Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
OoOE
You’re going to come across the phrase out-of-order execution (OoOE) a lot here, so let’s go through a quick refresher on what that is and why it matters.
At a high level, the role of a CPU is to read instructions from whatever program it’s running, determine what they’re telling the machine to do, execute them and write the result back out to memory.
The program counter within a CPU points to the address in memory of the next instruction to be executed. The CPU’s fetch logic grabs instructions in order. Those instructions are decoded into an internally understood format (a single architectural instruction sometimes decodes into multiple smaller instructions). Once decoded, all necessary operands are fetched from memory (if they’re not already in local registers) and the combination of instruction + operands are issued for execution. The results are committed to memory (registers/cache/DRAM) and it’s on to the next one.
In-order architectures complete this pipeline in order, from start to finish. The obvious problem is that many steps within the pipeline are dependent on having the right operands immediately available. For a number of reasons, this isn’t always possible. Operands could depend on other earlier instructions that may not have finished executing, or they might be located in main memory - hundreds of cycles away from the CPU. In these cases, a bubble is inserted into the processor’s pipeline and the machine’s overall efficiency drops as no work is being done until those operands are available.
Out-of-order architectures attempt to fix this problem by allowing independent instructions to execute ahead of others that are stalled waiting for data. In both cases instructions are fetched and retired in-order, but in an OoO architecture instructions can be executed out-of-order to improve overall utilization of execution resources.
The move to an OoO paradigm generally comes with penalties to die area and power consumption, which is one reason the earliest mobile CPU architectures were in-order designs. The ARM11, ARM’s Cortex A8, Intel’s original Atom (Bonnell) and Qualcomm’s Scorpion core were all in-order. As performance demands continued to go up and with new, smaller/lower power transistors, all of the players here started introducing OoO variants of their architectures. Although often referred to as out of order designs, ARM’s Cortex A9 and Qualcomm’s Krait 200/300 are mildly OoO compared to Cortex A15. Intel’s Silvermont joins the ranks of the Cortex A15 as a fully out of order design by modern day standards. The move to OoO alone should be good for around a 30% increase in single threaded performance vs. Bonnell.
Pipeline
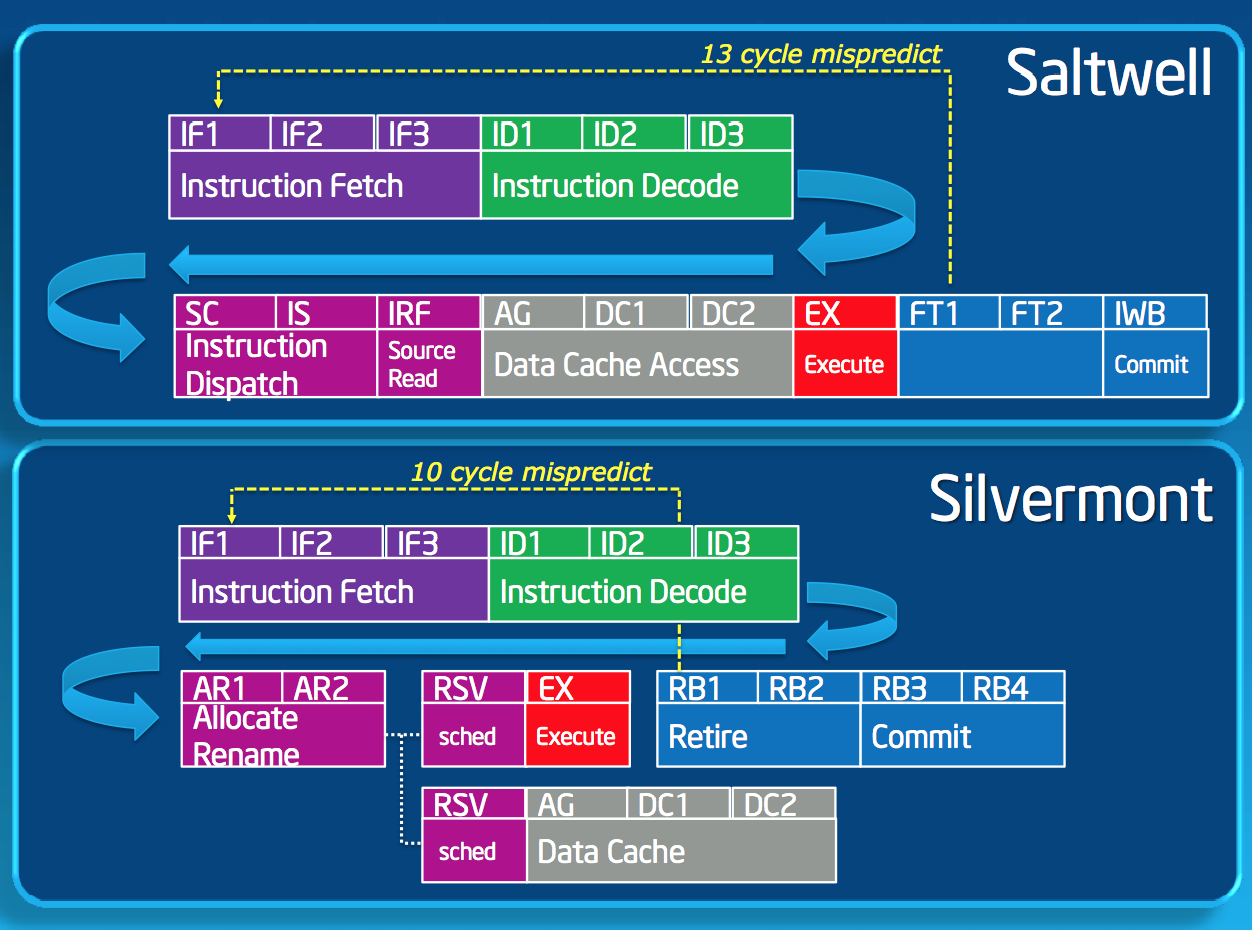
Silvermont changes the Atom pipeline slightly. Bonnell featured a 16 stage in-order pipeline. One side effect to the design was that all operations, including those that didn’t have cache accesses (e.g. operations whose operands were in registers), had to go through three data cache access stages even though nothing happened during those stages. In going out-of-order, Silvermont allows instructions to bypass those stages if they don’t need data from memory, effectively shortening the mispredict penalty from 13 stages down to 10. The integer pipeline depth now varies depending on the type of instruction, but you’re looking at a range of 14 - 17 stages.
