Imagination Announces PowerVR Series7XT Plus Family - Rogue Gets Improved Compute
by Ryan Smith on January 6, 2016 10:00 AM EST- Posted in
- GPUs
- Mobile
- Imagination Technologies
- PowerVR
- CES 2016

A regular sight at CES at most years is a new PowerVR graphics announcement from the crew over at Imagination, and this year is no exception. Shortly before CES last year we were introduced to the company’s PowerVR Series7XT family, a significant iteration on their base Rogue architecture that added full support for the Android Extension Pack to their GPUs, along with specific improvements to improve energy efficiency, overall graphics performance, and compute performance. Imagination also used Series7XT to lay the groundwork for larger designs containing more GPU clusters, giving the architecture the ability to scale up to a rather sizable 16 cores.
After modernizing Rogue’s graphics capabilities with Series7XT, for their follow-up Imagination is taking a slightly different path. This year they are turning their efforts towards compute, with while also working on energy and memory efficiency on the side. To that end the company is using CES 2016 to announce the next iteration of the Rogue architecture, PowerVR Series7XT Plus.
With Series7XT Plus, Imagination is focusing first and foremost on improving Rogue’s compute performance and compute capabilities. To accomplish this they are making two important changes to the Rogue architecture. First and foremost, Imagination is upgrading Rogue’s integer ALUs to more efficiently handle smaller integer formats.
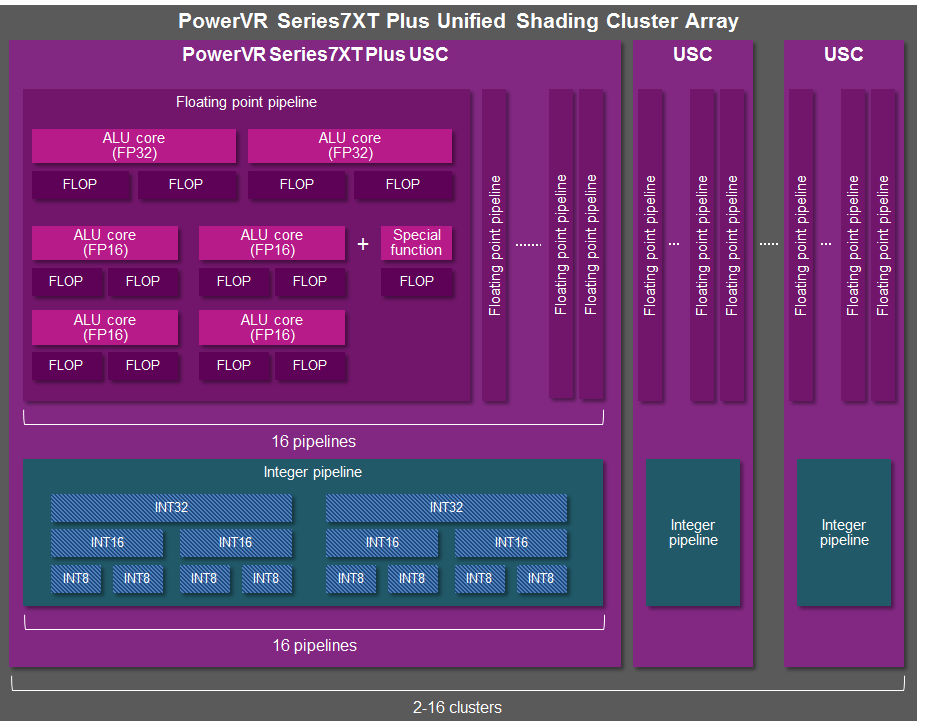
Though Imagination hasn’t drawn out the integer ALUs in previous generations’ architecture diagrams, the architecture has always contained INT32 ALUs. What has changed for Series7XT then is how those ALUs handle smaller INT16 and INT8 formats. Previously those formats would be run through the integer ALUs as INT32s, which though practical meant that there were few performance gains from using smaller integers since they weren’t really processed as smaller numbers. Series7XT Plus significantly changes this: the integer ALUs can now combine operations into a single operation based on their width. One ALU can now process 1 INT32, 2 INT16s, or 4 INT8s.
