Apple's Cyclone Microarchitecture Detailed
by Anand Lal Shimpi on March 31, 2014 2:10 AM EST
The most challenging part of last year's iPhone 5s review was piecing together details about Apple's A7 without any internal Apple assistance. I had less than a week to turn the review around and limited access to tools (much less time to develop them on my own) to figure out what Apple had done to double CPU performance without scaling frequency. The end result was an (incorrect) assumption that Apple had simply evolved its first ARMv7 architecture (codename: Swift). Based on the limited information I had at the time I assumed Apple simply addressed some low hanging fruit (e.g. memory access latency) in building Cyclone, its first 64-bit ARMv8 core. By the time the iPad Air review rolled around, I had more knowledge of what was underneath the hood:
As far as I can tell, peak issue width of Cyclone is 6 instructions. That’s at least 2x the width of Swift and Krait, and at best more than 3x the width depending on instruction mix. Limitations on co-issuing FP and integer math have also been lifted as you can run up to four integer adds and two FP adds in parallel. You can also perform up to two loads or stores per clock.
With Swift, I had the luxury of Apple committing LLVM changes that not only gave me the code name but also confirmed the size of the machine (3-wide OoO core, 2 ALUs, 1 load/store unit). With Cyclone however, Apple held off on any public commits. Figuring out the codename and its architecture required a lot of digging.
Last week, the same reader who pointed me at the Swift details let me know that Apple revealed Cyclone microarchitectural details in LLVM commits made a few days ago (thanks again R!). Although I empirically verified many of Cyclone's features in advance of the iPad Air review last year, today we have some more concrete information on what Apple's first 64-bit ARMv8 architecture looks like.
Note that everything below is based on Apple's LLVM commits (and confirmed by my own testing where possible).
| Apple Custom CPU Core Comparison | ||||||
| Apple A6 | Apple A7 | |||||
| CPU Codename | Swift | Cyclone | ||||
| ARM ISA | ARMv7-A (32-bit) | ARMv8-A (32/64-bit) | ||||
| Issue Width | 3 micro-ops | 6 micro-ops | ||||
| Reorder Buffer Size | 45 micro-ops | 192 micro-ops | ||||
| Branch Mispredict Penalty | 14 cycles | 16 cycles (14 - 19) | ||||
| Integer ALUs | 2 | 4 | ||||
| Load/Store Units | 1 | 2 | ||||
| Load Latency | 3 cycles | 4 cycles | ||||
| Branch Units | 1 | 2 | ||||
| Indirect Branch Units | 0 | 1 | ||||
| FP/NEON ALUs | ? | 3 | ||||
| L1 Cache | 32KB I$ + 32KB D$ | 64KB I$ + 64KB D$ | ||||
| L2 Cache | 1MB | 1MB | ||||
| L3 Cache | - | 4MB | ||||
As I mentioned in the iPad Air review, Cyclone is a wide machine. It can decode, issue, execute and retire up to 6 instructions/micro-ops per clock. I verified this during my iPad Air review by executing four integer adds and two FP adds in parallel. The same test on Swift actually yields fewer than 3 concurrent operations, likely because of an inability to issue to all integer and FP pipes in parallel. Similar limits exist with Krait.
I also noted an increase in overall machine size in my initial tinkering with Cyclone. Apple's LLVM commits indicate a massive 192 entry reorder buffer (coincidentally the same size as Haswell's ROB). Mispredict penalty goes up slightly compared to Swift, but Apple does present a range of values (14 - 19 cycles). This also happens to be the same range as Sandy Bridge and later Intel Core architectures (including Haswell). Given how much larger Cyclone is, a doubling of L1 cache sizes makes a lot of sense.
On the execution side Cyclone doubles the number of integer ALUs, load/store units and branch units. Cyclone also adds a unit for indirect branches and at least one more FP pipe. Cyclone can sustain three FP operations in parallel (including 3 FP/NEON adds). The third FP/NEON pipe is used for div and sqrt operations, the machine can only execute two FP/NEON muls in parallel.
