The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
SPEC - Multi-Threaded Performance - Subscores
We’re starting off with the multi-threaded/process SPEC CPU rate results. As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
We’re focusing our comparisons between the new M128-30, the previous Q80-33, and AMD’s flagship EPYC 7763 and Intel’s new Xeon 8380. The Altra chips are running at 250W TDPs at respectively 128/80 cores, the EPYC at 280W and 64 cores, and the Xeon at 270W for 40 cores. The SMT systems have it enabled, and we’re running peak threads in these subscores.
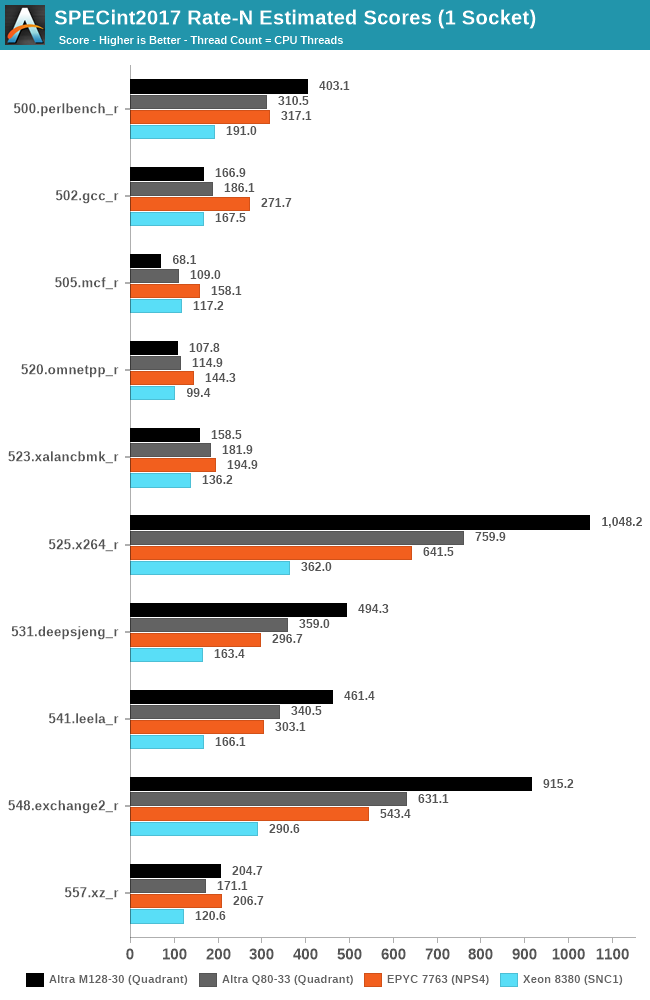
In SPECint2017, we’re seeing two different result-sets for the new Altra Max system – either very large gains, or some more notable performance regressions.
Workloads such as 525.x264_r, 531.deepsjeng_r, 541.leela_r, and 548.exchange2_r, have one large commonality about them, and that is that they’re not very memory bandwidth hungry, and are able to keep most of their working sets within the caches. For the Altra Max, this means that it’s seeing performance increases from 38% to 45% - massive upgrades compared to the already impressive Q80-33.
The 45% increase in 548.exchange2_r is essentially almost perfect linear scaling with the core count and frequencies; although the M128-30 has 60% more cores, it’s also running at 10% lower frequencies, so 45% more theoretical throughput.
523.xlancbmk_r also isn’t very DRAM traffic heavy in traditional systems, however it has a larger working set than the other aforementioned workloads, and the smaller SLC size and increased core count don’t do it favours as it becomes resource contended. The same can be said of 502.gcc_r, which is also slower than the Q80-33.
505.mcf_r is the worst-case scenario, although memory latency sensitive, it also has somewhat higher bandwidth that can saturate a system at higher instance count, and adding cores here, due to the bandwidth curve of the system, has a negative impact on performance as the memory subsystem becomes more and more inefficient. The same workload with only 32 or 64 instances scores 83.71 or 101.82 respectively, much higher than what we’re seeing with 128 cores.
