Arm Announces Neoverse N1 & E1 Platforms & CPUs: Enabling A Huge Jump In Infrastructure Performance
by Andrei Frumusanu on February 20, 2019 9:00 AM ESTThe Neoverse E1 CPU: A Small SMT Core for the Data-Plane
We’ve talked a lot about the Neoverse N1 – but today’s announcement actually covers two new platforms. Today actually isn’t the first time that we’ve talked about the other new platform, the new Neoverse E1. Codenamed Helios, the E1 CPU actually is derived from the Cortex-A65AE which we’ve already briefly talked about in December.


Arm largely differentiates between two big workload types in infrastructure deployments, “Compute” use-cases where we need arithmetically capable CPU cores such as the N1, and “Throughput” workloads that largely are mainly about shifting large amounts of data around. The latter category is what the new Neoverse E1 is targeting, representing a specialised CPU core that efficiently and cost effectively is able to handle such tasks.
Arm’s First SMT Core
As some might have read in the Cortex-A65AE announcement piece, the µarchitecture used in Helios both in the Cortex chip as well as in the Neoverse E1 represents Arm’s first ever foray into designing and bringing to market an SMT (simultaneous multi-threading) core. It may at first glance sound a bit weird to have SMT introduced in a smaller CPU core, as traditionally we would be thinking about SMT being useful in raising the back-end execution unit utilisation rate in larger microarchitectures, but it actually makes a lot of sense as well in smaller CPU cores whose workloads are predominantly in the data plane.

