HPC: LINPAC on SUSE Linux 64-bit
LINPACK, a benchmark application based on the LINPACK TPP code, has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used a workload of a 40,000 square matrix. We ran eight or sixteen threads. As the system was equipped with 16 to 32GB of RAM, the large matrixes all ran in memory. LINPACK is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We used two versions of LINPAC:
- Intel's version of LINPACK, which uses the highly optimized
Intel Math Kernel Library (MKL), version 9.1
- A "K10 only" version, which is fully optimized for AMD's quad-core.
The "K10 only" version uses the ACML version 4.0.0 and is compiled using the PGI 7.0.7. The following flags were used:
pgcc -O3 -fast -tp=barcelona-64
So basically we used the same binaries as in our previous dual-socket article. The results are comparable, but we didn't test with matrix sizes of 40,000 last time as we had less memory. We measured about 3-4% better performance with a matrix size of 40k instead of 30k on the quad-socket systems. On dual-socket systems, this was about 1-3%.
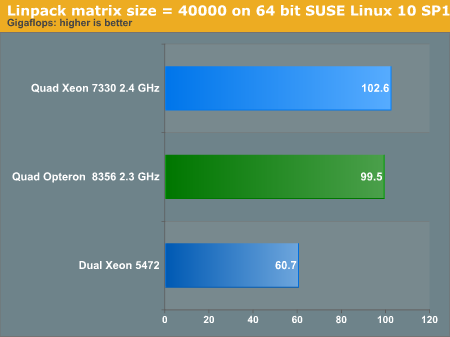
All our compiled binaries are based on Math Kernel Libraries that were available at the end of 2007. So the graph above gives you an idea how HPC code compiled for the 65nm generation of Intel will perform. With the newest Intel Math Kernels (10.0), the dual Xeon 5472 can achieve 77 GFLOPS according to Intel. AMD has released ACML 4.1.0 now. We'll update our LINPAC binaries in a later article.
To reduce the enormous amount of benchmarking time, we reduced the LINPAC testing to only 3 platforms. You can see that the Intel and AMD platforms are very close on a clock-for-clock basis. In this kind of parallel workload, quad-socket really pays off; you get a 70% performance premium over the best dual-socket platform.








0 Comments
View All Comments