Hot Chips 2023: Intel Details More on Granite Rapids and Sierra Forest Xeons
by Ryan Smith on August 28, 2023 5:45 PM EST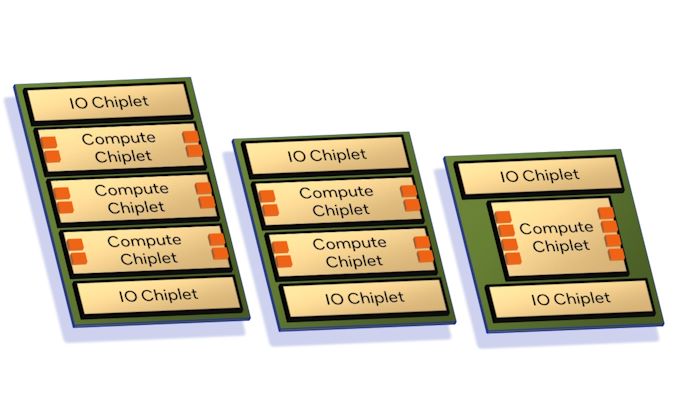
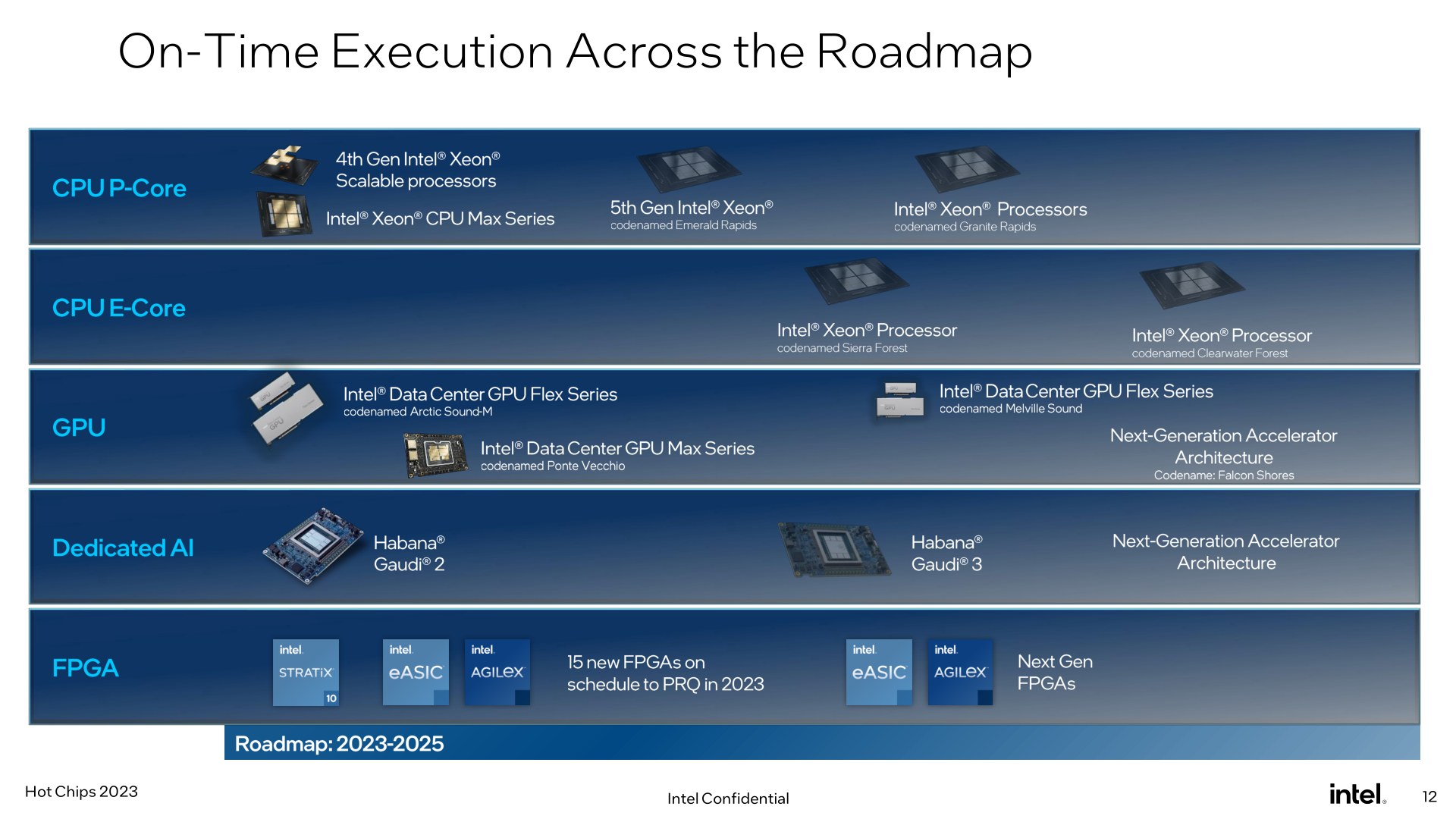
With the annual Hot Chips conference taking place this week, many of the industry’s biggest chip design firms are at the show, talking about their latest and/or upcoming wares. For Intel, it’s a case of the latter, as the company is at Hot Chips to talk about its next generation of Xeon processors, Granite Rapids and Sierra Forest, which are set to launch in 2024. Intel has previously revealed this processors on its data center roadmap – most recently updating it in March of this year – and for Hot Chips the company is offering a bit more in the way of technical details for the chips and their shared platform.
While there’s no such thing as an “unimportant” generation for Intel’s Xeon processors, Granite Rapids and Sierra Forest promise to be one of Intel’s most important updated to the Xeon Scalable hardware ecosystem yet, thanks to the introduction of area-efficient E-cores. Already a mainstay on Intel’s consumer processors since 12th generation Core (Alder Lake), with the upcoming next generation Xeon Scalable platform will finally bring E-cores over to Intel’s server platform. Though unlike consumer parts where both core types are mixed in a single chip, Intel is going for a purely homogenous strategy, giving us the all P-core Granite Rapids, and the all E-core Sierra Forest.
