Hot Chips 32 (2020) Schedule Announced: Tiger Lake, Xe, POWER10, Xbox Series X, TPUv3, Raja Koduri Keynote
by Dr. Ian Cutress on July 8, 2020 9:01 AM EST
This article has been updated with the latest schedule for the Hot Chips conference. Due to Jim Keller leaving Intel recently, the main change has been the Day One keynote - Raja Koduri is presenting on behalf of Intel in Jim's stead.
I’ve said it a million times and I’ll say it again – the best industry conference I go to every year is Hot Chips. The event has grown over the years, to around 1700 people in 2019 if I remember correctly, but it involves two days of presentations about the latest hardware that has hit the market. This includes new and upcoming parts that change the industry we work in, including deep dives into some of the most important silicon at play in the market today. There are also extensive keynote presentations from the most prominent members of the industry that give insights into how these people (and the companies) work, but also where the future is going.
This week the lid was lifted on the provision Hot Chips 2020 schedule. With COVID-19 in mind, this year will also be the first year the conference will be offered online-only for attendees. Hot Chips 2020 is scheduled for August 16th to August 18th.
Hot Chips is traditionally over three days: a first day of tutorials, and two days of presentations. Times are given as Pacific Time (PT).
Tutorial Day
This year the tutorials are covering Machine Learning and Quantum Computing.
| Hot Chips 32 (2020): Tutorial Day | |||
| AnandTech | Speaker | Company | Info |
| 08h30 - 13h00 | Machine Learning Scaleout Systems | ||
| Michael Houston | NVIDIA | DXG A100 SuperPOD | |
| Sameer Kumar | Google TPU Pod | ||
| Dehao Chen | |||
| Natalia Vassilieva | Cerebras | Cerebras CS-1 | |
| Machine Learning Scaleout Training | |||
| Mohammed Shoeybi | NVIDIA | Megatron Language Model | |
| Weijie Zhao | Baidu | Distributed Parameter Server for Massive Recommender System | |
| Zhifeng Chen | GShard: Scalaing Giant Models with Conditional Computation and Automatic Sharding | ||
| Noam Shazeer | |||
| 14h00 - 17h15 | Quantum Computing | ||
| John Martinis | USCB | Quantum Supremacy Using a Programmable Superconducting Processor | |
| Jarrod McClean | Applications and Challenges with Near-Term Quantum Hardware | ||
| Matthias Steffen | IBM | Underneath the Hood of a Superconducting Qubit Quantum Supercomputer | |
| Oliver Dial | |||
| James S. Clarke | Intel | Towards a Large-Scale Quantum Comptuer Using Silicon Spin Qubits | |
| David Reilly | Microsoft | If Only We Could Control Them: Challenges and Solutions in Scaling the Control Interface of a Quantum Computer | |
The first presentation deals with a popular topic of machine learning being scaled across large systems. The ability to train a model across a supercomputer, like an NVIDIA DGX, or across across a large cluster, like a TPU pod, is essential in order to get the appropriate linear speedups that using multiple units of hardware requires. This presentation (presenters TBD) will cover both software for parallelizing a neural network and also the infrastructure required for companies that want to scale out. Some basic knowledge of the principles of ML will likely be required.
The second tutorial is on Quantum Computing. There is a lot of research into the state of Quantum Computing, as well as a lot of talk about achieving a level of ‘Quantum Supremacy’ to tasks that are actually worthwhile for computational problems today, or for ten years in the future. The speakers for this presentation will cover the range from the different types of Quantum computing, to the infrastructure required to enable it, plus also the challenges in actually making it happen and applying programs to them. It should make for a densely packed 3 ¼ hour tutorial.
Day One: Morning
Day One is going to be very busy, and is split into five sessions, from 9:15am to 7pm PT.
As with any conference, the opening minutes are spent detailing the conference, what’s new for the year, and some of the rules (such as no streaming). I suspect there will be a large discussion about how the COVID situation will affect the presentations, what to do if one of the presentations fails, or such. I actually hope that the presentations are pre-recorded so that doesn’t happen.
The first session is on Server Processors.
| Hot Chips 32 (2020): Day One, Session 1 Server Processors |
|||
| AnandTech | Speaker | Company | Info |
| 09h15 | Opening Remarks | ||
| 09h30 | Irma Esmer Papzian | Intel | Next Generation Intel Xeon Scalable Server Processor: Ice Lake-SP |
| 10h00 | William Starke | IBM | IBM's POWER10 Processor |
| Brian W Thompto | |||
| 10h30 | Rabin Sugumar | Marvell | Marvell ThunderX3 Next Generation Arm-Based Server Processor |
| 11h00 | Antony Saporito | IBM | The 5.2 GHz IBM z15 Processor |
Straight off the bat we have a 30 minute talk on Intel’s Ice Lake-SP hardware. Never mind Cooper Lake, Intel is keen to promote its next generation Xeon Scalable processor line. This talk is likely to recap all the new features that the Ice Lake core brings to the table, but also adjustments that have been made for the server processor, updates to the mesh, core counts, PCIe layout, and perhaps even some platform infrastructure. We have not heard yet if Intel will announce Ice Lake-SP before Hot Chips, so some of this we might know already by then.