In data-processing workloads, cache misses dominate CPU work cycles. This is because we’re talking about data that inherently doesn’t have a long residence time on the CPU core, either streaming from sensors as described in the use-case of the Cortex-A65AE, or in this case streaming from the network in the case of infrastructure workloads. This means that the CPU has to deal with long memory latency accesses, introducing stalls in the CPU pipelines.
The E1 CPU is a small out-of-order design with SMT: In data-plane heavy workloads, introducing the ability to handle a secondary thread on the CPU core essentially represents almost a free throughput gain for the microarchitecture, as it’s able to fill unused execution cycles that otherwise would have just gone to waste. Indeed in optimal workloads, this can result in essentially a doubling of the throughput, on top of the single-threaded microarchitectural gains that the E1 CPU brings over predecessors such as the Cortex A55.
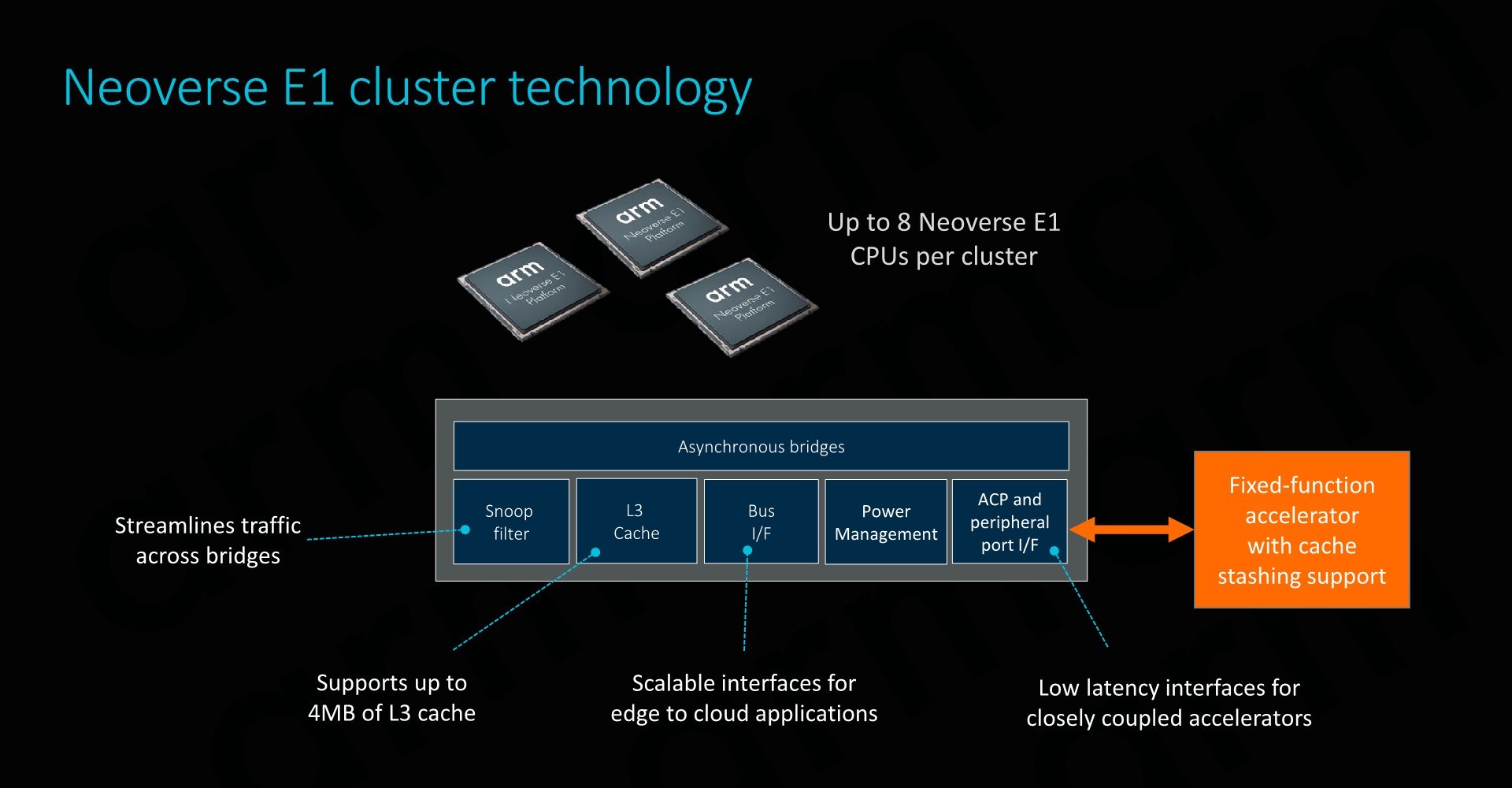
At the cluster level, the Neoverse E1 CPU configuration options are extremely similar to what we’ve seen deployable in DynamIQ systems. The cluster itself looks very much like a DSU, with up to eight cores, a cluster-level snoop filter, and an L3 cache configurable up to 4MB.
The E1 CPU’s Pipelines