I also found references to buffer sizes for each unit, which I'm assuming are the number of micro-ops that feed each unit. I don't believe Cyclone has a unified scheduler ahead of all of its execution units and instead has statically partitioned buffers in front of each port. I've put all of this information into the crude diagram below:
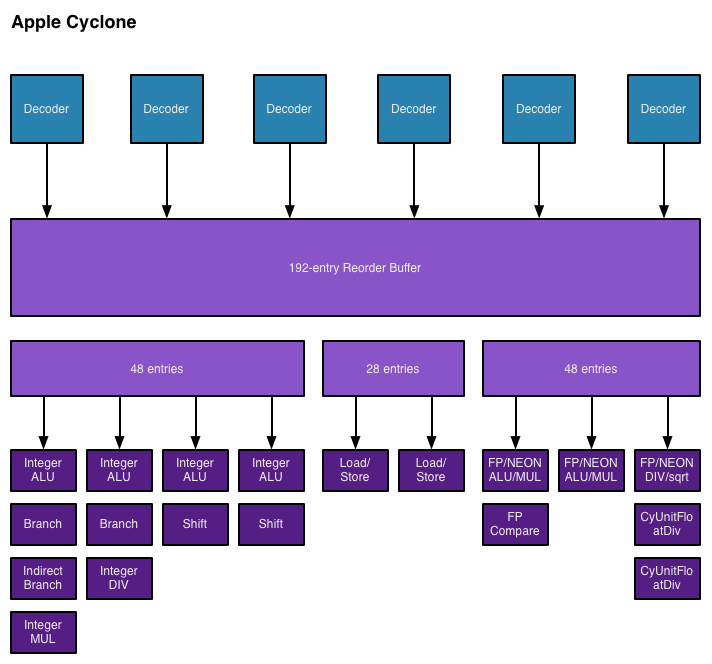
Unfortunately I don't have enough data on Swift to really produce a decent comparison image. With six decoders and nine ports to execution units, Cyclone is big. As I mentioned before, it's bigger than anything else that goes in a phone. Apple didn't build a Krait/Silvermont competitor, it built something much closer to Intel's big cores. At the launch of the iPhone 5s, Apple referred to the A7 as being "desktop class" - it turns out that wasn't an exaggeration.
Cyclone is a bold move by Apple, but not one that is without its challenges. I still find that there are almost no applications on iOS that really take advantage of the CPU power underneath the hood. More than anything Apple needs first party software that really demonstrates what's possible. The challenge is that at full tilt a pair of Cyclone cores can consume quite a bit of power. So for now, Cyclone's performance is really used to exploit race to sleep and get the device into a low power state as quickly as possible. The other problem I see is that although Cyclone is incredibly forward looking, it launched in devices with only 1GB of RAM. It's very likely that you'll run into memory limits before you hit CPU performance limits if you plan on keeping your device for a long time.

It wasn't until I wrote this piece that Apple's codenames started to make sense. Swift was quick, but Cyclone really does stir everything up. The earlier than expected introduction of a consumer 64-bit ARMv8 SoC caught pretty much everyone off guard (e.g. Qualcomm's shift to vanilla ARM cores for more of its product stack).
The real question is where does Apple go from here? By now we know to expect an "A8" branded Apple SoC in the iPhone 6 and iPad Air successors later this year. There's little benefit in going substantially wider than Cyclone, but there's still a ton of room to improve performance. One obvious example would be through frequency scaling. Cyclone is clocked very conservatively (1.3GHz in the 5s/iPad mini with Retina Display and 1.4GHz in the iPad Air), assuming Apple moves to a 20nm process later this year it should be possible to get some performance by increasing clock speed scaling without a power penalty. I suspect Apple has more tricks up its sleeve than that however. Swift and Cyclone were two tocks in a row by Intel's definition, a third in 3 years would be unusual but not impossible (Intel sort of committed to doing the same with Saltwell/Silvermont/Airmont in 2012 - 2014).
Looking at Cyclone makes one thing very clear: the rest of the players in the ultra mobile CPU space didn't aim high enough. I wonder what happens next round.








182 Comments
View All Comments
Guspaz - Tuesday, April 1, 2014 - link
Get ahead of? Sure, not so much. But do well enough to make it work? Sure. They have the advantage of all the OS-level stuff running natively, leaving just the userland stuff. As WaltFrench pointed out, they also have the ability to push people towards easy recompilation (the whole fat binaries thing). And since they'd be designing the whole CPU from the ground up, they can afford to implement features intended to improve emulation. They can add extra registers and instructions, or they can actually implement a chunk of the emulation in hardware.There's a precedence for this too... ARM chips, for a while, supported Jazelle, which enabled them to run Java bytecode in hardware. They basically did binary translation on the Java instructions of one of the stages of the processor's pipeline. I'm not sure how far Apple could get without an x86 license, but Apple could probably use their patent portfolio to strongarm Intel. Also, their cash reserves are big enough that they have enough money to simply buy Intel, and while that's totally impractical (both because of the difficulty of a hostile takeover as well as the fact that that's not really how their cash reserves work), it gives you an idea about the resources they could dedicate to getting an x86 license.