Intel’s Sailesh Kothapalli with an Ice Lake Xeon CPU in Dec 2018
The second talk is from IBM, on its newest POWER10 processor. IBM has teased this processor in roadmaps at previous Hot Chips conferences, with this latest design. Last year the company said that POWER10 will feature PCIe 5.0, up to 800 GB/s of memory bandwidth, and be based on a new microarchitecture and a new process technology. The finer details aren’t clear, but for POWER9 the company did implement a new configurable memory system called OMI, so it will be interesting to see if that makes it into the new design.

From IBM’s Power9 AIO talk at Hot Chips 2019
The third talk is on Marvell/Cavium’s ThunderX3 processor design, something which we’ve reported on recently as Marvell has announced details. The new chip uses 96 custom Arm v8.3+ cores, built on TSMC 7nm, with up to four threads per core. There’s 8 channels of DDR4-3200, 64 lanes of PCIe 4.0, four 128-bit SIMD units per core, and support for dual socket operation. This is the upgrade to the ThunderX2, which has been seen in a number of mid-range deployments for HPC. With support for CUDA on Arm, we expect to hear a lot about it at Hot Chips, along with a detailed guide of the microarchitecture hopefully.

The final talk of the session is again from IBM, this time on the z15 processor line. The title of the talk is listed as 5.2 GHz, indicating how fast these processors can go, and we expect this talk to be an extension of the talk given at ISSCC earlier this year. I still want to write this processor analysis up in detail, when there’s a break in the barrage of product releases so far this month.

The second session of the day is on Mobile (aka Notebook) processors.
| Hot Chips 32 (2020): Day One, Session 2 Mobile Processors |
|||
| AnandTech | Speaker | Company | Info |
| 12h00 | Sonu Arora | AMD | AMD Next Generation 7nm Ryzen 4000 APU |
| 12h30 | Xavier Vera | Intel | Inside Tiger Lake: Intel's Next Generation Mobile Client CPU |
Talk one is on AMD’s Ryzen 4000 APUs, codenamed Renoir. We have gone into a deep dive on this processor when it was announced, as well as a number of reviews on products that have come out. I’m hoping that this presentation might go into some of the design choices that had to be made with a monolithic 7nm design between Zen 2 and an updated Vega 8 pairing, as well as the decoupling of the Infinity Fabric to main memory. For users expecting to see a large discussion about desktop versions of Renoir, Hot Chips isn’t going to speak specifically about that – it is more of a conference about the platform design.

The second talk of the session is going to be highly anticipated, with Intel going into detail about its new Tiger Lake processor for notebooks. We’ve had a sneak peak at a wafer, along with some close-up die shots to get a feel for what should be a quad-core design with 96 execution units with the new Xe graphics architecture. Again, we’re not sure if Intel is going to use this event as a big announcement point, or if we’re going to get some information before the event. What I can hope for is that Hot Chips is a platform where Intel can talk about some of the 10nm improvements they’ve had to make in order to get Tiger Lake to work.

Tiger Lake. Just ask Carole Baskin.
Day One: Keynote
After the first two sessions comes the keynote, headed up by Intel’s Raja Koduri, Senior VP, Chief Architect, and GM of Architecture, Graphics and Software.