As Intel’s first E-core Xeon Scalable chip for data center use, Sierra Forest is arguably the most important of the two chips. Fittingly, it’s Intel’s lead vehicle for their EUV-based Intel 3 process node, and it’s the first Xeon to come out. According to the company, it remains on track for a H1’2024 release. Meanwhile Granite Rapids will be “shortly” behind that, on the same Intel 3 process node.
As Intel’s slated to deliver two rather different Xeons in a single generation, a big element of the next generation Xeon Scalable platform is that both processors will share the same platform. This means the same socket(s), the same memory, the same chiplet-based design philosophy, the same firmware, etc. While there are still differences, particularly when it comes to AVX-512 support, Intel is trying to make these chips as interchangeable as possible.
As announced by Intel back in 2022, both Granite and Sierra are chiplet-based designs, relying on a mix of compute and I/O chiplets that are stitched together using Intel’s active EMIB bridge technology. While this is not Intel’s first dance with chiplets in the Xeon space (XCC Sapphire Rapids takes that honor), this is a distinct evolution of the chiplet design by using distinct compute/IO chiplets instead of stitching together otherwise “complete” Xeon chiplets. Among other things, this means that Granite and Sierra can share the common I/O chiplet (built on the Intel 7 process), and from a manufacturing standpoint, whether a Xeon is Granite or Sierra is “merely” a matter of which type of compute chiplet is placed down.