The E1’s CPU pipeline actually represents a brand new-design which (besides the A65) haven’t seen employed before. What Arm has done here is take the foundation of what was the in-order Cortex A55 µarch and turned it into a minimally narrow out-of-order CPU. Moving to a basic out-of-order CPU design was essential in order to get more throughput out of the core, as it avoids stalling the whole pipeline in scenarios where we’d have a long load.
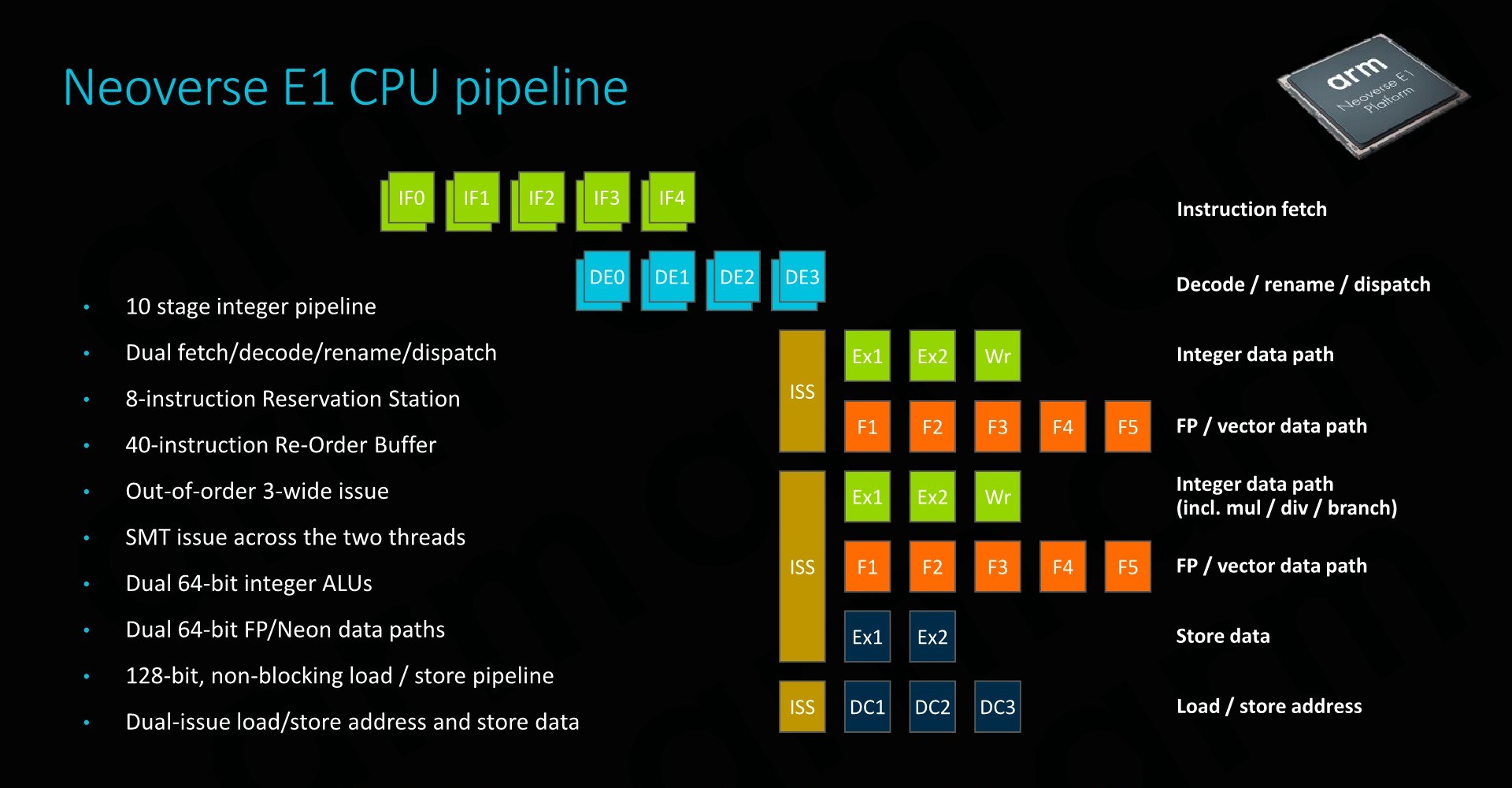
The fetch/decode/dispatch stages of the pipeline is 2-wide. In terms of its out-of-order windows, we see a small 40-deep ROB (Re-order buffer).
On the back-end we find a similar execution unit count and layout as on the Cortex-A55. A big difference to the A55 is that the integer ALUs are now differently partitioned: One ALU is dedicated for simple arithmetic operations only, while the second unit now takes over both integer multiplication as well as division tasks, whereas this was divided among the two ALUs in the A55. Interestingly, Arm also demarks the branch port being shared with this second complex integer ALUs, no longer representing it as a dedicated port as on the A55.
The SIMD/Neon pipelines seem to remain the same as on the A55 in terms of its high-level capabilities, but it is possible Arm may have improved cycle latencies of some instructions between the two generations.
Finally, the load and store ports also match the capabilities of the A55.
