Intel Xeon 7460: Six Cores to Bulldoze Opteron
by Johan De Gelas on September 23, 2008 12:00 AM EST- Posted in
- IT Computing
Our First Virtualization Benchmark: OLTP Linux on ESX 3.5 Update 2
We are excited to show you our first virtualization test performed on ESX 3.5 Update 2. This benchmarking scenario was conceived as a "not too complex" way to test hypervisor efficiency; a more complex real world test will follow later. The reason we want to make the hypervisor work hard is that this allows us to understand how much current server CPUs help the hypervisor, keeping the performance overhead of virtualization to a minimum. We chose to set up a somewhat unrealistic (at this point in time) but very hypervisor intensive scenario.
We set up between two and six virtual machines running an OLTP SysBench 0.4.8 test on MySQL 5.1.23 (INNODB Engine). Each VM runs as a guest OS on a 64-bit version of Novell's SLES 10 SP2 (SUSE Linux Enterprise Server). The advantage of using a 64-bit operating system on top of ESX 3.5 (Update 2) is that the ESX hypervisor will automatically use hardware virtualization instead of binary translation. Each virtual machine gets its own four virtual CPUs and 2GB of RAM.
To avoid I/O dominating the entire benchmark effort, each server is connected to our Promise J300S DAS via a 12Gbit/s Infiniband connection. The VMs are installed on the server disks but the databases are placed on the Promise J300S, which consists of a RAID 0 set of six 15000RPM Seagate SAS 300GB disks (one of the fastest hard disks you can get). A separate disk inside the Promise chassis is dedicated to the transactional logs; this reduces the disk "wait states" from 8% to less than 1%. Each VM gets its own private LUN.
Each server is equipped with an Adaptec RAID 5085 card. The advantage is that this card is equipped with a dual-core Intel IOP 348 1.2GHz and 512MB of DDR2, which helps us ensure the RAID controller won't be a bottleneck either.
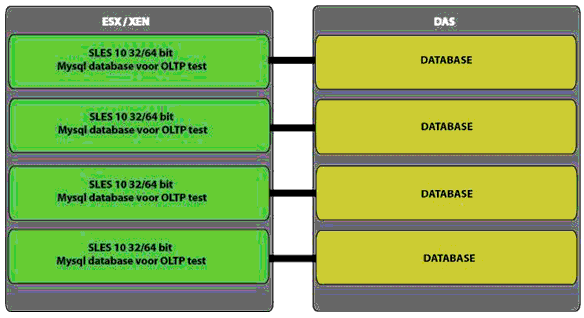
Our first virtualized benchmark scenario; the green part is the server and the yellow part is our Promise DAS enclosure.
We use Logical Volume Management (LVM). LVM makes sure that the LUNs are aligned and start at a 64KB boundary. The file system on each LUN is ext3, with the -E stride=16 option. This stride is necessary as our RAID strip size is 64KB and Linux (standard) only allows a block size of 4KB.
The MySQL version is 5.1.23 and the MySQL database is configured as follows:
max_connections=900
table_cache=1520
tmp_table_size=59M
thread_cache_size=38
#*** INNODB Specific options ***
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=10M
innodb_buffer_pool_size=950M
innodb_log_file_size=190M
innodb_thread_concurrency=10
innodb_additional_mem_pool_size=20M
Notice that we set flush_log_at_trx_commit = 1, thanks to the Battery Backup Unit on our RAID controller; our database offers full ACID behavior as appropriate for an OLTP database. We could have made the buffer pool size larger, but we also want to be able to use this benchmark scenario in VMs with less than 2GB memory. Our 1 million record database is about 258MB and indices and rows fit entirely in memory. The reason we use this approach is that we are trying to perform a CPU benchmark; also, many databases now run from memory since it is pretty cheap and abundant in current servers. Even 64GB configurations are no longer an exception.
Since we test with four CPUs per VM, an old MySQL problem reared its ugly head again. We found out that CPU usage was rather low (60-70%). The reason is a combination of the futex problems we discovered in the old versions of MySQL and the I/O scheduling of the small but very frequent log writes, which are written immediately to disk. After several weeks of testing, we discovered that using the "deadline" scheduler instead of the default CFQ (Complete Fair Queuing) I/O scheduler solved most of our CPU usage problems.
Each 64-bit SLES installation is a minimal installation without GUI (and runlevel = 3), but with gcc installed. We update the kernel to version 2.6.16.60-0.23. SysBench is compiled from source, version 0.4.8. Our local Linux gurus Philip Dubois and Tijl Deneut have scripted the benchmarking of SysBench. A master script on a Linux workstation ensures SysBench runs locally (to avoid the time drift of the virtualized servers) and makes SQL connections to each specified server while running all tests simultaneously. Each SysBench database contains 1 million records, and we start 8 to 32 threads, in steps of 8. Each test performs 50K transactions.