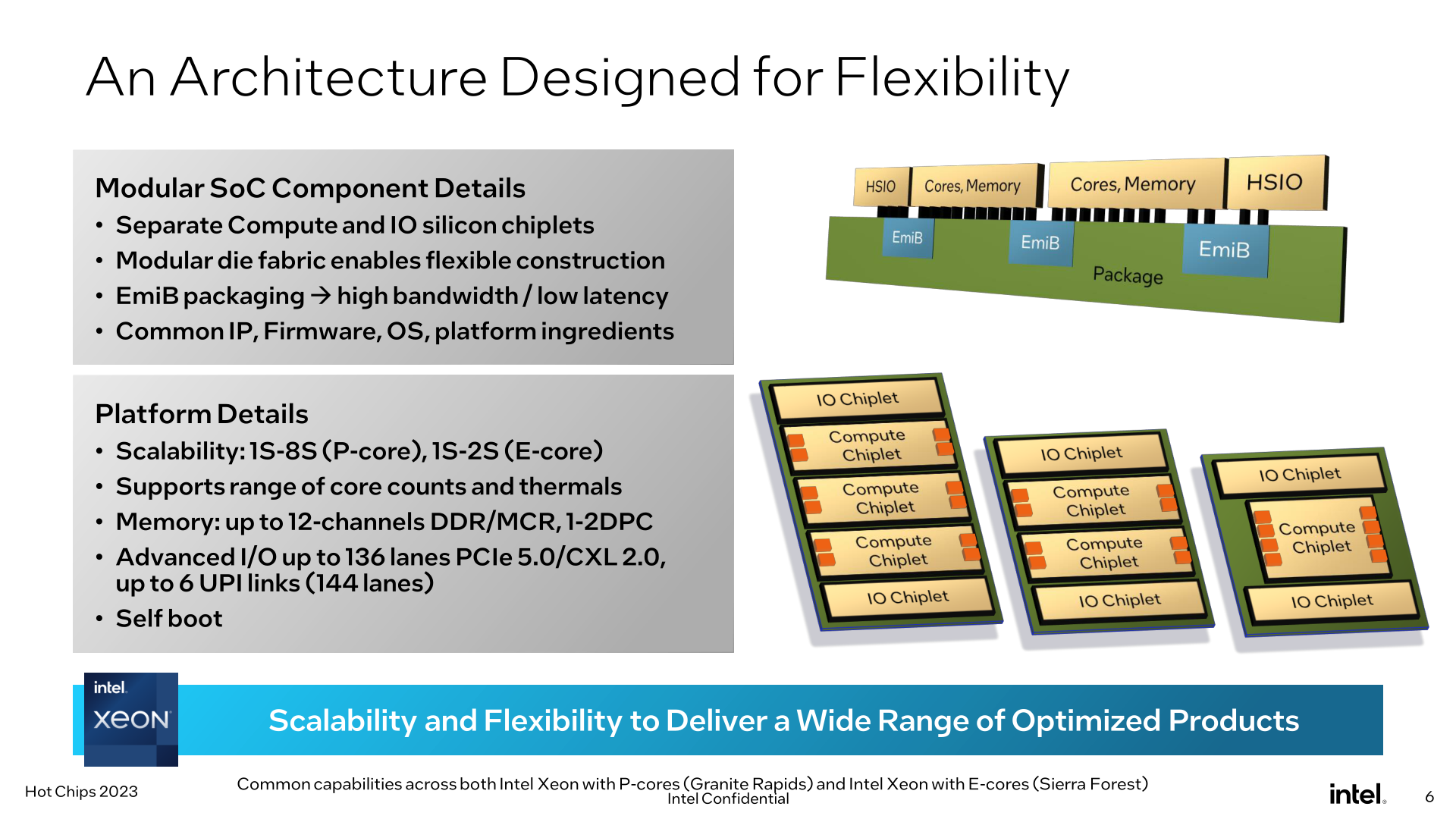
Notably here, Intel is confirming for the first time that the next gen Xeon Scalable platform is getting self-booting capabilities, making it a true SoC. With Intel placing all of the necessary I/O features needed for operation within the I/O chiplets, an external chipset (or FPGA) is not needed to operate these processors. This brings Intel’s Xeon lineup closer in functionality to AMD’s EPYC lineup, which has been similarly self-booting for a while now.
Altogether, the next gen Xeon Scalable platform will support up to 12 memory channels, scaling with the number and capabilities of the compute dies present. As previously revealed by Intel, this platform will be the first to support the new Multiplexer Combined Ranks (MCR) DIMM, which essentially gangs up two sets/ranks of memory chips in order to double the effective bandwidth to and from the DIMM. With the combination of higher memory bus speeds and more memory channels overall, Intel says the platform can offer 2.8x as much bandwidth as current Sapphire Rapids Xeons.