The keynotes at Hot Chips aren’t necessarily a ground for announcing new items, but with Raja on the stage I expect him to go into more detail about how things have changed at Intel to get into graphics. He’s been there just over three years, which is enough time to bring about a lot of change. Hopefully this keynote will enable Raja to go into some specifics, though given the secretive nature of what he does, perhaps not – but it will enable Raja to define some elements of the industry and where he has been taking Intel along that path.
Initially Jim Keller was set to preset this keynote, however he has left Intel due to personal issues. We wish Jim the best. Aaron Pressman of Fortune recently published a detailed look into Jim Keller, along with comments and quotes from a number of the industry covering his past, his present, and some goals for the future. If you have access, it is well worth a read.
Day One: Afternoon
The first afternoon session on day one is on Edge Computing and Sensing.
| Hot Chips 32 (2020): Day One, Session 3 Edge Computing and Sensing |
|||
| AnandTech | Speaker | Company | Info |
| 15h00 | Yu Pu | Alibaba | Xuantie-910: Innovating Cloud and Edge Computing by RISC-V |
| 15h30 | Allan Skillman | Arm | A Technical Overview of the Arm Cortex-M55: Arm's Most AI-capable Cortex-M Processor |
| Tomas Edso | |||
| 16h00 | Glenn G. Ko | Harvard University |
PGMA: A scalable Bayesian Inference Accelerator for Unsupervised Learning |
The first talk on RISC-V has the potential to be interesting if there’s some serious applications to how RISC-V is developing. The second talk on the Arm Cortex M55 is probably the most relevant to us, and Arm announced the M55 core back in February, so hopefully this talk will be a chance to look into the architecture of the design.
The second afternoon session on day one is another exciting one: GPUs and Gaming Architectures
| Hot Chips 32 (2020): Day One, Session 4 GPUs and Gaming Architectures |
|||
| AnandTech | Speaker | Company | Info |
| 17h00 | Jack Choquette | NVIDIA | NVIDIA's Next Generation GPU: Performance and Innovation for GPU Computing |
| 17h30 | David Blythe | Intel | The Xe GPU Architecture |
| 18h00 | Jeff Andrews | Microsoft | Xbox Series X System Architecture |
| Mark Grossman | |||
Talk one is from NVIDIA, discussing the ‘Next Generation GPU’. We can all come to the conclusion that this means Ampere, which was recently announced for HPC in the form of the A100. However as with the Renoir discussion earlier, this talk isn’t specifically going to go into consumer products – these Hot Chips talks will focus on a design philosophy and talk about the different variants therein, so while we expect to hear about some of the optimizations that might be made for consumer graphics, a lot of the talk will be going towards what is already out there (HPC-focused A100) and then optimizations made for either compute or for graphics.

The second talk of the session is from Intel, on the Xe GPU architecture. Now there are a couple of ways Intel could swing this talk – it could either be a discussion similar to the one by Raja Koduri at Supercomputing 2019, talking about some of the different ways in which Xe can do SIMD and SIMT, or it could be a chance for the company to go into more detail about configurations and infrastructure. This is only a 30 minute talk, so we have to be wary here – I suspect at least 5-10 minutes will be dedicated to OneAPI, leaving only a little time to talk silicon. As with the NVIDIA talk, users looking for consumer graphics related details aren’t likely to find anything specific here.

The final talk in a very long day is from Microsoft, about the Xbox Series X system architecture. This is likely going to focus on the infrastructure design on the console, the collaboration with AMD on the processor, perhaps some insight into new features we’re going to find in the console, and how the chip is going to drive the next 4-8 years of console gaming. I’m actually a bit 50-50 on this talk, as we’ve had presentations like this at events before (e.g. Qualcomm’s XR) which didn’t actually say anything that wasn’t already announced. There’s the potential here for Microsoft to not say anything new, but I hope that they will go into more detail.

Day Two: Morning
The second day starts with a session on FPGAs and Reconfigurable Devices
| Hot Chips 32 (2020): Day Two, Session 1 FPGAs and Reconfigurable Architectures |
|||
| AnandTech | Speaker | Company | Info |
| 8h30 | Ilya Ganusov | Intel | Agilex Generation of Intel FPGAs |
| 9h00 | Saheer Ahmad | Xilinx | Xilinx Versal Premium Series |
| 9h30 | Ljubisa Bajic | Tenstorrent | Neurons vs NAND Gates vs Networks: Finding the Right Compute Substrate for Artificial Intelligence |
The first talk is on Intel’s Agilex generation of FPGAs. These are Intel’s biggest 10nm silicon, and although they’ve been out for a while. Intel’s 14nm family of Stratix silicon scales all the way from small to large dies, so perhaps here we will get an insight into just how large Agilex might get, power depending. We’ve only seen Agilex-F in the market so far, and we’re waiting for Agilex-I with 112G transceivers and Agilex-M with PCIe 5.0 with Optane support.

