you have to go ‘off-chip’ to get to anywhere else, which incurs a power and a latency deficit. Part of what AMD did for the chiplet designs is to minimize that, with AMD’s Infinity Fabric connecting all the parts together, with the goal of the IF to offer a low energy per bit transfer and still be quite fast. In order to get this to work on these processors, AMD had to rigidly link the internal fabric frequency to the memory frequency.
With a monolithic design, AMD doesn’t need to apply such rigid standards to maintain performance. In Ryzen Mobile 4000, the Infinity Fabric remains on the silicon, and can slow down / ramp up as needed, boosting performance, decreasing latency, or saving power. The other side is that the silicon itself is bigger, which might be worse for frequency binning or yield, and so AMD took extra steps to help keep the die size small. AMD was keen to point out in its Tech Day for Ryzen Mobile that it did a lot of work in Physical Design, as well as collaborating with TSMC who actually manufactures the designs, in order to find a good balance between die size, frequency, and efficiency.

The Renoir silicon is ~150 square millimeters. (AMD’s official number is 156 mm2, although some other measurements seem to suggest it is nearer 149 mm2.) In that design is eight Zen 2 cores, up to eight enhanced Vega compute units, 24 lanes of PCIe 3.0, and two DDR4-3200 memory channels. This is all built on TSMC’s 7nm manufacturing process (N7)
Latency