As for I/O, a max configuration Xeon will be able to offer up to 136 lanes general I/O, as well as up to 6 UPI links (144 lanes in total) for multi-socket connectivity. For I/O, the platform supports PCIe 5.0 (why no PCIe 6.0? We were told the timing didn’t work out), as well as the newer CXL 2.0 standard. As is traditionally the case for Intel’s big-core Xeons, Granite Rapids chips will be able to scale up to 8 sockets altogether. Sierra Forest, on the other hand, will only be able to scale up to 2 sockets, owing to the number of CPU cores in play as well as the different use cases Intel is expecting of their customers.
Along with details on the shared platform, Intel is also offering for the first time a high-level overview of the architectures used for the E-cores and the P-cores. As has been the case for many generations of Xeons now, Intel is leveraging the same basic CPU architecture that goes into their consumer parts. So Granite and Sierra can be thought of as a deconstructed Meteor Lake processor, with Granite getting the Redwood Cove P-cores, while Sierra gets the Crestmont E-Cores.

As noted before, this is Intel’s first foray into offering E-cores for the Xeon market. Which for Intel, has meant tuning their E-core design for data center workloads, as opposed to the consumer-centric workloads that defined the previous generation E-core design.
While not a deep-dive on the architecture itself, Intel is revealing that Crestmont is offering a 6-wide instruction decode pathway as well as an 8-wide retirement backend. While not as beefy as Intel’s P-cores, the E-core is not by any means a lightweight core, and Intel’s design decisions reflect this. Still, it is designed to be far more efficient both in terms of die space and energy consumption than the P cores that will go into Granite.
The L1 instruction cache (I-cache) for Crestmont will be 64KB, the same size as on Gracemont. Meanwhile, new to the E-core lineup with Crestmont, the cores can either be packaged into 2 or 4 core clusters, unlike Gracemont today, which is only available as a 4 core cluster. This is essentially how Intel is going to adjust the ratio of L2 cache to CPU cores; with 4MB of shared L2 regardless of the configuration, a 2-core cluster affords each core twice as much L2 per core as they’d otherwise get. This essentially gives Intel another knob to adjust for chip performance; customers who need a slightly higher performing Sierra design (rather than just maxing out the number of CPU cores) can instead get fewer cores with the higher performance that comes from the effectively larger L2 cache.
And finally for Sierra/Crestmont, the chip will offer as close to instruction parity with Granite Rapids as possible. This means BF16 data type support, as well as support for various instruction sets such as AVX-IFMA and AVX-DOT-PROD-INT8. The only thing you won’t find here, besides an AMX matrix engine, is support for AVX-512; Intel’s ultra-wide vector format is not a part of Crestmont’s feature set. Ultimately, AVX10 will help to take care of this problem, but for now this is as close as Intel can get to parity between the two processors.