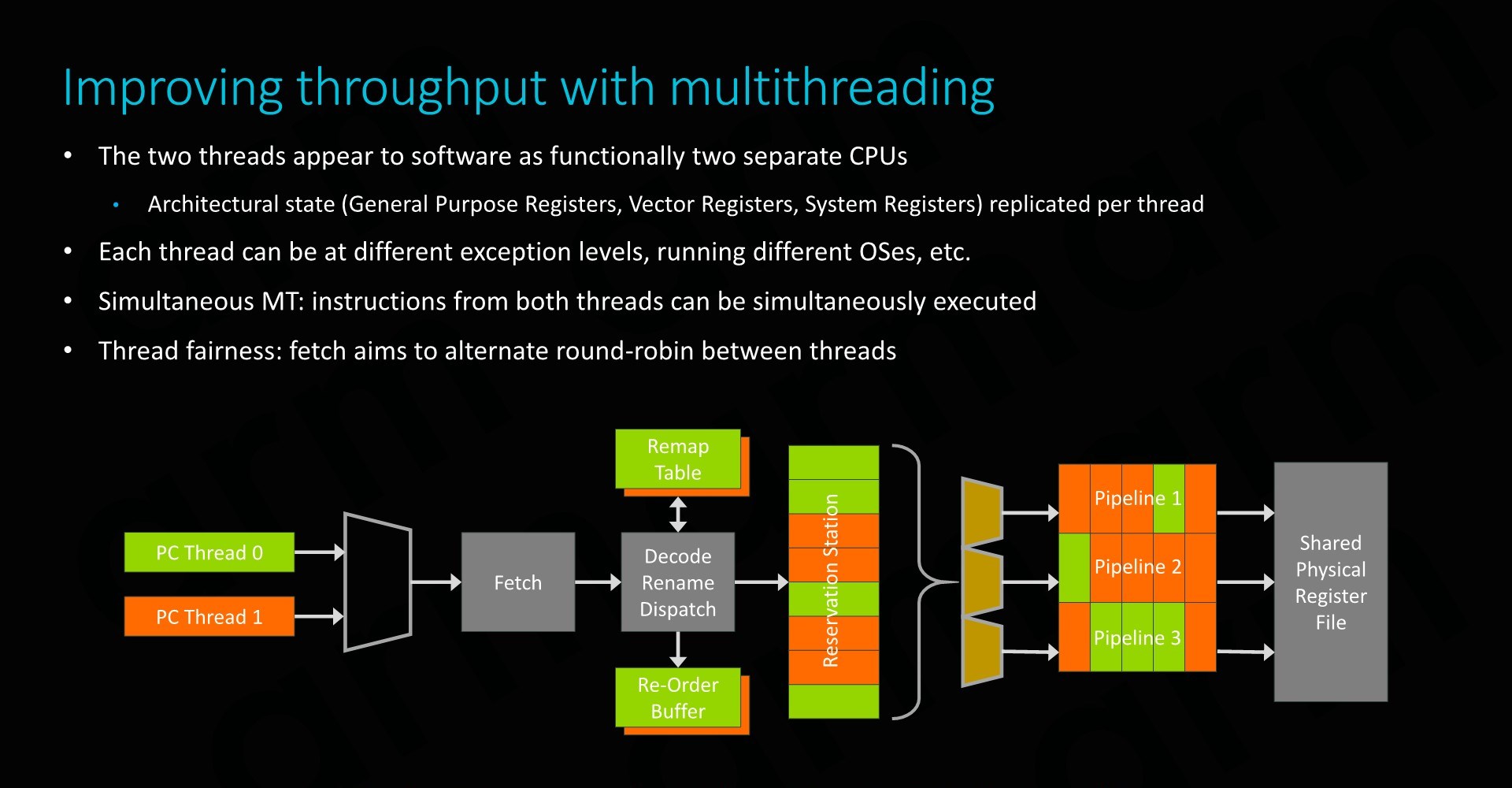
SMT on the Neoverse E1 is enabled through the duplication of architectural state components of the core. This means the CPU has double the general purpose, vector and system registers and their corresponding structures on the physical core.
At the software level, this naturally simply appears as two separate CPU cores, and can be run at different exception levels or even be running different OSes.
Performance partitioning between the two threads is enabled by a simple round-robin instruction fetch mechanism, ensuing that both threads get the same amount of attention.