Each of the eight Zen 2 cores is split into a quad-core complex (CCX), which gives each set of four cores access to 4 MB of L3 cache, or a total of 8 MB across the chip. In a chiplet design, there are also eight cores per chiplet (two CCXes), but when one CCX needs to communicate to another, it has to go off chip to the central IO die and back again – inside the monolithic Renoir silicon, that request stays on silicon and has a latency/power benefit. We can see this in our core-to-core latency diagram.
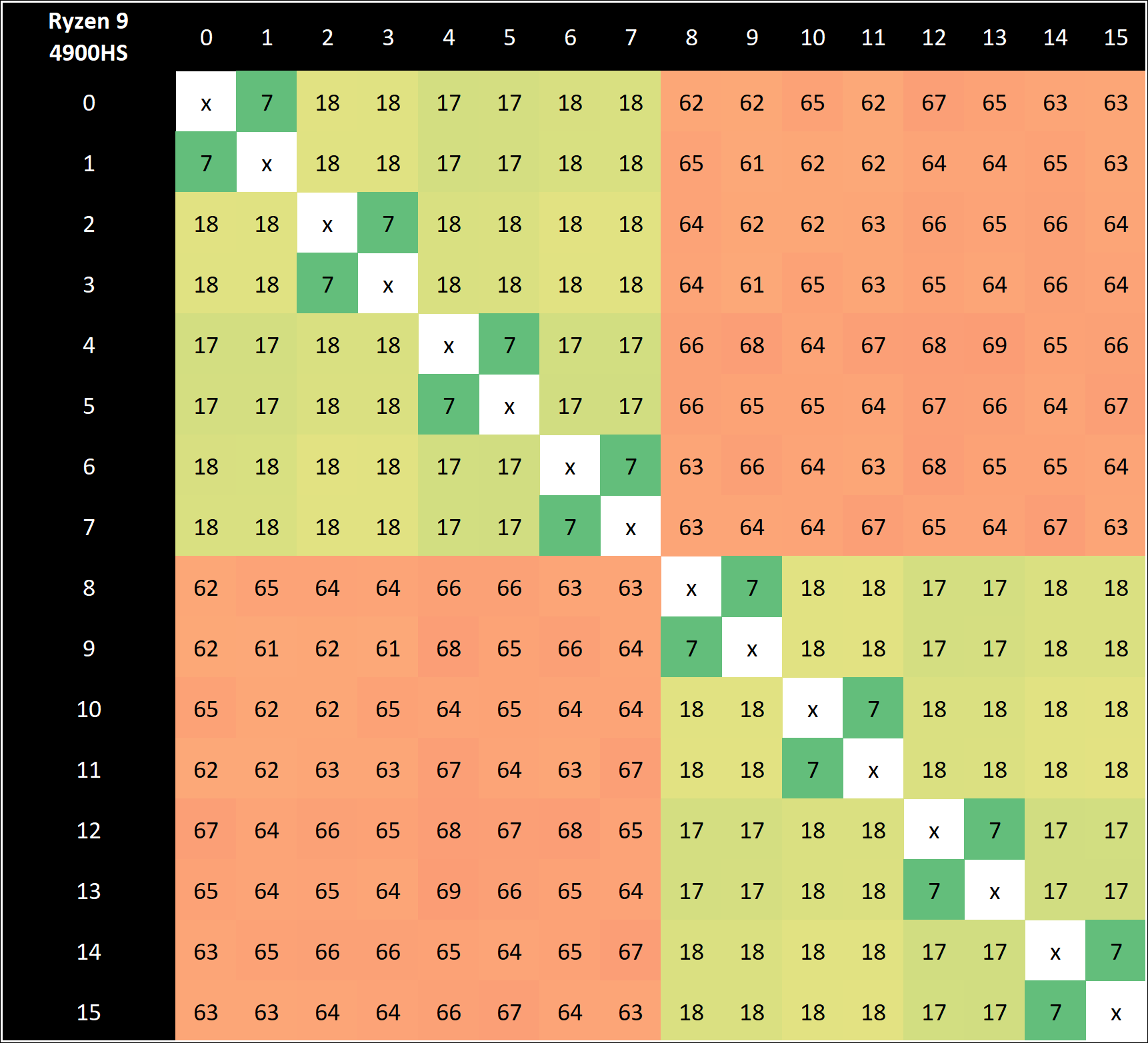
With our 4900HS, we have a 7 nanosecond latency for multithreads pinging inside a core, 17-18 nanosecond latency for threads within a CCX, and a 61-69 nanosecond latency moving across each CCX.
For a Ryzen 9 3950X, with two chiplets, the diagram looks a bit different:
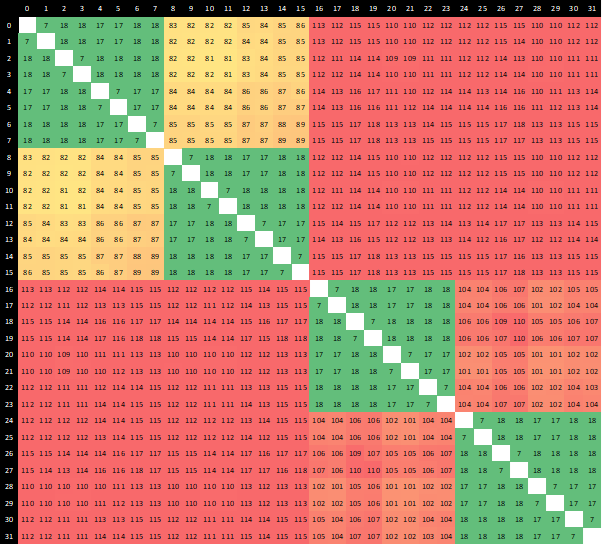
Here we see the same 7 nanoseconds for inside a core, 17-18 nanoseconds between cores in the same CCX, but now we have 81-89 nanoseconds between CCXes in the same chiplet, because we have to go off silicon to the IO die and back again. Then, if we want to go to a CCX on another chiplet, it can take 110-118 nanoseconds, because there’s another hop inside the IO die that needs to occur.
(AMD makes a thread leave the chiplet, even when it’s speaking to another CCX on the same chiplet, because that makes the control logic for the entire CPU a lot easier to handle. This may be improved in future generations, depending on how AMD controls the number of cores inside a chiplet.)