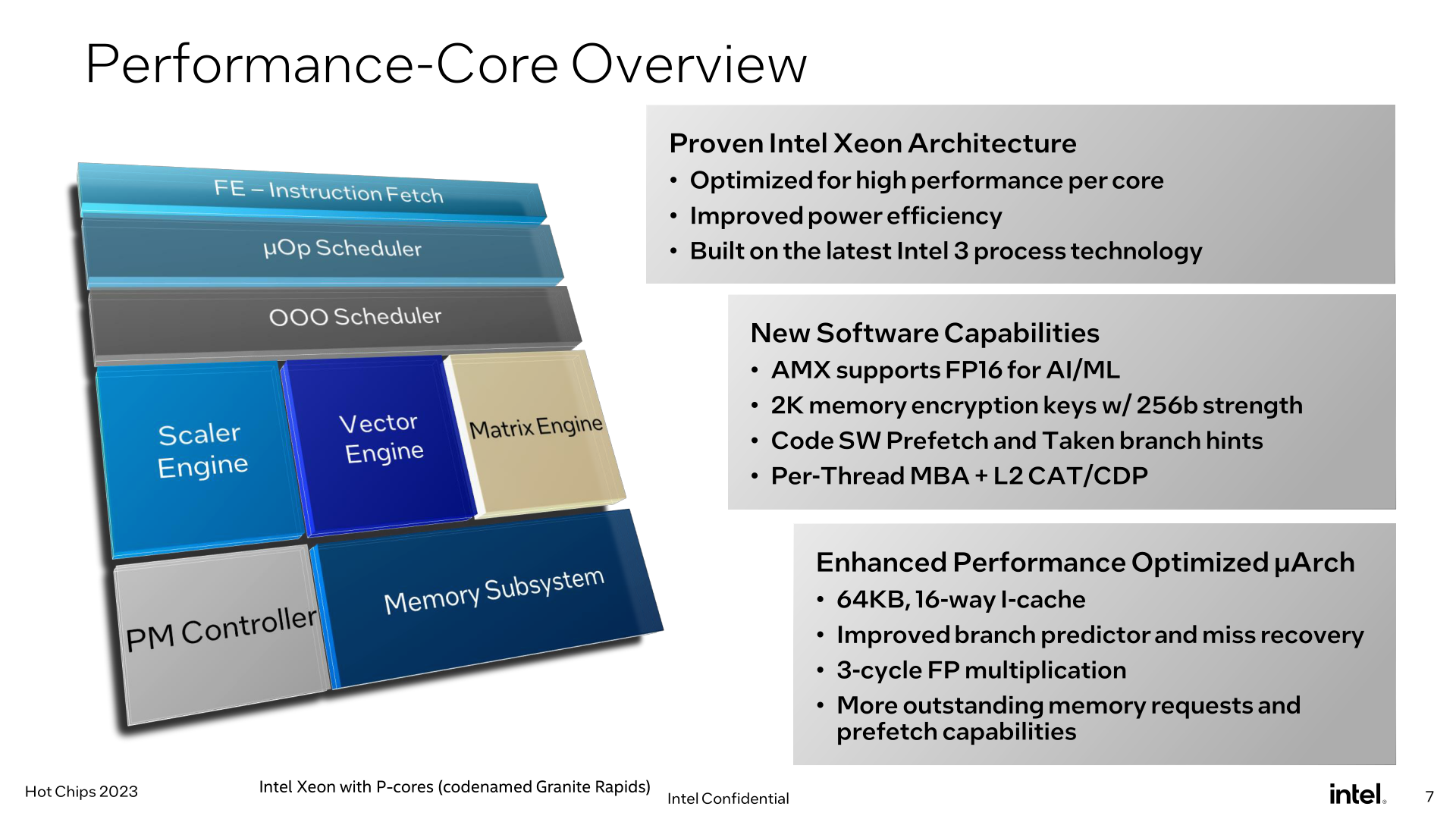
Meanwhile, for Granite Rapids we have the Redwood Cove P-core. The traditional heart of a Xeon processor, Redwood/Granite aren’t as big of a change for Intel as Sierra Forest is. But that doesn’t mean they’re sitting idly by.
In terms of microarchitecture, Redwood Cove is getting the same 64KB I-cache as we saw on Crestmont, which unlike the E-cores, is 2x the capacity of its predecessor. It’s rare for Intel to touch I-cache capacity (due to balancing hit rates with latency), so this is a notable change and it will be interesting to see the ramifications once Intel talks more about architecture.
But most notably here, Intel has managed to further shave down the latency of floating-point multiplication, bringing it from 4/5 cycles down to just 3 cycles. Fundamental instruction latency improvements like these are rare, so they’re always welcome to see.
Otherwise, the remaining highlights of the Redwood Cove microarchitecture are branch prediction and prefetching, which are typical optimization targets for Intel. Anything they can do to improve branch prediction (and reduce the cost of rare misses) tends to pay relatively big dividends in terms of performance.
More applicable to the Xeon family in particular, the AMX matrix engine for Redwood Cove is gaining FP16 support. FP16 isn’t as quite as heavily used as the already-supported BF16 and INT8, but it’s an improvement to AMX’s flexibility overall.