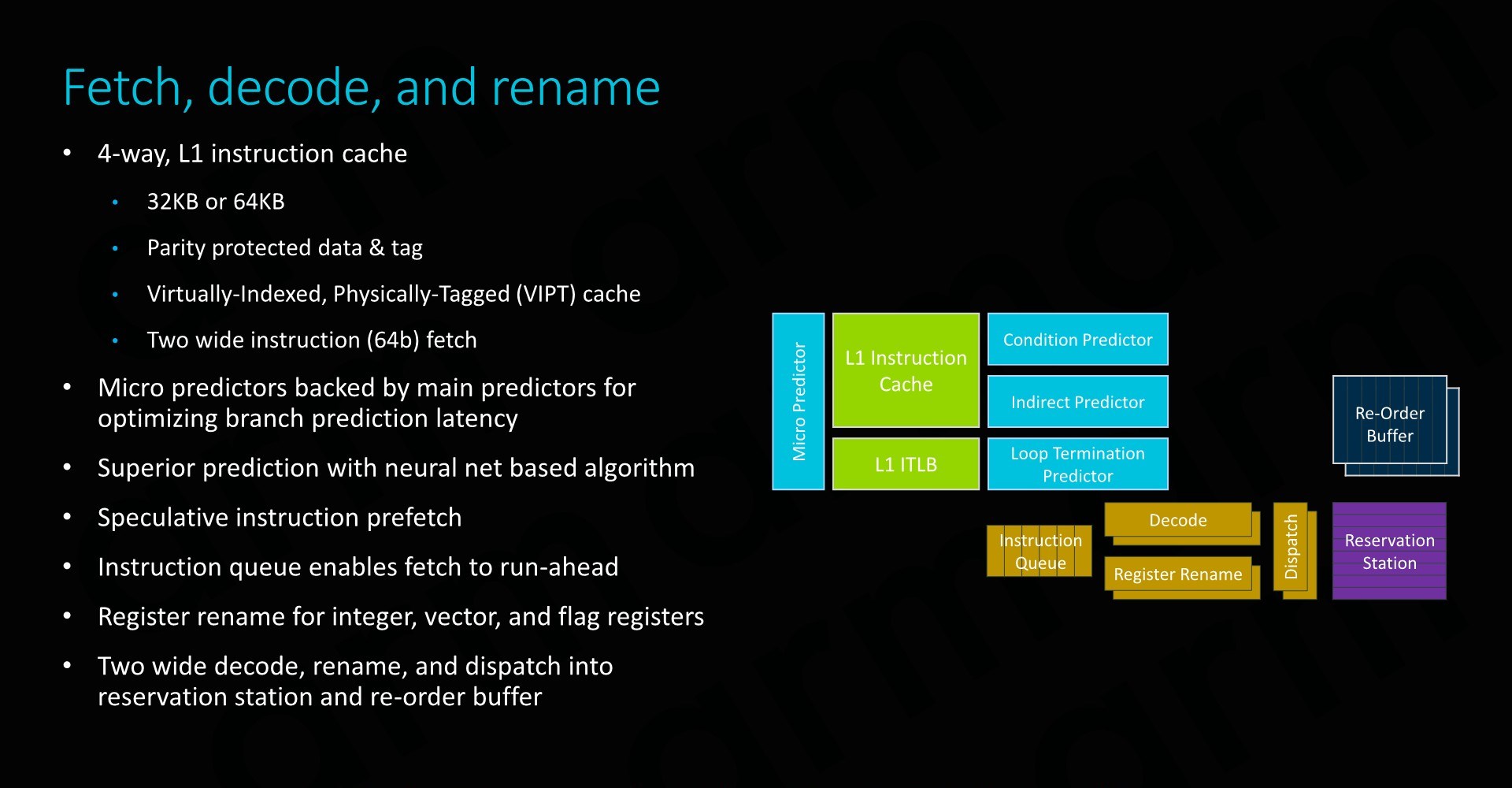

The front-end of the CPU has seen improvements in all regards and adopts many of the state-of-the art front end branch prediction and prefetch mechanisms we find in other more recent Arm OoO cores – just in a more limited implementation optimised for the smaller nature of the E1 CPU.