34 Comments
View All Comments
duploxxx - Thursday, November 13, 2008 - link
your virtualisation life was very short, perhaps marketing can keep you alive for a while since on paper you are better with the amount of cores.your 24 cores @2,66ghz are just killed by 16cores @2,7ghz
http://www.vmware.com/products/vmmark/results.html">http://www.vmware.com/products/vmmark/results.html
synergyek - Wednesday, October 15, 2008 - link
Why only testing scanline render? It's a slow and old monster. Can you add mental ray render to your tests or, maybe, vray, which is used in arch. visualizations? Also you can use Maya 32/64-bit (software, hardware, mental ray tests) for both windows and linux platforms. Mental ray on Vray uses all cores available in the system, and results must be much better, than ordinary scanline.duploxxx - Saturday, September 27, 2008 - link
Nice article, altough in virtualisation with VMmark it was already clear that the new dunnington had more headroom with the additional cores.only few remark, since you are talking about a retail price of +25000euro you could at least add for information that there are 8socket barcelona for about 5000euro more that scale again way better then dunnington with its 32 cores. So indeed intel did a step up again after there tigertown was heavy beaten by new barcelona in 4s even in low speed but at a certain cost of platform, afterall this dunnington is not cheap. it will be the question what a 4s shangai @3.0 ghz will do against this 6 core giant, afterall it is a huge die and the shangai will be way cheaper and consume less.
lets hope you update this nice article with the soon to be released shangai.
Sirlach - Friday, September 26, 2008 - link
From my research when the hex cores were announced the super micro boards came with an x16 slot. Is it possible to see how CPU restricted multithreaded games perform on this monster? Since it is running server 2008 this is theoretically possible!BaronMatrix - Thursday, September 25, 2008 - link
It seems like a better comparison would be with the number of cores the same. You could take a 4S and remove one chip and match that against a 2S Dunnington.From what I saw, it is nowhere near 50% faster though it has 50% more cores plus 4 times the cache. It looks like Intel may NEVER catch up with Opteron. Shanghai will just increase the difference.
It's just a shame Hector decided to have a "devalue the brand name" fire-sale or we'd be much closer to Bulldozer and SSE5.
trivik12 - Thursday, September 25, 2008 - link
4S has been one market where AMD dominated even after conroe's release. With Tigerton intel chipped away AMD's market share bcos of barcelona issues. with Dunnington Intel has a performance advantage. U dont look at per core performance but overall platform performance. AMD needs to catch up soon bcos with beckton AMD will be behind 8th ball in that market as well.snakeoil - Wednesday, September 24, 2008 - link
intel is cannibalizing nehalem this are desperate measures from a desperate man.this is a dead end road, sooner or later intel will have to dump the front side bus,but its evident that intel is not very confident about nehalem and quick path.
these processor are the last kick of an agonizing technology.
this is just a souped up old car. nothing more.
kingmouf - Wednesday, September 24, 2008 - link
Although a good thing for testing, I'm wondering if by making artificially the VMs more processing intensive rather than memory intensive, one is getting a quite wrong idea of the power consumption between the Intel and the AMD systems.Off-chip activity (coming from signal amplifiers, sensors, external buses etc) results in great power consumption. Actually one should expect it to be a crucial part of the total consumption of a system. In this case, I believe the AMD system has an advantage with the memory controller being incorporated in the processor chip. To one extend this also becomes clear in your testing.
Comparing the Intel CPUs one may observe that the 6-core part has a huge cache memory that seriously limits the main memory accesses. In the case of the 6VMs, there will also be reduced inter-socket communication. Both result in very serious reductions in off-chip activity, which materialises in a whopping 25% reduction in power usage.
Therefore I believe that making the benchmarking process more memory intensive, as you point is the real-world scenario, AMD could earn quite a few points there.
On a more general argument now, I can't stop thinking that chips like the 74xx Xeons are somewhat a waste of transistors. Intel is simply following the "bully" path rather than the "smart" path. I cannot stop thinking what would the results look like if instead of the two extra cores and the huge amount of cache, Intel added a TCP offload engine, a true hardware RAID controller, a block cipher accelerator, a DSP engine or an extra FP processor core (I'm not mentioning a memory controller because someone will pop up and say that they have already done that in the nehalem). All these things - and one could add much more - are integral to any server or HPC system and I believe can offer much more countable results than the two extra cores. Better performance and definitely better power usage. On the other hand, considering the weaknesses of AMD, maybe that is the company that should really get down to it.
Not long there was a lot of hype of AMD opening up their socket and coherent HyperTransport so that people could actually produce accelerators. What has happened with that? Are there any products on that market? It would be interesting to see some benchmarking with these things. :)
JohanAnandtech - Thursday, September 25, 2008 - link
"Im wondering if by making artificially the VMs more processing intensive rather than memory intensive, one is getting a quite wrong idea of the power consumption between the Intel and the AMD systems. "You are right that most virtualized workloads (including the OLTP ones) will need a lot more memory *space*, but they are not necessarily more memory intensive. It is good practice for example to use another scheduler to make it more CPU intensive: you are getting more transactions per second on the same machine. It is pretty bad to lose your watts on anything else but transactions.
jedz - Wednesday, September 24, 2008 - link
It's pretty obvious that AMD is not competing neck to neck in the server arena with their current opteron offerings because of the fact that they are way behind Intel's, and it's not right to compare the opteron to an intel7460 in terms of performance/watt. Why don't you wait for AMD's Shanghai and then redo this benchmarking process.Maybe it will do justice for AMD....