Memory encryption support is also being improved. Granite Rapids’ flavor of Redwood Cove will support 2048, 256-bit memory keys, up from 128 keys on Sapphire Rapids. Cache Allocation Technology (CAT) and Code and Data Prioritization (CDP) functionality are also getting some enhancements here, with Intel extending them to be able to control what goes in to the L2 cache, as opposed to just the LLC/L3 cache in previous implementations.
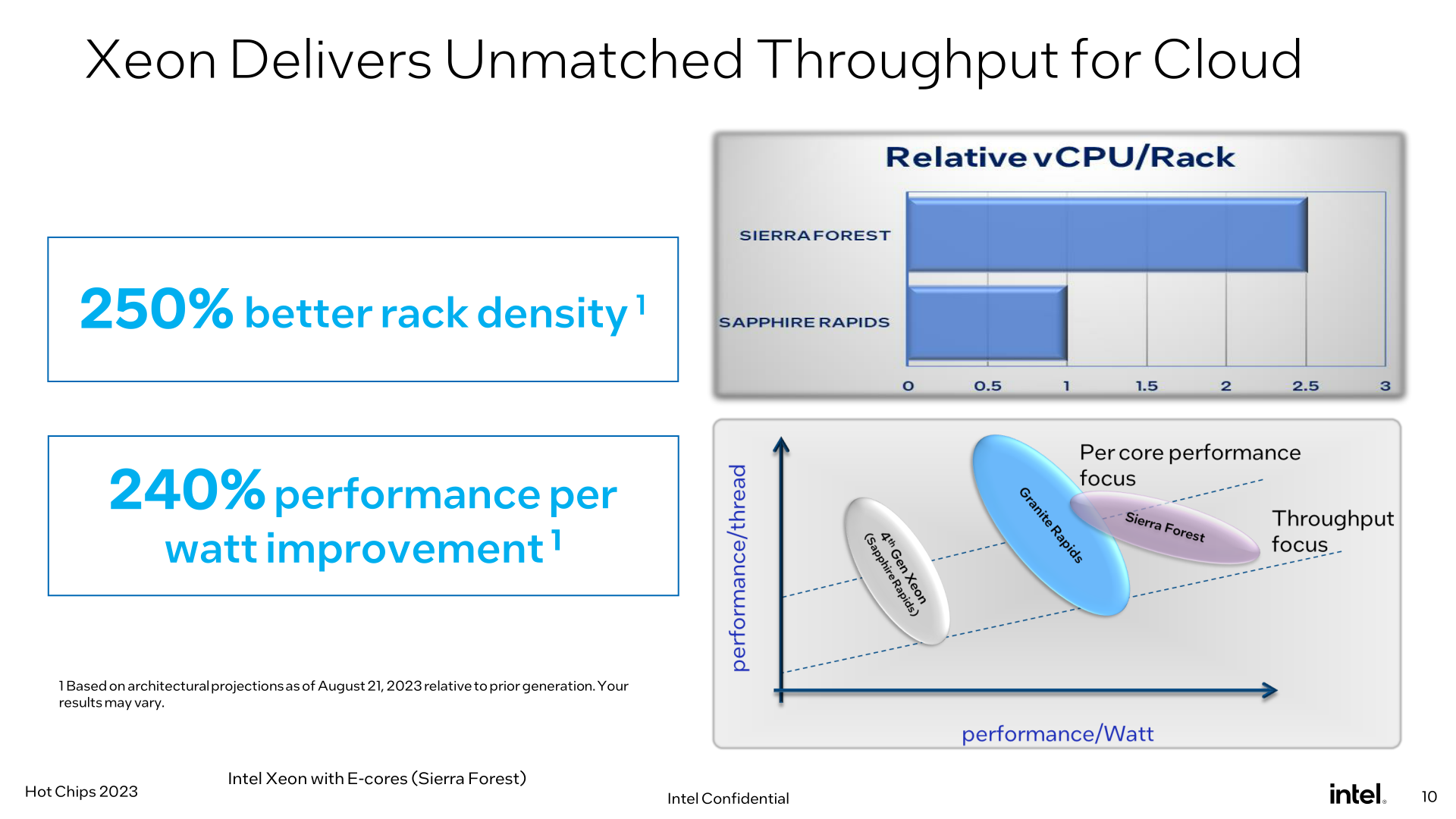
Ultimately, it goes without saying that Intel believes they’re well-positioned for 2024 and beyond with their upcoming Xeons. By improving performance on the top-end P-core Xeons, while introducing E-core Xeons for customers who just need lots of lighter CPU cores, Intel believes they can address the complete market with two CPU core types sharing a single common platform.