Kevin G - Tuesday, April 1, 2014 - link
Having been a Mac user through the 68k -> PowerPC transition, I can say that the first generation of PowerMacs were only faster than their 68k predecessors when running native PowerPC code. It wasn't until systems using the 604e that emulation of 68k became noticeably faster than running on high end 68k Mac.The PowerPC to x86 transition was far faster. The NextStep roots of OS X enabled multiple binary bundles, included both 32 bit and 64 bit implementations of the same architecture. Xcode could be used to compile code to all architectures into one of these bundles for ease of distribution. This enabled a quick transition. It also helped that OS X had full x86 binaries by the time 10.5 rolled around and was x86 only when 10.6 shipped. (In comparison 68k code wasn't completely removed from Macs until OS X arrived, 7 years after PowerPC hardware first shipped.)
Anders CT - Tuesday, April 1, 2014 - link
There is no inherent advantage in the ARMv8-instruction set when it comes to power comsumption, nor is there any inherent Intel advantage when it comes to performace.The traditional advantage x86 enjoyed, was tight coupling with the major software-stacks, leading to strong developer capture. That advantage has completely evaporated with the rise of mobile.
It is not about performance or power as much as it is about programmer mindshare and zeitgeist.
Intel knows this. Last year they bragged about having 1200 engineers working on Android, in spite of Intels home-market being desktop windows and linux-servers.
OreoCookie - Tuesday, April 1, 2014 - link
»There is no inherent advantage in the ARMv8-instruction set when it comes to power comsumption, nor is there any inherent Intel advantage when it comes to performace.«Sure, there is: on average http://anandtech.com/show/7335/the-iphone-5s-revie...">code runs significantly faster in 64 bit mode compared to 32 bit mode (on average about 10~30 %, for cryptographic workloads significantly more). This is free performance you get from just recompiling your code. (And yes, I'm aware it's not necessarily connected to 64 vs. 32 bit, but stuff like having more registers at your disposal and a cleaner ISA.) With that increase in performance, your device can race to sleep faster, and that should help performance.
fteoath64 - Monday, March 31, 2014 - link
I agree. I have been saying 'Intel get an Arm license and build the best Arm SoC that ever exist!". That is the ONLY way for Intel to fight Apple or any potential Arm vendors rising (in unstoppable fashion). X86 has been a limiting factor as Intel cannot really squeeze much out of it while Arm has plenty of potential to tap as yet. Besides, Arm has better multicore implementation compared to the loose coupling of x86 cores. Arm in HSA ?. Arm interconnects in HPCs ?. Many variants has already been tried and tested in Arm, so risks in making one or few of those mainstream is going to do the industry a lot of good. X96 compatibility is a farce and a FUD!.coder543 - Monday, March 31, 2014 - link
As much as I love ARM (and would love to get to know the MIPS Warrior core), Intel shattered all expectations when they released Haswell -- and then again with Bay Trail. No one would ever have believed x86 could be so energy efficient and still high performance. ARM has potential yet, but Intel secured their future for the near-term quite well. They shored up their defenses against ARM with good, if a little belated, timing.OreoCookie - Monday, March 31, 2014 - link
No, they haven't, because it's as much an ecosystem argument as an architectural one: the main obstacle for Windows on ARM is the lack of applications, and the converse also holds in the non-Windows tablet market and phone market. Intel hasn't made much in-roads.Guspaz - Monday, March 31, 2014 - link
Intel has an ARM license (at the architectural level to boot), and they used to be a huge player in the ARM SoC space. They bought StrongARM from DEC in the 90s, and the Intel XScale line of ARM processors were used in most smartphones and PDAs back in the day.They got out of the business, although Intel does still fab some ARM chips.
extide - Monday, March 31, 2014 - link
Intel got out of the ARM business so they could focus on Atom. Honestly, I am not sure if it was the right move. I could easily see a future where Atom goes away and they just use the Big cores scaled down, much like Apple has done here. Another interesting alternate universe would have Intel ditching Atom and building custom ARM IP...Honestly, I think it would be cool to see a (desktop?) performance war between Intel and Apple on cpu's. I mean, just to have a performance war going on again at all would be cool.
Kevin G - Monday, March 31, 2014 - link
Except that Apple has effectively given up on the traditional desktop. They're into all-in-ones and small form factor devices. Even the new Mac Pro falls into this category as there is no expansion and in most configurations an upgrade means replacing an existing part.