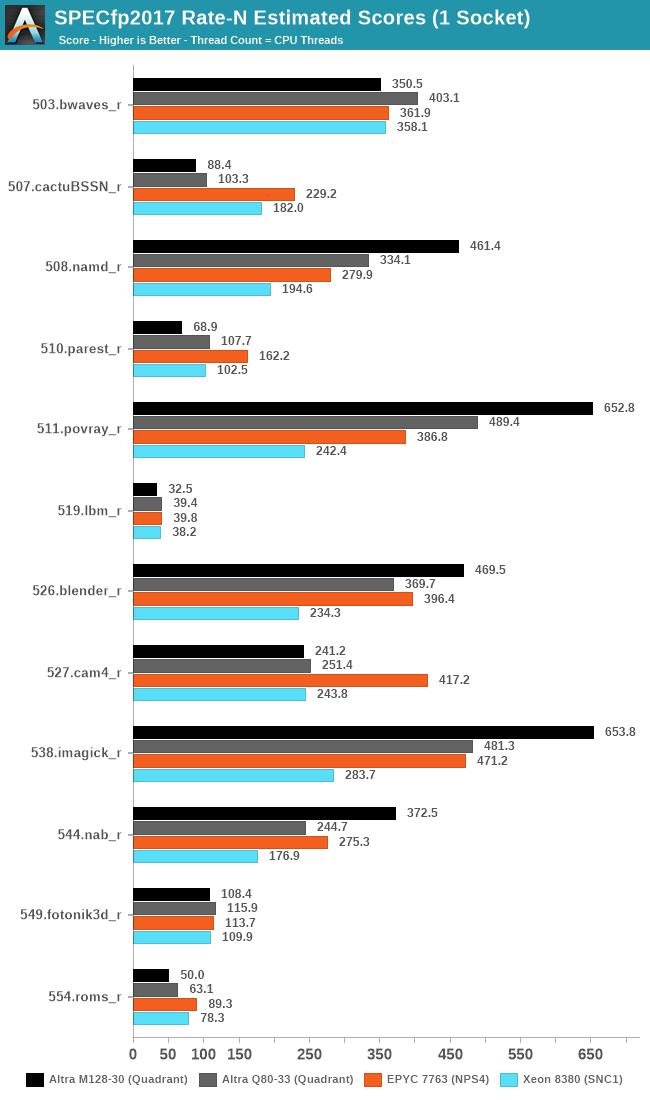
In the FP suite, we’re seeing a same differentiation between the M128-80 and the other systems. In anything that is more stressful on the memory subsystem, the new Mystique chip doesn’t do well at all, and most times regresses over the Q80-33.
In anything that’s simply execution bound, throwing in more execution power at the problem through more cores of course sees massive improvements. In many of these cases, the M128-30 can now claim a rather commanding lead over the competition Milan chip, and leaving even Intel’s new Ice Lake-SP in the dust due to the sheer core count and efficiency advantage.








60 Comments
View All Comments
dullard - Thursday, October 7, 2021 - link
Far too many people mistakenly think it is AMD vs Intel. In reality it is ARM vs (AMD + Intel together).TheinsanegamerN - Thursday, October 7, 2021 - link
In reality it's AMD VS INTEL, with ARM the red headed stepchild with 3 extra chromosomes drooling in the corner. x86 still commands 99% of the server market.DougMcC - Thursday, October 7, 2021 - link
And the reason is price/performance. These chips are pricey for what they deliver, and it shows in amazon instance costs. We looked at moving to graviton 2 instances in aws and even with the in-house pricing advantage there we would be losing 55+% performance for <25% price advantage.eastcoast_pete - Thursday, October 7, 2021 - link
Was/is it really that bad? Wow! I thought AWS is making a value play for their gravitons, your example suggests that isn't working so great.mode_13h - Thursday, October 7, 2021 - link
Could be that demand is simply outstripping their supply. Amazon isn't immune from chip shortages either, you know?DougMcC - Thursday, October 7, 2021 - link
It was for us. Could be that there are workload issues specific to us, though as a pretty basic j2ee app it's somewhat hard for me to imagine that we are unique.lightningz71 - Friday, October 8, 2021 - link
It is VERY workload dependent.lemurbutton - Friday, October 8, 2021 - link
Graviton2 is now 50% of all new instances at AWS.DougMcC - Friday, October 8, 2021 - link
Not super surprising. Even with the massive loss of performance, it's still cheaper. If you don't need performance, why wouldn't you choose the cheapest thing?Wilco1 - Friday, October 8, 2021 - link
In most cases Graviton is not only cheaper but also significantly faster. It's easy to find various examples:https://docs.keydb.dev/blog/2020/03/02/blog-post/
https://about.gitlab.com/blog/2021/08/05/achieving...
https://yegorshytikov.medium.com/aws-graviton-2-ar...
https://www.instana.com/blog/best-practices-for-an...