While it’s still too early to talk about individual SKUs for Granite Rapids and Sierra Forest, Intel has told us that core counts overall are going up. Granite Rapids parts will offer more CPU cores than Sapphire Rapids (up from 60 for SPR XCC), and, of course, at 144 cores Sierra will offer even more than that. Notably, however, Intel won’t be segmenting the two CPU lines by core counts – Sierra Forest will be available in smaller core counts as well (unlike AMD’s EPYC Zen4c Bergamo chips). This reflects the different performance capabilities of the P and E cores, and, no doubt, Intel looking to fully embrace the scalability that comes from using chiplets.
And while Sierra Forest will already go to 144 CPU cores, Intel also made an interesting comment in our pre-briefing that they could have gone higher with core counts for their first E-core Xeon Scalable processor. But the company decided to prioritize per-core performance a bit more, resulting in the chips and core counts we’ll be seeing next year.

Above all else – and, perhaps, letting marketing take the wheel a little too long here for Hot Chips – Intel is hammering home the fact that their next-generation Xeon processors remain on-track for their 2024 launch. It goes without saying that Intel is just now recovering from the massive delays in Sapphire Rapids (and knock-on effect to Emerald Rapids), so the company is keen to assure customers that Granite Rapids and Sierra Forest is where Intel’s timing gets back on track. Between previous Xeon delays and taking so long to bring to market an E-core Xeon Scalable chip, Intel hasn’t dominated in the data center market like it once did, so Granite Rapids and Sierra Forest are going to mark an important inflection point for Intel’s data center offerings going forward.














19 Comments
View All Comments
GeoffreyA - Monday, September 4, 2023 - link
We may have to instantiate a Reality Change to erase this information...Notmyusualid - Saturday, September 9, 2023 - link
To be pendantic, 2566.https://thaiguider.com/what-year-is-it-in-thailand...
:)
duploxxx - Tuesday, August 29, 2023 - link
So after many many years Intel is cloning AMD, history repeated itself...First EPYC had it flaws, 3rd generation (Genoa) was the first to have all things straight (mainly IO wise) lets see how much Intel copied over from the flaws... THey don't really have a track record in the last decade of getting things right from the start.
Interesting to see that Siera comes first in H1 and Granite short after, so that is for sure H2 else they would have mentioned H1... and a very late H1 release and a possible paper launch means Q3 actual systems to buy and Granite in Q4... so far the on-track. Which means all of these products will be against full AMD Zen5.
No word on Granite about real core count besides higher, but Genoa already has 96 which is 50% more than Sapphire.
Sierra has 144 mentioned, Bergamo has 128 already today and has rumoured to double in Zen5...
No word on HT on Granite
Intel stating Granite and Siera the next big leap, ehhh is that the same marketing team? Sapphire Rappids was going to be the next big leap from Cascade-lake and ice-lake and we all were advised to wait (and again wait) for it.... today Intel DC sales push a sapphire rapids refresh next to come, which shows that all these announcements are far far away.
Marketing and CEO (Patje) is all over the place these days stating how well Intel will be in the future, it shows how desperate they are. It is visible in sales, it is visible in benchmarks (unless you believe Intel marketing)
nandnandnand - Tuesday, August 29, 2023 - link
It is interesting that it's apparently using a tweaked version of the E-core (Sierra Glen) that diverges from the consumer version (Crestmont).Maybe 144c/144t Sierra Forest could fare better than expected against 128c/256t Bergamo.