Imagination’s press release doesn’t offer a ton of detail in how they are doing this, however I suspect that they have gone with the traditional (and easiest) method, which is to simply bundle like-operations. An example of this would be bundling 4 INT8 adds into what is essentially one large INT32 addition operation, an action that requires minimal additional work from the ALU. If this is the case then the actual performance gains from using and combining smaller operations will depend on how often these operations are identical and can be bundled, though since we’re talking about parallel computing, it should be the case quite often.
From an architecture perspective this is an interesting and unexpected departure from Imagination’s usual design. One of the traditional differences between PowerVR and competitor ARM’s Mali designs is that Imagination went with dedicated FP16 and FP32 ALUs, whereas ARM would combine operations to fill out a 128-bit SIMD. The dedicated ALU approach has traditionally allowed for greater power efficiency (your ALUs are simpler), but it also means you can end up with ALUs going unused. So for Imagination to go this route for integers is surprising, though I suspect the fact that integer ALUs are simpler to begin with has something to do with it.
As for why Imagination would care about integer performance, this brings us back to compute workloads. Rather like graphics, not all compute workloads require full INT32/FP32 precision, with computer vision being the textbook example for compute workloads. Consequently, by improving their handling of lower precision integers, Imagination can boost their performance in these workloads. For a very low precision workload making heavy use of INT8s, the performance gains can be up to 4x as compared to using INT32s on Series7XT. Pragmatically speaking I’m not sure how much computer vision work that phone SoCs will actually be subjected to – it’s still a field looking for its killer apps – but at the same time from a hardware standpoint I expect that this was one of the easier changes that Imagination could make, so there’s little reason for Imagination not to do this. Though it should also be noted that Rogue has far fewer integer ALUs than FP ALUs - there is just 1 integer pipeline per USC as opposed to 16 floating point pipelines - so even though smaller integers are now faster, in most cases floating point should be faster still.
