The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
SPEC - Multi-Threaded Performance - Subscores
We’re starting off with the multi-threaded/process SPEC CPU rate results. As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
We’re focusing our comparisons between the new M128-30, the previous Q80-33, and AMD’s flagship EPYC 7763 and Intel’s new Xeon 8380. The Altra chips are running at 250W TDPs at respectively 128/80 cores, the EPYC at 280W and 64 cores, and the Xeon at 270W for 40 cores. The SMT systems have it enabled, and we’re running peak threads in these subscores.
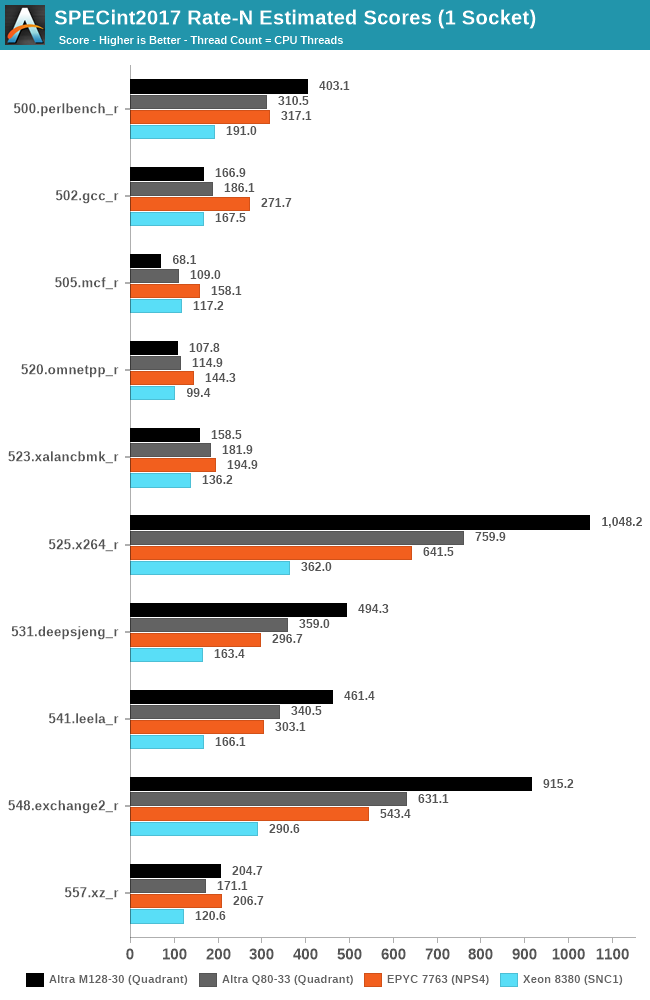
In SPECint2017, we’re seeing two different result-sets for the new Altra Max system – either very large gains, or some more notable performance regressions.
Workloads such as 525.x264_r, 531.deepsjeng_r, 541.leela_r, and 548.exchange2_r, have one large commonality about them, and that is that they’re not very memory bandwidth hungry, and are able to keep most of their working sets within the caches. For the Altra Max, this means that it’s seeing performance increases from 38% to 45% - massive upgrades compared to the already impressive Q80-33.
The 45% increase in 548.exchange2_r is essentially almost perfect linear scaling with the core count and frequencies; although the M128-30 has 60% more cores, it’s also running at 10% lower frequencies, so 45% more theoretical throughput.
523.xlancbmk_r also isn’t very DRAM traffic heavy in traditional systems, however it has a larger working set than the other aforementioned workloads, and the smaller SLC size and increased core count don’t do it favours as it becomes resource contended. The same can be said of 502.gcc_r, which is also slower than the Q80-33.
505.mcf_r is the worst-case scenario, although memory latency sensitive, it also has somewhat higher bandwidth that can saturate a system at higher instance count, and adding cores here, due to the bandwidth curve of the system, has a negative impact on performance as the memory subsystem becomes more and more inefficient. The same workload with only 32 or 64 instances scores 83.71 or 101.82 respectively, much higher than what we’re seeing with 128 cores.