Going back to the Renoir CPU, we can compare this to the Intel Core i7-9750H in our Razer Blade machine:
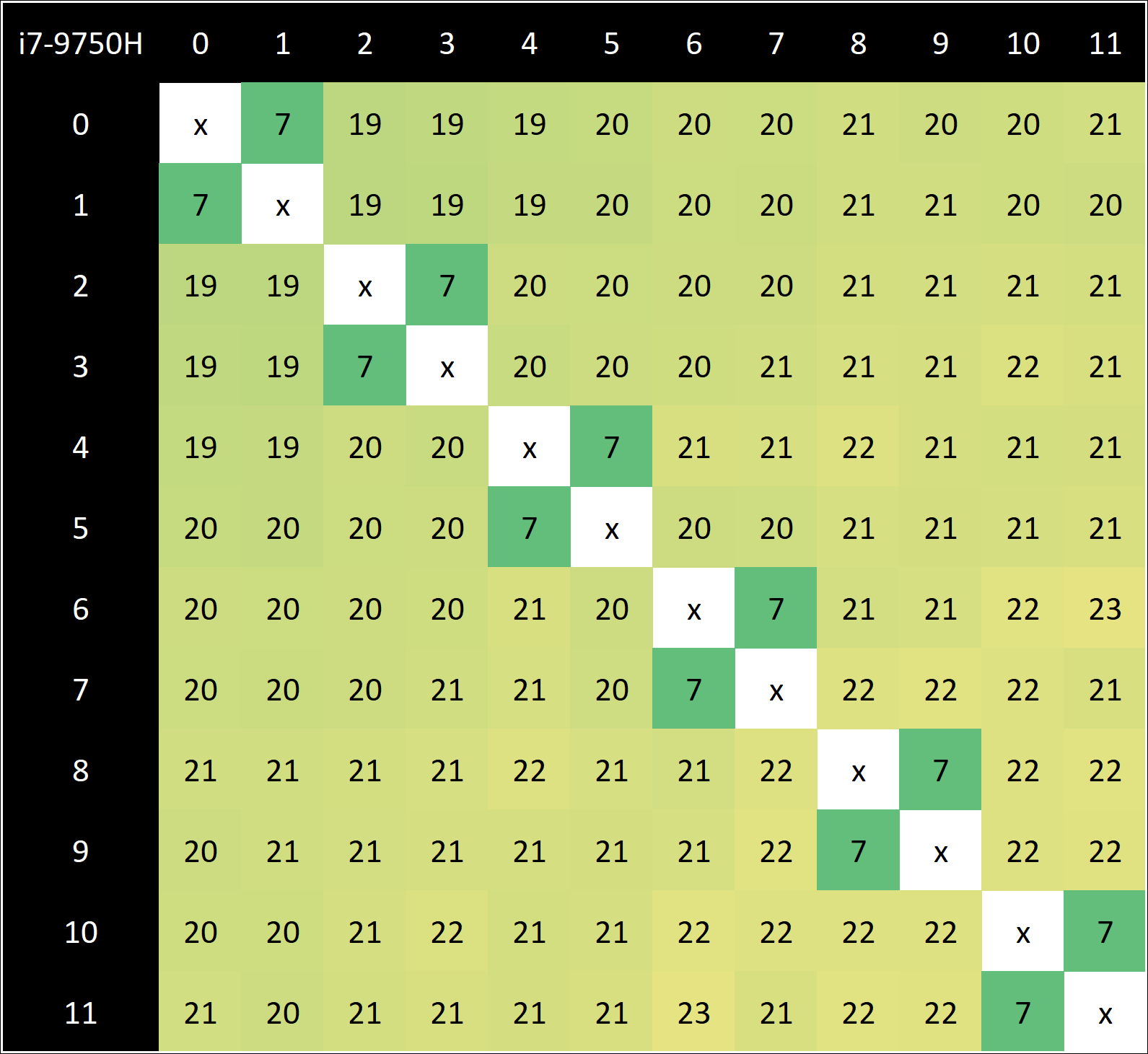
For the Core i7, we see a similar 7 nanosecond latency for a hyperthread, but in order to access any of the other six cores, it takes 19-23 nanoseconds. This is a tiny bit longer than AMD inside a CCX, because the Intel methodology is a ring-based topology, but Intel has the benefit of it being uniform across the whole chip, enabling the performance to be more consistent as the CPU has an effective homogenous latency. Intel’s ring topology is core count dependent, so more cores means a larger ring and a longer latency, but the variability of the ring becomes bigger (and less power efficient) when the ring gets bigger – this is why we saw dual ring designs in high-core-count Xeon chips for pre-Skylake.
Caching
For Renoir, AMD decided to minimize the amount of L3 cache to 1 MB per core, compared to 4 MB per core on the desktop Ryzen variants and 4 MB per core for Threadripper and EPYC. The reduction in the size of the cache does three things: (a) makes the die smaller and easier to manufacture, (b) makes the die use less power when turned on, but (c) causes more cache misses and accesses to main memory, causing a slight performance per clock decrease.
With (c), normally doubling (2x) the size of the cache gives a square root of 2 decrease in cache misses. Therefore going down from 4 MB on the other designs to 1 MB on these designs should imply that there will be twice as many cache misses from L3, and thus twice as many memory accesses. However, because AMD uses a non-inclusive cache policy on the L3 that accepts L2 cache evictions only, there’s actually less scope here for performance loss. Where it might hurt performance most is actually in integrated graphics, however AMD says that as a whole the Zen2+Vega8 Renoir chip has a substantial uplift in performance compared to the Zen+Vega11 Picasso design that went into the Surface Laptop 3.