Update: Imagination has sent over a newer USC diagram, confirming that there are two integer ALUs per pipeline (with 16 pipelines) rather than just a total of two ALUs per USC.
Moving on, along with augmenting their integer ALUs, Imagination is also bringing OpenCL 2.0 support to their GPUs for the first time with Series7XT Plus. Previous PowerVR parts were only OpenCL 1.2 capable, so for Imagination 2.0 support is a big step up, and one that required numerous small changes to various areas of the Rogue architecture to support 2.0’s newer features.
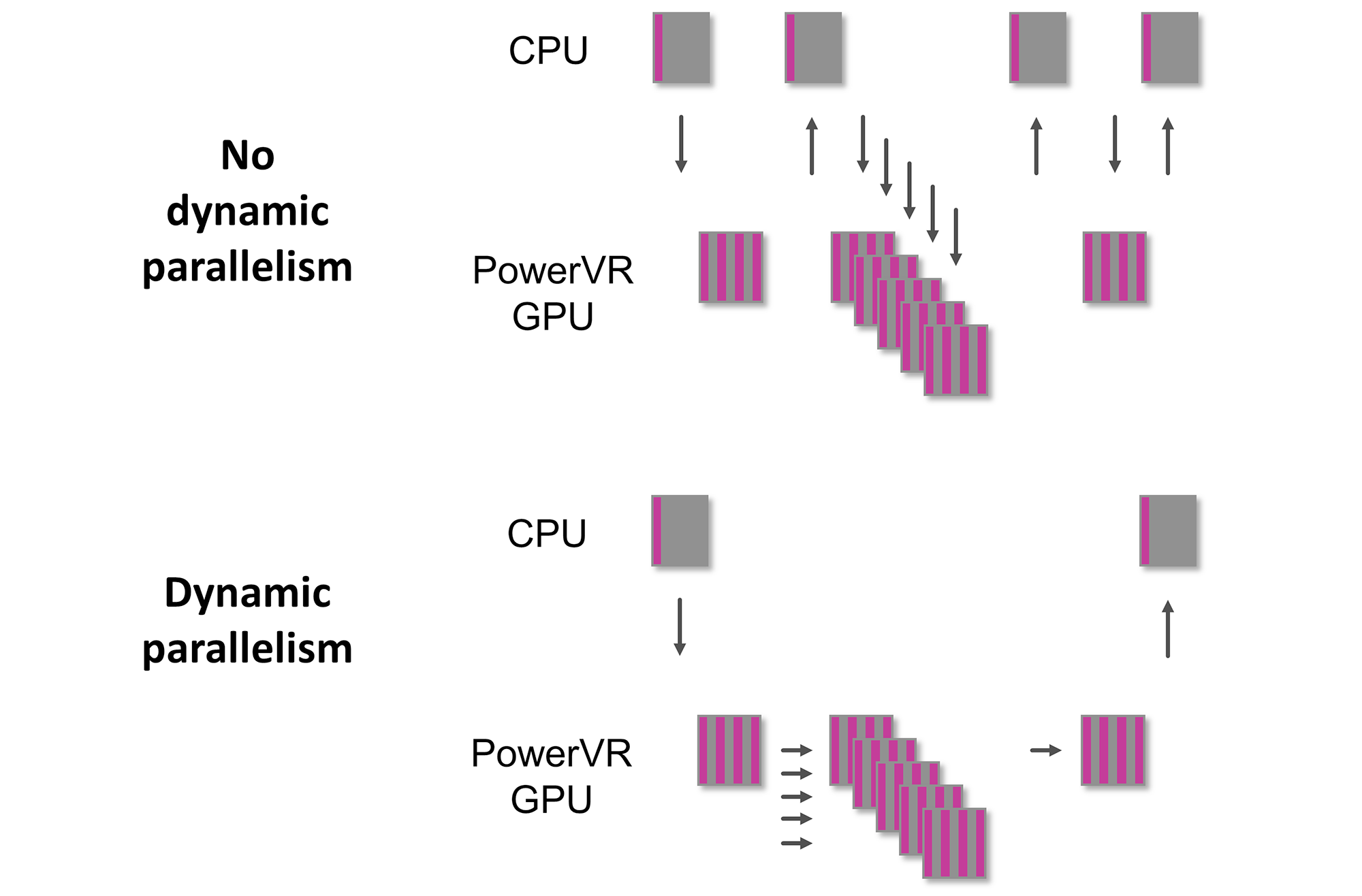
We’ve already covered OpenCL 2.0 in depth before, so I won’t go too deep here, but for Imagination the jump to OpenCL 2.0 will bring them several benefits. The biggest change here is that OpenCL 2.0 adds support for shared virtual memory (and pointers) between CPU and GPU, which is the cornerstone of heterogeneous computing. Imagination of course also develops the MIPS architecture, so they now have a very straightforward path towards offering customers a complete heterogeneous computing environment if they need one. Otherwise from a performance perspective, OpenCL 2.0’s dynamic parallelism support should improve compute performance in certain scenarios by allowing compute kernels to directly launch other compute kernels. This ultimately makes Imagination just the second mobile SoC vendor to announce support for OpenCL 2.0, behind Qualcomm and the Adreno 500 series.
Aside from compute improvements, for Series7XT Plus Imagination has also made some smaller general improvements to Rogue to further improve power efficiency. Of particular note here is the Image Processing Data Master, a new command processor specifically for 2D workloads. By routing 2D operations through this simpler command processor, Imagination can save power by not firing up the more complex pixel/vertex data masters, making this another example of how mobile GPUs have slowly been adding more dedicated hardware as the power is more important than the die size cost. Meanwhile Imagination’s press release also notes that they have made some memory system changes, including doubling the memory burst size to match newer fabrics and components (presumably this is an optimization for DDR4), and tweaking the caches and their respective sizes to reduce off-chip memory bandwidth needs by 10% or so.