Next is a presentation from Xilinx or its Versal Premium series. We didn’t cover these when they were first announced, but the new Xilinx Versal Premium is the realisation of its vision for an ACAP – an adaptive compute acceleration platform based on an FPGA and hardened silicon that can operate through libraries rather than bitstreams. The Premium models are the top tier parts, with PCIe 5.0, 112G trancievers, HBM options, DSP Engines, Ethernet cores, and high-speed crypto engines. As with the Agilex presentation, we’re guessing that this Hot Chips presentation will align with a product being ready for demonstration perhaps.
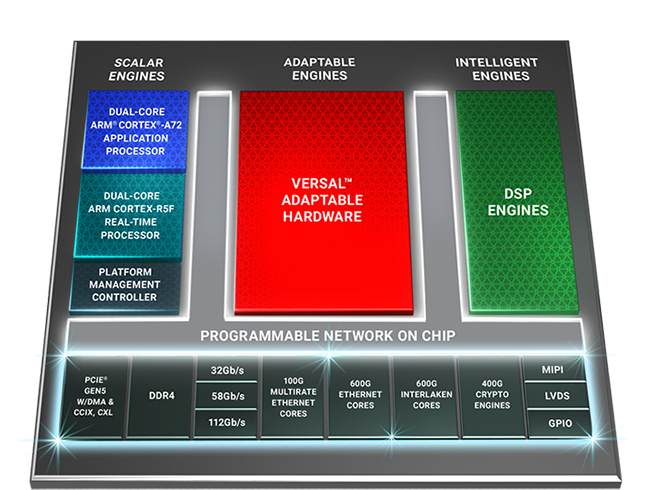
Versal Premium ACAP
The final talk of the session is from Tenstorrent, on Neurons vs NAND Gates vs Networks. This is likely going to be a study in finding which of these is going to be the right compute element for a variety of applications.
The second session on the day is for Networking and Distributed Systems
| Hot Chips 32 (2020): Day Two, Session 2 Networking and Distributed Systems |
|||
| AnandTech | Speaker | Company | Info |
| 10h30 | Anurag Agrawal | Intel / Barefoot | Tofino2 - A 12.9 Tbps Programmable Ethernet Switch |
| Changhoom Kim | |||
| 11h30 | Francis Matus | Pensando | Pensando Distributed Services Architecture |
| 12h00 | Pradeep Singhu | Fungible | The DPU: A New Category of Microprocessor |
| 12h00 | Justin Song | Alibaba | High-density Multi-tenant Bare-metal Cloud with Memory Expansion SoC and Power Management |
| Xiantao Zhang | |||
I don’t have much to say here – the Alibaba presentation at the end about a multi-tenant bare metal cloud SoC is likely to be interesting to watch.
Day Two: Keynote
The keynote for the second day is by Dan Belov, Distinguished Engineer at Deepmind.

Deepmind is the company that created the AlphaGo program that played professional Go champion Lee Sedol in 2016, with the final score of 4-1 in favor of the artificial intelligence. This will likely be an update to what’s going on at Deepmind (now owned by Alphabet) and what they’re planning for the future of AI. We might get some insight as to how the company is working with other departments inside Alphabet – it has been cited that Deepmind has used its algorithms to increase the efficiency of cooling inside Google’s datacenters, for example.
Day Two: Afternoon
The afternoon of the final day is dedicated to Machine Learning. The first session of the afternoon will be for Training.
| Hot Chips 32 (2020): Day Two, Session 3 Machine Learning, Training |
|||
| AnandTech | Speaker | Company | Info |
| 14h30 | Thomas Norrie | Google's Training Chips Revealed: TPUv2 and TPUv3 |
|
| Nishant Patil | |||
| 15h00 | Sean Lie | Cerebras | The Second Generation Cerebras Wafer Scale Engine |
| 15h30 | Florian Zaruba | ETH Zurich | Manticore: A 4096-core RISC-V Chiplet Architecture for Ultra-efficient Floating-point Computing |
| Fabian Schuiki | |||
The first talk is from Google, who will *finally* lift the lid of its TPUv2 and TPUv3 chips used internally for training its algorithms. Google initially disclosed the design of TPUv1 at Hot Chips 2017, and I believe this talk has been highly requested by a lot of the attendees for the past couple of years, so I hope that there’s an opportunity to go into some level of complex detail here.

TPU v3 blade, as seen at Supercomputing 19
The second talk of the session is from Cerebras, known famously for creating its Wafer Scale Engine (WSE) for machine learning. The fact that Cerebras are already going to talk about its second generation version of its WSE is quite impressive, given that the first generation WSE talk was only last year. If we’re lucky, then the 2nd generation of the WSE is going to be at the same stage the first generation was, and the company will go into as much detail as it did before.