For our cache latency structure, we got the following results:
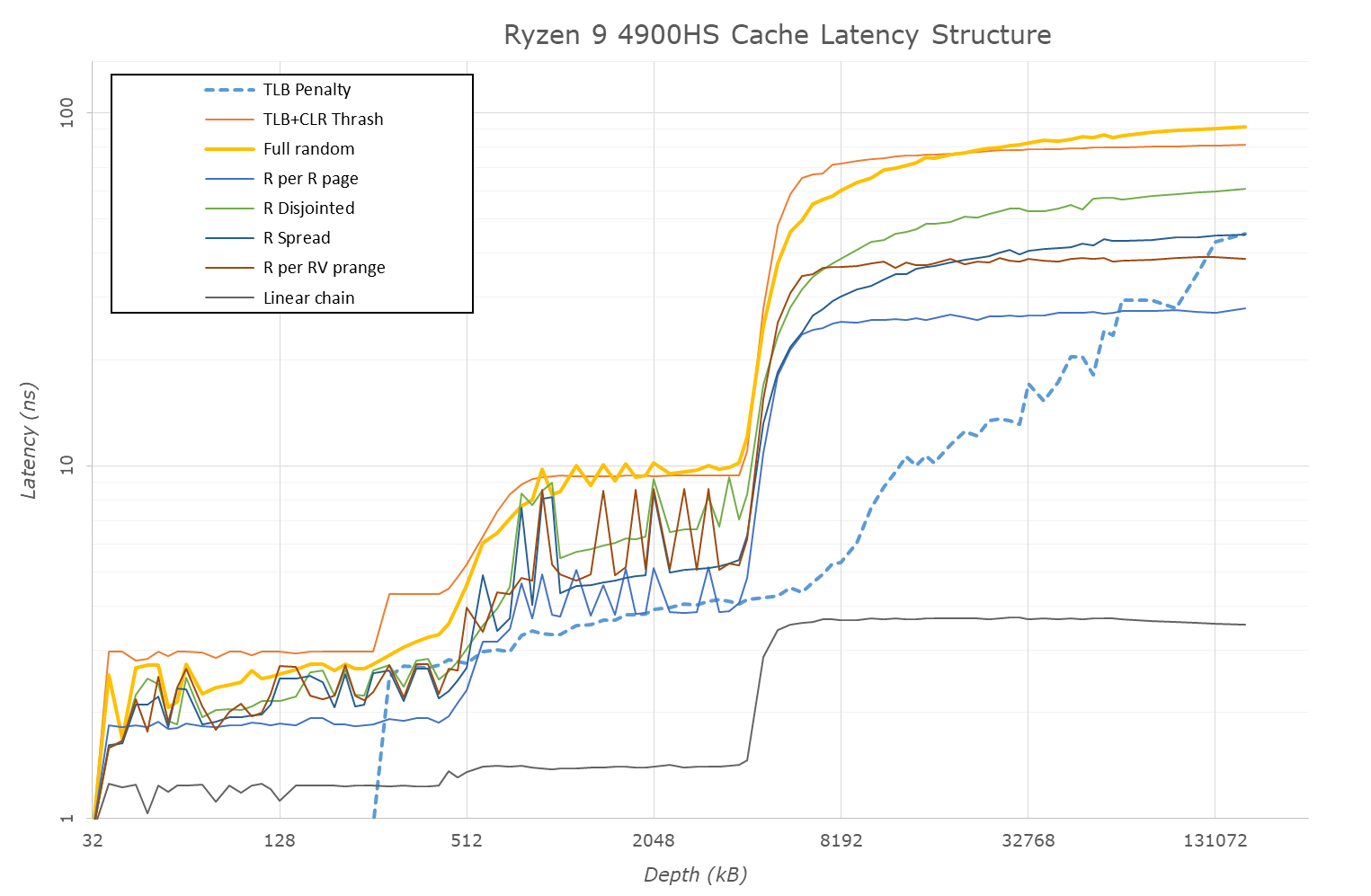
Our results show a worst case scenario with full random access latencies of
- 0.9 nanoseconds for L1 (4 clks) up to 32 KB,
- 3 nanoseconds for L2 (12-13 clks) up to 256 KB,
- 4-5 nanoseconds (18-19 clks) at 256-512 KB (Accesses starting to miss the L1 TLB here)
- 9.3 nanoseconds (39-40 clks) from 1 MB to 4 MB inside the rest of the CCX L3
- 65+ nanoseconds (278+ clks) from 6 MB+ moving into DRAM
It’s important to note that even though the chip has 8 MB of L3 total across the two CCX domains, each core can only access the L3 within its own CCX, and not the L3 of the other CCX domain. So while the chip is correct in saying there is 8 MB of L3 total, no core has access to all the L3. This applies to the desktop and enterprise chips as well (in case it wasn’t explicitly stated before).