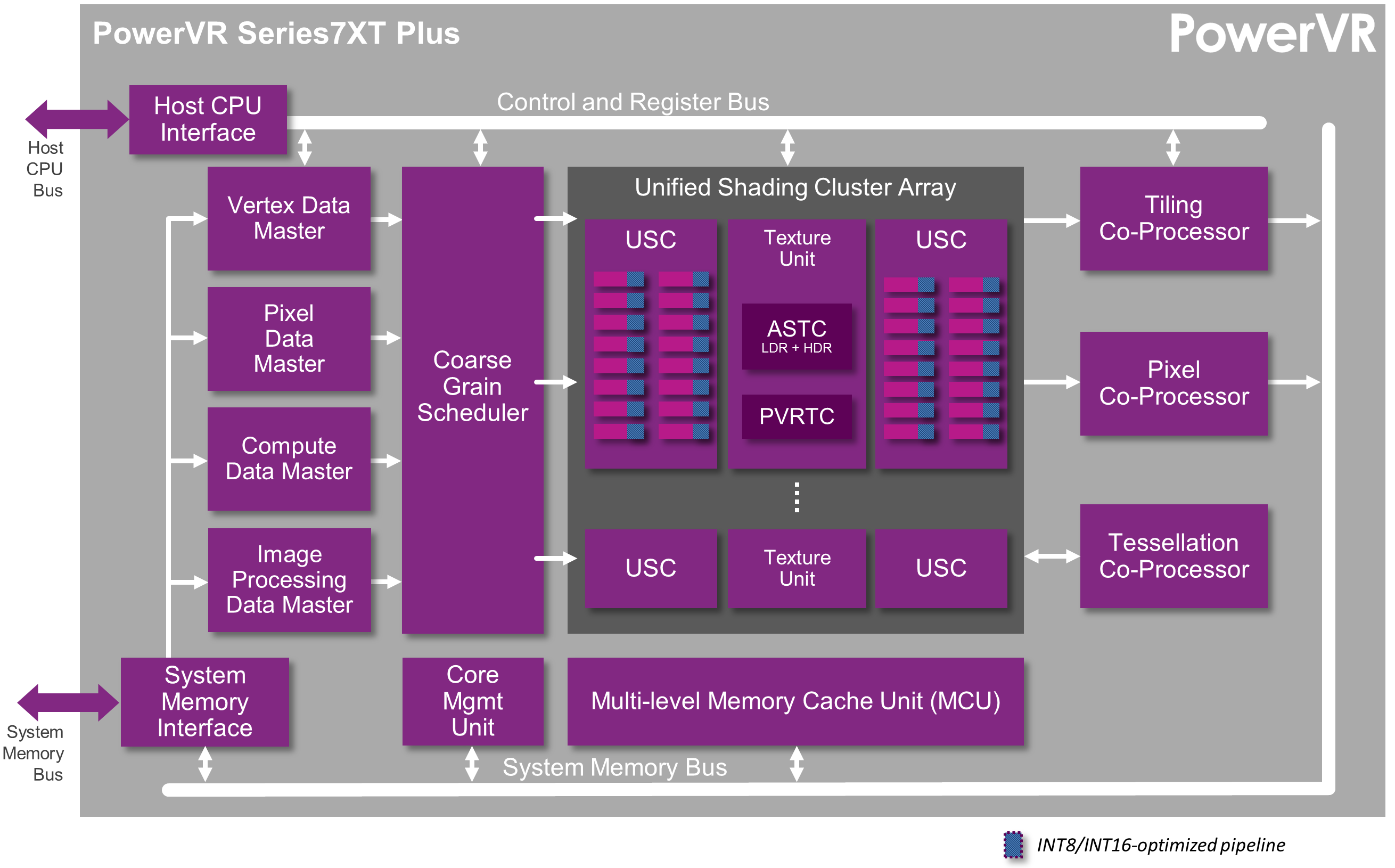
Overall these efficiency changes don’t appear to be as extensive as what we saw with Series7XT – and Imagination isn’t treating them as nearly as big of a deal – so the jump from Series7XT to Series7XT Plus shouldn’t be as great as what came before. Series7XT Plus in that regard is definitely a more incremental upgrade of Rogue, with Imagination focusing on improving a few specific use cases over the last year.
| PowerVR GPU Comparison | |||||
| Series7XT Plus | Series7XT | Series6XT | |||
| Clusters | 2 - 16 | 2 - 16 | 2 - 8 | ||
| FP32 FLOPS/Clock | 128 - 1024 | 128 - 1024 | 128 - 512 | ||
| FP16 Ratio | 2:1 | 2:1 | 2:1 | ||
| INT32 OPS/Clock | 128 - 1024 | 128 - 1024 | 128 - 512? | ||
| INT8 Ratio | 4:1 | 1:1 | 1:1 | ||
| Pixels/Clock (ROPs) | 4 - 32 | 4 - 32 | 4 - 16 | ||
| Texels/Clock | 4 - 32 | 4 - 32 | 4 - 16 | ||
| OpenGL ES | 3.2 | 3.2 | 3.1 | ||
| Android Extension Pack / Tessellation | Yes | Yes | Optional | ||
| OpenCL | 2.0 | Base: 1.2 EB Optional: 1.2 FP |
1.2 EB | ||
| Architecture | Rogue | Rogue | Rogue | ||
Finally, along with announcing the overarching Series7XT Plus family and its architecture, Imagination is also announcing two initial GPU designs for this family: GT7200 Plus and GT7400 Plus. As alluded to by their names, these are Series7XT Plus versions of the existing two-cluster GT7200 and four-cluster GT7400 designs. That imagination is only announcing smartphone designs is a bit odd – both of these designs are smaller than the GT7600 used in number-one customer Apple’s A9 smartphone SoC – though as Apple is the only customer using such a large design in a phone, for Imagination’s other customers these designs are likely more appropriate.