Branch prediction improves tremendously with Silvermont, a staple of any progressive microprocessor architecture. Silvermont takes the gshare branch predictor of Bonnell and significantly increased the size of all associated data structures. Silvermont also added an indirect branch predictor. The combination of the larger predictors and the new indirect predictor should increase branch prediction accuracy.
Couple better branch prediction with a lower mispredict latency and you’re talking about another 5 - 10% increase in IPC over Bonnell.








174 Comments
View All Comments
tech4real - Tuesday, May 7, 2013 - link
"Absolute performance"? Do we consider power constraint here at all? Atom is optimized for power-efficiency. All the current information I've seen so far suggest Silvermont will outperform A15 by a large margin in terms of power efficiency. If we throw away power constraint, Intel has Core to take care of that.Wilco1 - Tuesday, May 7, 2013 - link
I was talking about peak performance, but yes, power consumption matters too. What we've seen so far is Intel marketing suggesting that in 6-9 months time Silvermont will be more efficient than A15 was 12 months earlier. However that's not what Silvermont will have to compete with. At the end of this year A15 will have had 2 process shrinks down to 20nm in addition to a lot of tuning, so it will be far more efficient than it was 12 months ago. And A15 is just one example, Apple, QC and ARM will have new cores as well. It's reasonable to say that Intel will finally be able to compete with Silvermont, but it is far from clear that it is the overall winner like their marketing claims.tech4real - Wednesday, May 8, 2013 - link
TSMC's 20nm process is still in the works, your Q4'13 volumn production estimate seems way too optimistic, especially considering TSMC's pain in 28nm ramp. Also 28nm->20nm shrink without finfet significantly reduces its benefit.Wilco1 - Wednesday, May 8, 2013 - link
TSMC have learnt from the 28nm problems. They appear very aggressive this time, and so far the reports are they are 2 months ahead of schedule. Even if it ends up delayed to Q2'14 it's still around the same time Intel is planning to come out with Silvermont phones. The gains are not as large as with FinFETs, but enough to reduce power significantly.tech4real - Wednesday, May 8, 2013 - link
my understanding is Q2'14 volume production with high yield is almost TSMC 20nm best case scenario. Of course, the term "high yield" is such a subjective thing vendors love to manipulate with almost infinite freedom...zeo - Wednesday, May 8, 2013 - link
TSMC 20nm isn't set up for such optimization, but rather focused on cost reductions... The number of nodes, variations supported, etc will be fewer than they did with 28nm as they want to avoid the problems that caused the 28nm delays and that has resulted in a much more streamlined setup.While power leakage issues increase as FAB size is decreased... So without a solution like FinFET the power efficiency would be increasingly harder to keep it where it is, let alone reduce it...
It's one of the reasons why ARM is trying to push other options like Big.LITTLE to boost operational efficiencies and not rely as much on FAB improvements.
While it's also why not all ARM SoCs have moved to 28nm yet as for many the power leakage was still too much of a issue for their designs to make the switch right away, so there could be additional delays for 20nm releases.
Though ARM should get FinFET in time for for the 64bit release... but by that time Intel would be on its way to 14nm...
Jaybus - Wednesday, May 8, 2013 - link
Think of it as 2-wide x86 vs. 3-wide RISC. Rather than translating the x86 microcoded instruction into 2 or 3 RISC-like instructions, Intel's decode keeps it a single instruction down the pipeline. The RSIC architecture has to decode more instructions, so needs the 3-wide to keep up with the x86 2-wide.The point about the frequency scaling is this. The tri-gate design has a gate on top of 2 vertical gates. This gives it 3x the surface area as compared to FinFET. The greater surface area allows more electrons to flow within a given area of the die, and that allows a greater range of voltages and/or frequencies for which it can operate efficiently.
Wilco1 - Thursday, May 9, 2013 - link
Eventhough macro-ops helps decode, they need to be expanded before they are executed. So in terms of execution, macro-ops don't help. Also as I mentioned in an earlier post, most ARMs also support macro-ops, allowing a 2-way ARM to behave like a 4-way. So macro-ops don't give x86 an advantage over RISC.jemima puddle-duck - Monday, May 6, 2013 - link
Without wishing to be overly cynical, Anandtech has a history of 'NOW Intel will win the mobile war' articles, which get recycled then forgotten in time for the next launch. It's all very clever stuff, but curiously underwhelming also.Roffles12 - Monday, May 6, 2013 - link
I don't remember reading any 'NOW Intel will win the mobile war' articles on Anandtech. Perhaps your perception is skewed. Intel articles are typically of a technical nature discussing the inner workings of the architecture and fab process or discussing benchmarks. Intel is really the only company so completely open about how their technology works, so why not make it a point of discussion on a website on a website dedicated to the subject? If your head is clouded by fud from competing companies and the constantly humming rumor mill, maybe you need to back off for a while. At the end of the day, it's up to you to digest this information and form an opinion.