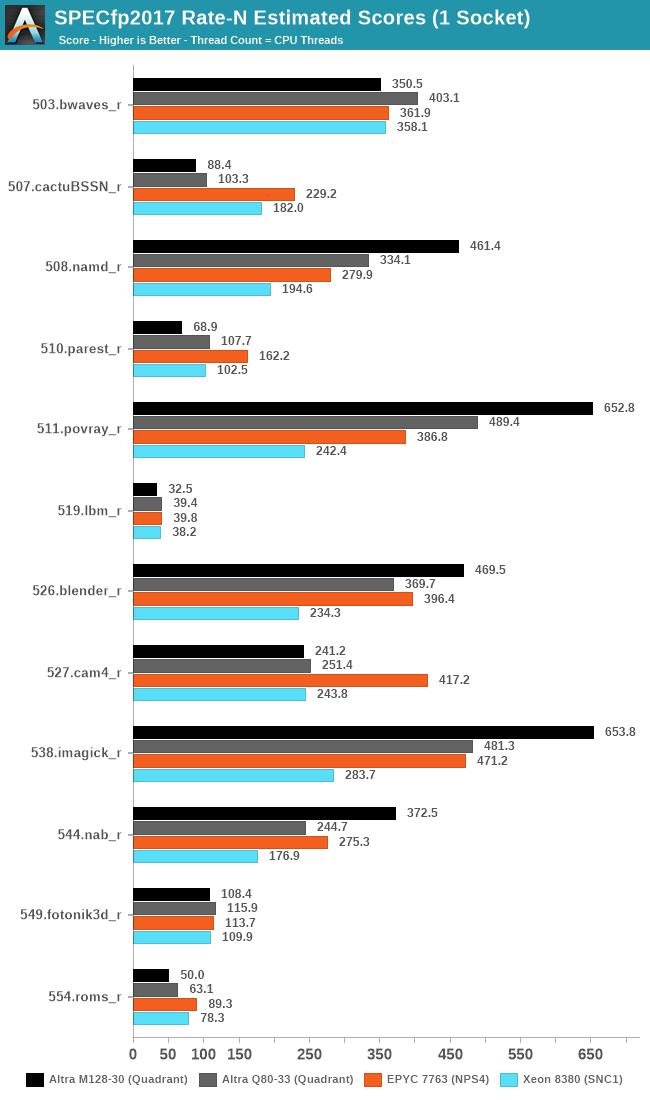
In the FP suite, we’re seeing a same differentiation between the M128-80 and the other systems. In anything that is more stressful on the memory subsystem, the new Mystique chip doesn’t do well at all, and most times regresses over the Q80-33.
In anything that’s simply execution bound, throwing in more execution power at the problem through more cores of course sees massive improvements. In many of these cases, the M128-30 can now claim a rather commanding lead over the competition Milan chip, and leaving even Intel’s new Ice Lake-SP in the dust due to the sheer core count and efficiency advantage.








60 Comments
View All Comments
Wilco1 - Sunday, October 10, 2021 - link
> You need only note the cases where Max significantly underperforms, relative to its 80-core sibling, to see where the cache reduction is likely an issue.There are regressions in 4 of the 10 integer benchmarks - only mcf is significant. However if you look closely, Altra Max still beats/equals the 8380 in 3 out of those 4. Clearly a 40MB L3 is not large enough for these benchmarks, so would you also call that a "major liability"? EPYC beats all by a huge margin in these 4, so clearly 256MB L3 works well, but it's also way too expensive for a monolithic die.
> The reason why there are so many different benchmarks is that you can't just seize on the aggregate numbers to tell the whole story.
No. The aggregate result averages out the extremes and is a better prediction for average performance. For example Altra Max is slower than Altra on gcc_r and far behind EPYC. However in LLVM compilation Altra Max beats Altra by ~20% and is pretty much equal to the 7763. So in real world tests EPYC's huge caches don't help nearly as much as the gcc_r subtest suggests.
mode_13h - Sunday, October 10, 2021 - link
> There are regressions in 4 of the 10 integer benchmarks - only mcf is significant.When you have 45% more core x GHz, *any* regression is significant! By that token, we should also be marking the xz test as underperforming, since it's only a ~20% improvement.
It's also convenient to seize on specint, when it suffers regressions on 7 of the 12 specfp tests.
> Altra Max still beats/equals the 8380 in 3 out of those 4.
> Clearly a 40MB L3 is not large enough for these benchmarks,
> so would you also call that a "major liability"?
This seems like a rather disingenuous point. To say anything about the 8380's cache, we'd need to see a comparison against other Ice Lake CPUs with a different core-to-cache ratio.
> No. The aggregate result averages out the extremes and is a better
> prediction for average performance.
It's a flawed inference to conclude that "the average workload" will match an unweighted average of a set of intentionally disparate workloads.
Furthermore, people less & less buy hardware for "the average workload".
> in LLVM compilation Altra Max beats Altra by ~20% and is pretty much equal to the 7763.
You can't just cherry-pick the best results of each memory configuration. If you're going to deal in aggregates, then you need to aggregate the results per-configuration.
> So in real world tests EPYC's huge caches don't help nearly as much as the gcc_r subtest suggests.
As a matter of fact, the monolithic vs. quadrant results would argue the opposite, in your chosen example of LLVM. Furthermore, what qualifies LLVM compilation as more "real world" than the gcc test?
schujj07 - Monday, October 11, 2021 - link
"The Altra Max wins the more useful critical-jOPS benchmark by over 30%"What are you talking about? In both critical-jOPS & max-jOPS the 2s 7763 is on the top of the chart. We cannot try to extrapolate possible performance on the Altra Max due to "Unfortunately, trading in one issue with another, we ran into other issues on the 2-socket test scenario where the test ran into issues at large thread counts. The 2S Q80-33 figures here only stresses 130 cores, while I wasn’t able at all to get 2S M128-30 figures at reasonable core counts, so I completely omitted results here."
Per-core performance matters a lot. There are A LOT of programs, especially databases, that are licensed on a per core metric. This means I need 8 cores of Altra Max to equal the performance I get from an Epyc 4c that will kill my licensing cost. Those added cores could easily double the license cost and those license are often times MUCH more expensive than the server itself. It is obvious you don't work in industry as this is common knowledge.