jjjag - Tuesday, August 29, 2023 - link
Not sure what you think Intel is cloning. This architecture is very different than what is shown of the Zen DC CPUs. The cache and memory architecture is completely different here. Intel has small I/O die with apparently just I/O, and the DDR interface appears to be on the cpu chiplets, as does the cache. AMD has a large central I/O with both DDR and cache and much smaller CPU chiplets. Unless you mean using chiplets altogether? AMD was certainly not the first to go away from monolithic and even Intel Sapphire Rapids uses a 4-chiplet package. We know that Sapphire design started MANY years ago and it's late due to execution. So the entire industry realized giant monlithic server chips were not feasible probably 10 years ago. But you are giving AMD all the credit?DannyH246 - Tuesday, August 29, 2023 - link
Imitation is the highest form of flattery! All Intel have done over the last 20years is copy AMD, now they’re doing it again. Lol.jchang6 - Tuesday, August 29, 2023 - link
the Intel P-cores are designed to 5-6GHz operation, which is possible in the desktop K SKU's. They are limited to mid-3 GHz in the high core count data center processors. OK, sure, we would rather have 60+ cores at 3GHz instead of 8 cores at 6GHz.Now consider that the L1 and L2 caches are locked at 4 and 14 or so cycles. For 5 GHz, this corresponds to 0.8ns and 2.8ns for L1 and L2 respectively. Instead of turbo-boost, if we limited the P-core to 3GHz, could L2 be set to 10 cycles?
name99 - Wednesday, August 30, 2023 - link
Honestly by far the most interesting presentation is (surprise!) the ARM one.https://www.servethehome.com/arm-neoverse-v2-at-ho...
The reason it's so valuable is that it contains by far the most technical data. It's especially interesting to compare against Apple (which doesn't make this public, but which we know about if you read my PDFs).
The quick summary is that ARM continues to lag Apple in the algorithms they use for the CPU core, but with a constant lag – which is fine, since it means both are moving forward. (Unlike, say, Intel, where I can't tell WTF is happening; they seem to have given up on anything except moar+ GHz). If you simply go by IPC (SPEC2017) then Apple remains a few percent ahead, though less than in the past! Apple are still ahead in terms of power and the frequency they are willing to reach; but overall they're closer than they have been in a long time. I suspect this is basically a side effect of the exact timing relative to M3 not yet being out. But still, good going ARM!
Especially interesting are the callouts to how different improvements affect performance – and just how much better prefetch (and ARM's prefetch already was not bad) help things. As far as I can tell, ARM and Apple are essentially now equal in DATA prefetch ALGORITHMs. Apple is probably ahead in terms of resources (ie table sizes and suchlike) and in co-ordination across the entire SoC.
Apple remain far ahead in terms of INSTRUCTION prefetch running a doubly-decoupled fetch pipeline, not the singly-decoupled pipeline of ARM V2 (and Veyron V1); along with a whole set of next level branch prediction implementation details; but you don't see instruction fetch seriously tested on SPEC, for that you need to look at large codebases like browsers or sophisticated database benchmarks.
And it's not over yet. I think there's at least 50% or more IPC boost available just by continuing on the current round of careful tweaks and improvements, even without grand new ideas like PiM, or AMX style accelerators.
The Veyron paper is mildly interesting: https://www.servethehome.com/ventana-veyron-v1-ris... but they clearly don't have the manpower that ARM and Apple have, and it shows. They kinda know where they need to go, but who knows it they will ever be able to get there. You can compare it to the V2 paper to see just how much is missing – and how much it matters (basically they get about 50% of V2 IPC).
MiA are IBM (no idea what that's about given their previous track record) and anything useful, or impressive, from team x86. Even as everyone on team RISC understands where to go (how to run an optimal Fetch pipeline, an optimal branch prediction design, an optimal prefetch engine) team x86 seems determinedly stuck in the 2010s and incapable of moving on.
back2future - Saturday, September 2, 2023 - link
Are there system built-in statistics (tools) on hardware acceleration or hardware extensions utilization within different OS (Linux, MacOS, Windows, (Android)) for informing developers what extensions and hardware areas on CPUchiplets (efficiency) are involved with own working profiles (and to what extent)? At least, do CPU/SoC vendors analyze that area and provide statistics? (Thx)