Turbo Ramping
One of the key metrics of previous mobile designs is the ability for the core to jump from a low power state to a high power state very quickly, and then back down again. The faster you can do it, the better responsiveness for the user, but it also saves power by not keeping the high power state on for so long. It also helps that the processor ends up with a bunch of instructions to process, it can turbo up before they are finished, otherwise it wastes power doing the turbo for nothing.
For this test, we derive the frequency of a core at a microsecond level with instruction block throughput measurements while the CPU ramps up to its highest turbo state.
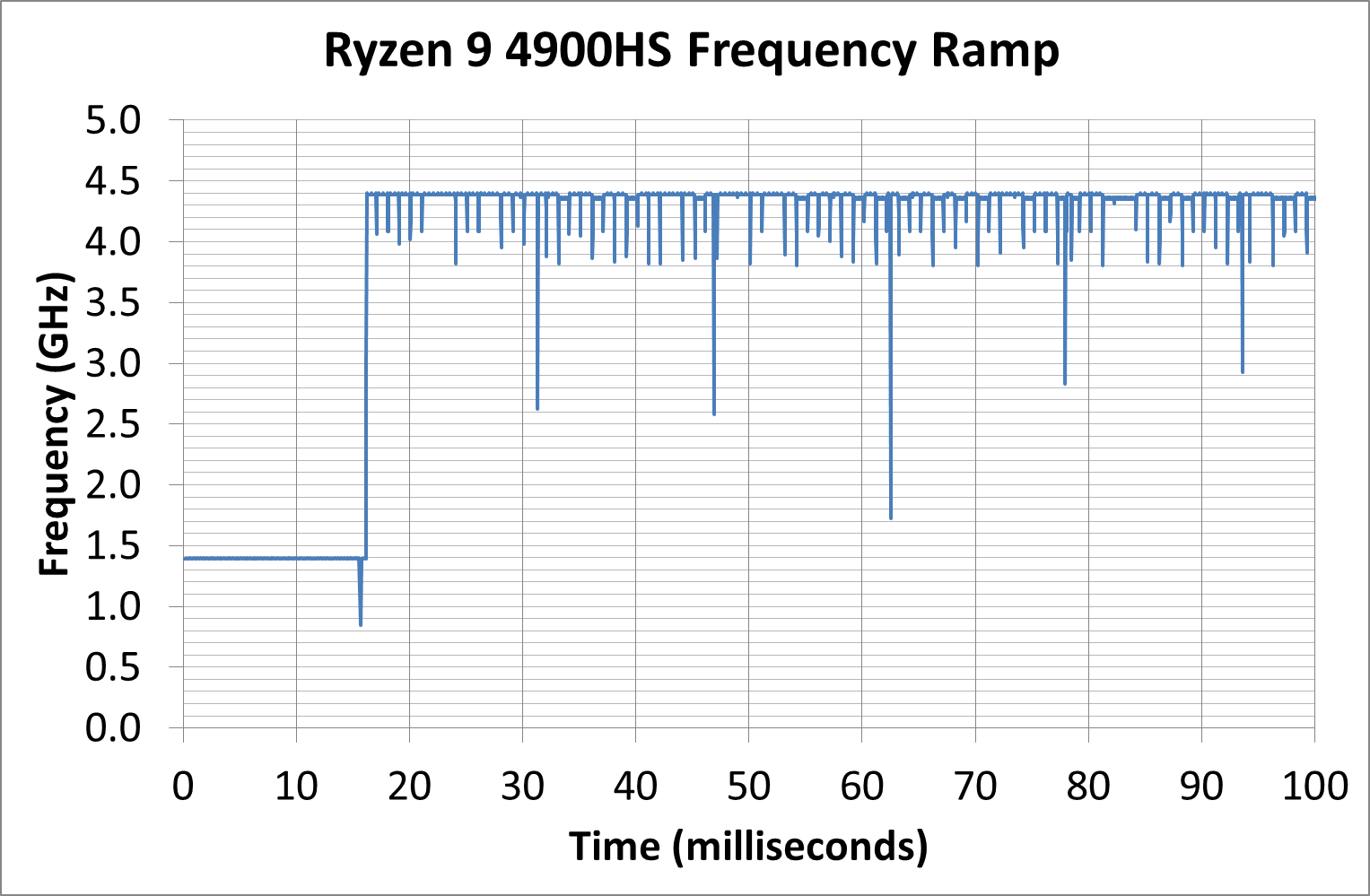
Here our Ryzen 9 4900 HS idles at 1.4 GHz, and within the request to go up to speed, it gets to 4.4 GHz (which is actually +100 MHz above specification) in 16 ms. At 16 ms to get from idle to full frequency, we’re looking at about a frame on a standard 60 Hz monitor, so responsiveness should be very good here.