Overall the Altra Max is interesting but nothing more than that. It won't be a player in industry until the per core performance is at least double what it currently is and there is enterprise software able to take advantage of it. Basically Altra Max is like IBM Power and that is niche at best.
Wilco1 - Tuesday, October 12, 2021 - link
Altra Max is still at the top for 1S critical-jOPS - that's not invalidated by missing 2S results.If you worked in the industry, you would know that per-core licenses have a multiplier based on CPU type to level out performance differences. In cases where per-core performance really matters and you completely disable SMT (for example for high-frequency trading), you would not consider these many-core servers at all but get 8 or 16 core CPUs with significantly higher bandwidth, cache and power per core.
It seems you misunderstand the target market completely. You probably also call Graviton 2 a niche eventhough it is already a significant percentage of AWS and growing fast. And that with just 64 cores and far lower per-core performance than Altra...
schujj07 - Tuesday, October 12, 2021 - link
How about we do some math instead. Compared to the 1S 80 core, the 1S Max gets 42% better performance, THP disabled, or 30% better performance THP enabled for 60% more cores in your beloved critical-jOPS. Compare that to the Epyc 7763 which gets 105% better THP disabled and 102% THP enabled. Even the older 80C only adds 62% despite doubling its cores. Based on that alone best case scenario is the 2S Altra Max ties the Epyc 2S in critical-jOPS. Sure it is beating the 1S 7763 but it barely beats the 2S 7443 a 24c/48t CPU.I do work in industry as a VMware Admin. Unless you are running Oracle, most of these will be run on systems up to 32c/64t to max out your VMware license. If you have specific needs you can get the higher frequency parts that also are up to 32c AMD or 28c Intel. The difference in costs for Windows DataCenter for the core additional core licenses is saved by reducing the number of physical hosts. What software has "per-core licenses have a multiplier based on CPU type to level out performance differences?" That sounds like they are going to charge your X for Xeon Scalable Gen 1 but Y for Gen 2 and Z for AMD. That doesn't happen. MS SQL Server charges per core with a base license of 4 cores. Now if I need 8 cores on the Altra Max to equal the performance of an Epyc at 4 cores I have doubled my license cost.
Overall ARM with under 10% total market share IS a niche player. They need to get to the same per core performance & have software available for it to be an actual alternative. Until that happens companies will play around with it but nothing serious in the data center environment.
mode_13h - Tuesday, October 12, 2021 - link
> You probably also call Graviton 2 a nicheDon't put words in people's mouths. If you want to know whether @schujj07 considers it a niche, you can certainly ask.
Kangal - Thursday, October 7, 2021 - link
This is basically a 3GHz Cortex-A76 (Neoverse N1), running in a 128-core tandem, and built with a more efficient/expensive Monolithic Socket based on TSMC's 7nm node. Sounds neat.I enjoyed seeing the older generation which was basically a 2GHz Cortex-A73, running in 64-core tandem, and built on TSMC's 16nm node. Was quiet value-for-money, at least in its time.
Seems like this new version is giving Intel's Core-i, decent competition in the single-threaded work. Since Intel is having some issues with their own node, and can't clock too high. Whilst AMD has a clear advantage here. When it comes to total/multi-threaded performance, ARM wins through sheer grunt of all those extra cores. Overall, it is a competitive choice for today and the next few years.
What will be interesting is when they bump it up to the Cortex-A78 (Neoverse V1) and use something like TSMC's 5nm node which should bring it to full-parity on the single-threaded performance against Intel. Or to the next best thing, ARM v9, using the Cortex-X2 (Neoverse N2) on the same TSMC 5nm node. But I share my previous concerns that the first-generation of (USA) ARM v9 is going to be quiet disappointing, but I'm optimistic about the (European) second-generation. I think then we should see more tangible benefits, when combined with the TSMC 3nm node, which should bring it on parity to AMD's cores on the single-threaded characteristic. Exciting times ahead. And yes, I know I am over-simplifying things here.
SarahKerrigan - Thursday, October 7, 2021 - link
Previous Ampere parts weren't 64-core, 2GHz, or Cortex-A73. They were a custom (and bad) core, 32 per socket, at 3.3GHz.Neoverse V1 is based on the Cortex-X1, not the Cortex-A78. Neoverse N2 is based on the Cortex-A710, not the Cortex-X2.
Kangal - Friday, October 8, 2021 - link
Sorry, by "older generation" I was talking about the Amazon Graviton one, not the previous Ampere Version.The proper upgrade from the Cortex-A76 is the Cortex-A78.
The Cortex-A78 is the base micro-architecture, with the Cortex-X1 being a slightly modified derivative of it, and the Neoverse-V1 is a further slightly modified version of that. That's why I worded it in that way. Whilst ARM claims a divergence between the Cortex-A710, Cortex-X2, and Neoverse-N2... I think we will end up seeing them much more closer in-common than different.
SarahKerrigan - Friday, October 8, 2021 - link
The Graviton1 was 16 Cortex-A72 at 2.3GHz.