In any case, while Imagination does not formally announce when to expect their IP to show up in retail products, if history is any indicator, we should be seeing Seires7XT Plus designs by the end of this year and leading into 2017.
Source: Imagination








35 Comments
View All Comments
Mondozai - Wednesday, January 6, 2016 - link
I was wondering why we didn't see anything from ImgTec late last year. They had usually released their newest uarch in november or so each year, so now we know why, an iterative expansion. My guess is that the 7 series is plenty powerful for most mobiles going forward and Apple still has room to experiment - or perhaps they've taken the leap altogether and finally got their own in-house GPU and ready to show it off with the iPhone 7.The S820 benchmarks showed the Adreno 530 to be more or less on equal standing with the 7 series, so that gives them some time to refine even more for 8 series, which will probably be a significant jump, later this year.
lucam - Wednesday, January 6, 2016 - link
The Adreno 530 is just a bit quicker than GT7600 on iPhone 6s, but still far from the unknown GPU (still waiting for Anand review) inside the iPad Pro.osxandwindows - Wednesday, January 6, 2016 - link
This is probably not the GPU for the iPhone 7.tipoo - Wednesday, January 6, 2016 - link
The non S releases haven't brought major architecture changes in a while. 7 will have new externals, upclocked and tweaked internals. The S releases are where major architecture changes come.bodonnell - Wednesday, January 6, 2016 - link
I suspect we probably will see a GT7600 Plus in the Apple A10, not unlike the A7 -> A8 which switched from the G6430 to the GX6450 (both 4 cluster designs). Since the focus for the iPhone 7 will be a new design, if past non S cycle iPhones is any indication the internals will mostly be conservative tweaks from what is found in the 6s, which will include an A10 which likely offers only modest improvements over the A9.GC2:CS - Wednesday, January 6, 2016 - link
While i do agree that iPhone S-es are much more agressive with chip upgrades, iPhone 6 was limited by so called "poor" 20nm process while the next gen iPhone will supposedly go from dual-sourcing 1'st gen FInFets to single source 16nm FF+ which could leave quite a bit of room to optimize.bodonnell - Wednesday, January 6, 2016 - link
Good points, there is probably some additional gains to be made from not having to optimize for 2 processes as well as working with a more mature 2nd gen process from TSMC. That said I still think performance improvements will be modest (closer to the A7 to A8 improvement) rather than aggressive (like the A8 to A9, or the A6 to A7 improvement). I've been wrong before though!name99 - Saturday, January 30, 2016 - link
But there are lots of ways to improve without requiring substantial GPU architecture changes.Apple could go to 8 cores for A10 and 16 cores for A10X. And/or they could clock the GPU higher on a more optimized process (especially for 2D compositing, now that they have a more optimized pipe for that).
It's also possible that, as they move to fully HSA-compliant hardware, we'll see them announce an interesting framework for exploiting that --- something more modern and easier to use than OpenCL. (Or maybe just OpenCL will become a lot more practical on smaller kernels if the cost of moving data between CPU and GPU is a lot less.)
But yeah, I agree that we should expect (on CPU and GPU side) an A7 to A8 level of transition --- a nice boost, but not performance doubling.
iwod - Wednesday, January 6, 2016 - link
Still waiting for this to arrive on Desktop.blaktron - Wednesday, January 6, 2016 - link
Why? It doesn't support the latest tech, nor is it fast enough to replace the GPUs in modern CPUs. At best it does the same work for a bit less power, which is negligible on a desktop. More likely it is providing worse performance for a bit less power than a desktop architecture. Not sure why you would put a Smartphone GPU isn't a desktop addin card, but do you dude.