We can compare this to the Core i7-9750H in the Razer Blade:
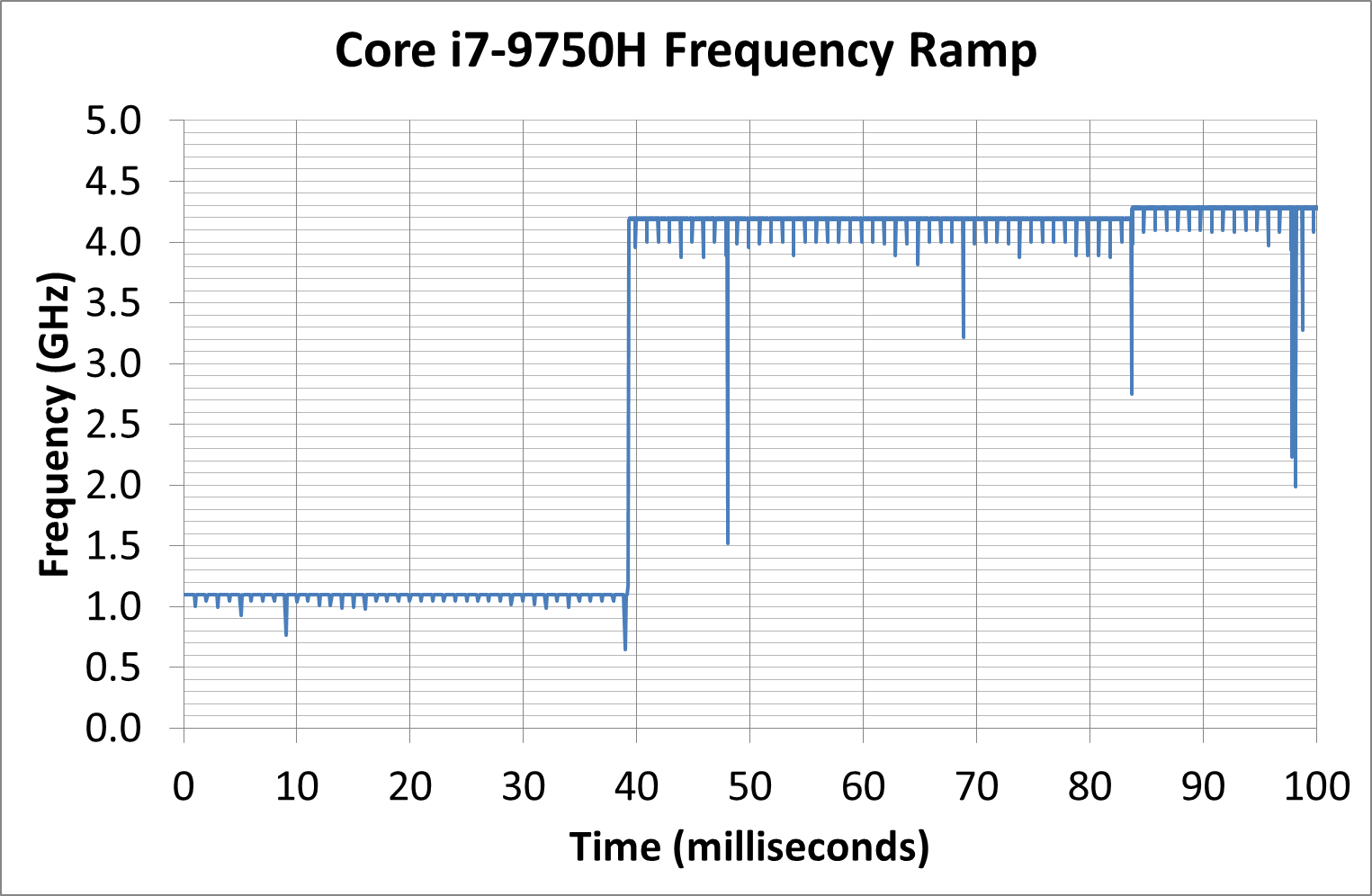
This processor idles a bit lower, at 1.1 GHz, and then gets to 4.2 GHz at around 39 milliseconds. The thing is though, this isn’t the top turbo frequency. Technically this CPU can get to 4.5 GHz, it even says so on the sticker on the laptop, however we see another small bump up to 4.3 GHz at around 83 milliseconds. So either way, it takes 2-4x longer to hit the high turbo for Intel’s 9th Gen (as setup by Razer in the Blade) than it does for AMD’s Ryzen 4000 (as setup by ASUS).