Wafer Scale chips never looked so tasty
The final talk of the session is from ETH Zurich, showing off a 4096-core RISC-V chiplet architecture for ML. The fact that this talk says ‘architecture’ might suggest that they don’t have silicon to show off, so it will be interesting to see if they do. Also, given it’s a chiplet, I wonder if it is part of the industry effort to provide unified interfaces for chiplet design, and in that regard could be added to other silicon in order to provide acceleration.
The final session of the event is on Inference.
| Hot Chips 32 (2020): Day Two, Session 4 Machine Learning, Inference |
|||
| AnandTech | Speaker | Company | Info |
| 16h30 | Jian Ouyang | Baidu | Baidu Kunlun - An AI Processor for Diversified Workloads |
| 17h00 | Michael Xu | SenseTime | STPU: SenseTime Processing Unit |
| Wenquang Wang | |||
| 17h30 | Carl Ramay | Lightmatter | Silicon Photonics for Artificial Intelligence Acceleration |
| 18h00 | Yang Jiao | Alibaba | Hanguang 800 NPU - The Ultimate AI Inference Solution for Data Centers |
I can honestly say I don’t have much to go on here. We’ve heard of Baidu’s Kunlun a few months ago due to a press release from the company and Samsung stating that the silicon was making use of Interposer-Cube 2.5D packaging, as well as HBM2, and packing 260 TOPs into 150 W.

The talk featuring Alibaba’s Hanguang 800 NPU will also be interesting, as we saw results submitted to MLPerf back in November, though not a lot of information about the chip itself.
In Summary
With Hot Chips 32 (2020) going on-line only this year, it promises to be more accessible than previous iterations – a success this year will enable Hot Chips to offer online versions of its conference for those that do not want to attend in person. As a personal preference, I prefer going to the conference – there are plenty of side discussions and things that don’t always come across just in the presentations, so I’m looking forward to 2021 where it will hopefully avail itself to in-person attendance.
Due to the nature of the conference this year, the price for attending is at an all-time low. The maximum price for any attendant is $160 for non-IEEE members booking late and wanting access to both the tutorials and the presentations. Booking today until August 1st, the early booking price is $125. (In previous years, it has been $300+ due to venue and lunch being provided).
For anyone with a passing interest in how this silicon works, I highly recommend taking part – not only to help fund future events, but signing up and paying the fee gives you access to all the PDFs of all the presentations months before they are given to the public, and also early access to video recordings before they are made available online.
I thought last year’s Hot Chips was exciting – this year’s event will seem to at the very least match it, if not go one better. If any of the presenters at this years conference wants to get in touch before the event and take us through their presentation in advance, with the potential for a proper article on their disclosures, then please get in contact at ian@anandtech.com.

Ian Cutress (AnandTech), David Schor (wikichip), Charlie Demerjian (SemiAccurate), Paul Alcorn (Tom's Hardware), Andrea Pellegrini (Arm), Francois Piednoël (Mercedes-Benz AG)
Taken at Hot Chips 31 (2019)








64 Comments
View All Comments
Xex360 - Thursday, May 21, 2020 - link
Can you make a piece regarding quantum computing. And whether it's the future of computing, or part of it stuck as security??MrSpadge - Wednesday, July 8, 2020 - link
In short: sure it's part of the future. When and in which form it may also become part of the present is still up to R&D to decide.wr3zzz - Thursday, May 21, 2020 - link
Interesting that Alibaba, Baidu and Google are present but not Amazon.mmrezaie - Wednesday, July 8, 2020 - link
Amazon unfortunately doesn't represent much in conferences.ikjadoon - Wednesday, July 8, 2020 - link
Following Apple's lead.Two of the fastest ARM systems available today, in their respective segments, and next to nothing but virtualized SPEC benchmarks.
Anandtech has done great work, but these two are—to the dismay of the technology industry, but perhaps not consumers—zipped lips 24/7.
Teckk - Thursday, May 21, 2020 - link
Lot of sessions by Intel. Hopefully we'll get some good details on 10nm and 7nm too.Ian Cutress - Thursday, May 21, 2020 - link
Intel is a 'Rhodium' sponsor of Hot Chips this year, which is one above the standard top Platinum sponsorship level. Last year they sponsored all the lunches, break sessions, and the post-event breakouts.ingwe - Thursday, May 21, 2020 - link
They should have gone with 'Iridium'. Not that it at all matters.eastcoast_pete - Friday, May 22, 2020 - link
Or "Plutonium"; 10 nm and below is probably a radioactive subject at Intel right now.Arnulf - Sunday, May 24, 2020 - link
At least they have quite some hot chips to talk about.