AMD's 3rd generation Opteron versus Intel's 45nm Xeon: a closer look
by Johan De Gelas on November 27, 2007 6:00 AM EST- Posted in
- IT Computing
Floating-point Analyses (Linux 64-bit)
AMD's newest quad-core behaves pretty weird when it comes to floating-point applications. In some FP intensive applications (CINEBENCH and LINPACK for example) a 2GHz quad-core cannot even keep up with Intel's older 2GHz 65nm quad-core CPUs; in other applications it is a close match (3ds Max, POV-Ray); finally, in applications like zVisuel's 3D Engine and SPECfp, Barcelona is clearly faster clock-for-clock than the older generation. Our aim is to understand this situation a little better and to see what the 45nm Xeon 54xx can achieve.
To understand this we first tested with two synthetic, but completely opposite FP benchmarks:
- LINPACK,
which calculates on massive matrices
- FLOPS, which fits in an 8 KB L1 cache
Let us start with LINPACK. LINPACK, a benchmark application based on the LINPACK TPP code, has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight (dual quad-core) threads. As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPACK is expressed in GFLOPS (Giga/Billions of Floating Operations Per Second).
We used two versions of LINPACK:
- Intel's
version of LINPACK compiled with the Intel Math Kernel Library (MKL)
- A fully optimized "K10-only" version for AMD's quad-core
The "K10-only" version uses the ACML version 4.0.0, compiled using the PGI 7.0.7. We used the following flags:
pgcc -O3 -fast -tp=barcelona-64
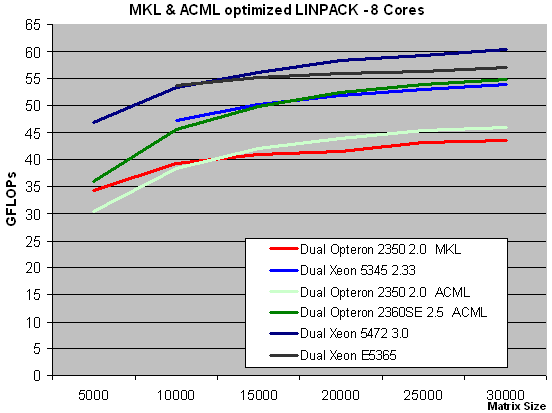
The graph above may come as a surprise to a quite few people. At the lower matrix sizes, AMD's quad-core is even a bit faster with the "Intel version" than with the specially optimized version. Only while calculating with the larger matrices does the heavily tuned version pull ahead. The K10-only version of LINPACK is about 6% faster, and the most important reason for that improvement is the ACML library of AMD. However, it is clear that the Intel MKL and compiler are not slowing the AMD core down when it is running LINPACK.
There is more. At first sight, the AMD 2360SE scores seem rather poor: just a tiny bit faster than the 2.33GHz quad-core of Intel. However, the Intel CPU scales rather poorly with clock speed: a 3GHz Clovertown is only 6% faster than a 2.33GHz one while the clock speed advantage is 28%. The Barcelona core however scales 19% from a 20% clock speed boost. The new Seaburg platform cannot help here: a 3GHz Xeon E5365 was capable of 57.1 GFLOPS, while it got 57 GFLOPS with the older chipset.
Intel's clever compiler engineers have already found a way around this, as the newest release of their LINPACK version is quite a bit faster on both Clovertown and Harpertown. The LINPACK score increases to 70 GLOPs for the Xeon 5472 3GHz (60.5 in our test) and 63 for the Xeon E5365 3GHz (57 in our test). Unfortunately, we don't have any data on what has changed, so we decided to freeze our benchmark code for now.








43 Comments
View All Comments
Regs - Tuesday, November 27, 2007 - link
I would not expect any from vendors and wholesalers until early next year.Matter of fact I wouldn't want one until then anyhow. I would at least wait until B3 stepping.
TA152H - Tuesday, November 27, 2007 - link
Johan,From my understanding, x87 is now obsolete and not even supported in x86-64. Can you verify this? I know I had read it, from your article you state that Intel improved it, so I'm not as sure. I had assumed one of AMD's handicaps was the disproportionate, and nearly useless, x87 processing power their processors carried, but now I am not as sure. Is x87 supported in x86-64, and if not, why would Intel increase their x87 capabilities when it's clearly a deprecated technology?
JohanAnandtech - Tuesday, November 27, 2007 - link
The x87 instructions can be used in legacy mode and long mode. But it is true that Scalar SSE instructions are preferred by AMD and Intel.x87 performance as many 32 bit programs are still important (look at 3DSMAx 32 bit).
If Intel's newest Core architecture would not have improved the x87 FP it would probably have looked silly as so many 32 bit programs still use it intensively. Secondly, as you can see, things like the Radix-16 circuitry are used by both the SIMD as the x87 units.
Gholam - Tuesday, November 27, 2007 - link
Do you have any plans to benchmark Opteron vs Xeon in an ESX Server environment?DeepThought86 - Tuesday, November 27, 2007 - link
This is exactly what I was thinking of too. I want to change my mode of working to run several separate VM's, one for programming, one for Office etc and really want to know how Phenom compares to Q6600 for those uses. Well, this article looks at the server versions of those chips but for VMware the performance might be more comparable than, say, SuperPi 1M benchmarks!DeepThought86 - Tuesday, November 27, 2007 - link
I forgot to add, since Phenom would presumably also have the nested table support as Barcelona, how much performance improvement would this yield? I'd love to knowsht - Tuesday, November 27, 2007 - link
I was about to ask the same question after reading the concludingYou may feel for example that using four instances in our SPECjbb test favors AMD too much, but there is no denying that using more virtual machines on fewer physical servers is what is happening in the real world.
Since the CPUs have features that should accelerate virtualization, it would really be interesting to see how they compete there. My only addition to your request would be to add KVM as host as well (and XEN and what not as well if you care, though I really think only KVM is of interest).
JohanAnandtech - Tuesday, November 27, 2007 - link
Indeed, we are working on that. The software that we described here (http://www.anandtech.com/IT/showdoc.aspx?i=2997&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2997&am... is being adapted to testing virtualized applications. We are also looking into the parameters that can really influence the results of a benchmark on a virtualized server.JohanAnandtech - Tuesday, November 27, 2007 - link
Indeed, we are working on that. The software that we described here (http://www.anandtech.com/IT/showdoc.aspx?i=2997&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2997&am... is being adapted to testing virtualized applications. We are also looking into the parameters that can really influence the results of a benchmark on a virtualized server.AssBall - Tuesday, November 27, 2007 - link
Thanks, Johan.This has been one of the clearer and better proofread articles I have read here lately. It was interesting, unbiased, and insightful. I am excited to see what you get into for your next project.