267 Comments
View All Comments
neblogai - Friday, April 10, 2020 - link
Yes, it is probably not too bad performance wise- U-series set to 25W + LPDDR4X. But, I understand, it is in the upper price range, so I'll wait to see the overclocking results of ~200g lighter and ~€200 cheaper Swift 3, which might fit my needs better.twotwotwo - Thursday, April 9, 2020 - link
Similar--I would also love 13-14" + all the CPU + enough battery. Minimal graphics is fine and I can't use a high refresh rate. Wouldn't mind a better-than-1080p screen, but that's icing. And I like the matte screen, user-upgradeability, and good keyboard here. (So, like, move a little towards the MacBook Pro kind of market but not too far.)Think I read they didn't expect anyone to build with a 4900H(S) and no dGPU. If that's how it is, it'd still be cool to see a small laptop that cheaps out on the dGPU/refresh rate but not on everything else, for those of us that aren't hardcore gamers. Maybe an AMD dGPU? Their stuff to shift power budget between CPU and GPU seems neat.
lightningz71 - Thursday, April 9, 2020 - link
I like what you're putting down, but, I want the following:No dGPU
R9-4900H with generous cooling
two SODImm sockets
1 X 2.5 inch SATA bay
1 X NVME M.2 slot
15inch form factor
1440p screen with freesync (High res for productivity, 720p RIS upscaling from the iGPU for gaming)
95watt battery
That would be everything that I need in a laptop. I'm not looking for bleeding edge gaming, but, I do like having a lot of screen pixel area when I need to do something useful.
eva02langley - Sunday, April 12, 2020 - link
Waiting for something similar, however in an slim ultrabook factor.Zingam - Saturday, April 11, 2020 - link
USB4, HDMI 2.1, more PCI lanes, PCI 4.0, AV1 4K encoding, decoding, etc. insignificant stuff...Zingam - Saturday, April 11, 2020 - link
RJ45u600213 - Thursday, April 9, 2020 - link
I almost ordered an ASUS Zephyrus G14 but no webcam so no go.quantumshadow44 - Thursday, April 9, 2020 - link
lack of RJ45 is also no goDahak - Thursday, April 9, 2020 - link
Yep same, I could go without a webcam. But lack of RJ45 is a big no no for me. For home users or mobile pros, its probably fine but as an IT pro, I need ethernet.philehidiot - Thursday, April 9, 2020 - link
I'm no IT pro, I'm a garden variety nerd and I have to say I need at least one laptop in the house with an RJ45. I have two laptops in the house, one being a Macbook Air (2011, now obsolete) which has no RJ45 and it means I have to use the Missus's laptop for any network diagnostics where I need to connect directly to the router. I see RJ45s as kind of like an optical drive for most people. You can get away without one, but they're damned useful to have around. My Macbook will be moving to Linux shortly for the rest of its life and I recently popped an SSD into the Wife's ageing laptop which turned it from unusable to awesome. I expect they'll both need replacing at a similar time and when that time comes, part of the buying decision will be ensuring one of the machines has an RJ45 on it or we buy an adaptor for when it's required.