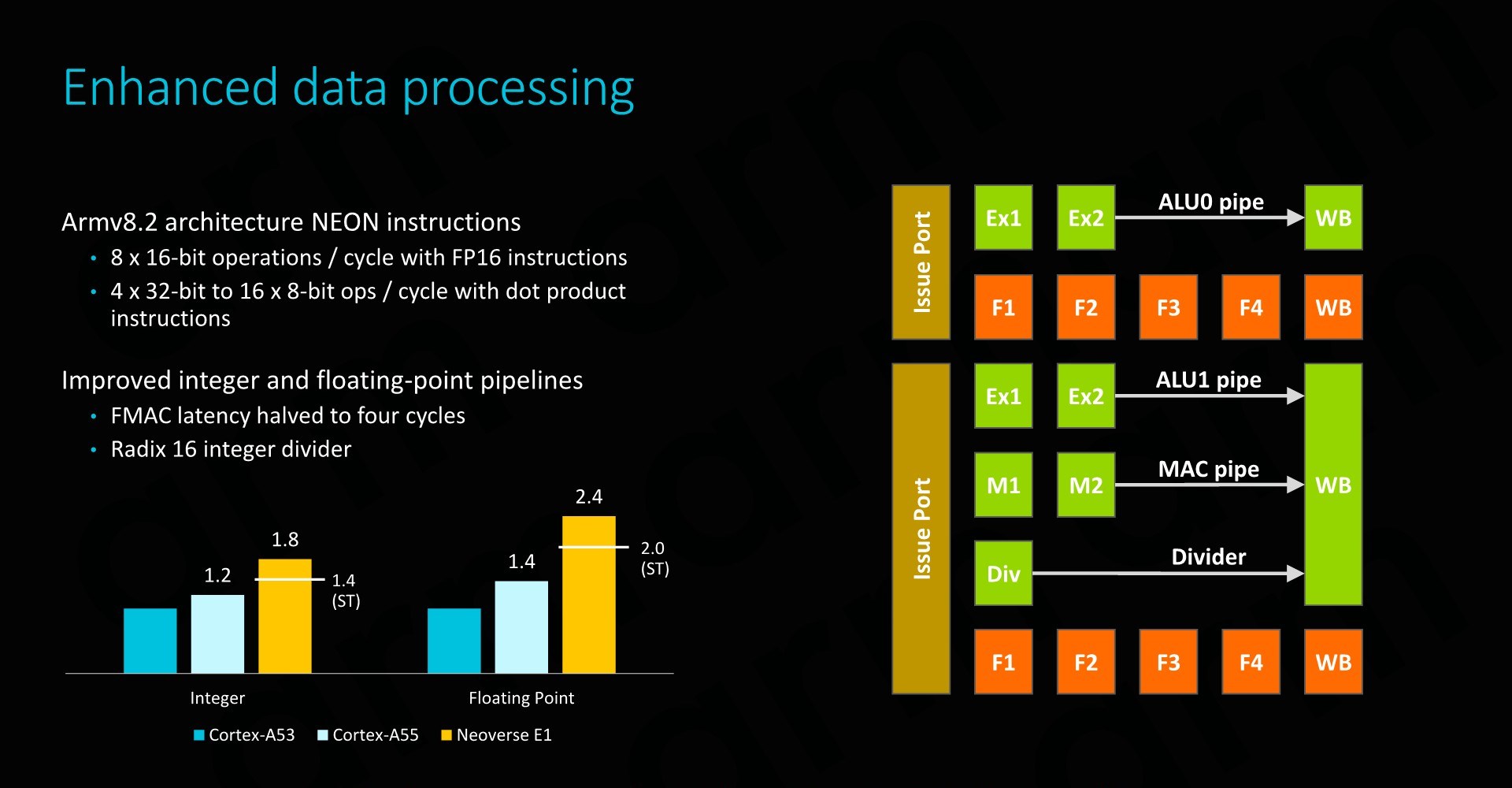
As mentioned just earlier, although the throughput of the execution pipelines hasn’t fundamentally changed, Arm has updated the execution units to employ newer designs with shorter cycle latencies. Here in particular FMAC latency has bene halved, while the integer division unit has been updated to a Radix-16 unit. It’s to be noted that these improvements are again slightly misleading as Arm is making comparisons to the Cortex A53 – the newer Cortex A55 already employed the aforementioned changed, including the new ARMv8.2 double throughput FP16 instructions as well as Int8 dot-products.

On the memory system side of things, we again see very large similarities to the Cortex A55 and the E1 enjoys the same improvements made by that µarch. The only other notable changes here are the fact that the data prefetchers as well as the L2 TLB are now multi-thread aware and are optimised in their design to better operate with the new SMT nature of the core.








101 Comments
View All Comments
surt - Thursday, February 21, 2019 - link
That raw power comes at a .... power cost. And as soon as you try to start z-stacking your cpus that power is going to be the most important factor.peevee - Tuesday, February 26, 2019 - link
"The future is way more related to modularity than the chip architecture."Debatable. Both ARM and x64 are essentially the same in terms of efficiency if the same levels of performance are required. A breakthrough can only come from in-memory computing, which neither ARM nor x64 can sustain for many reasons.
rahvin - Thursday, February 21, 2019 - link
ARM is not "more efficient at every level". That's just plain fanboi BS. The architecture is the least important aspect of any processor these days.ARM processors were traditionally designed for power efficiency above all else, now that Intel is designing down for efficiency and ARM is designing up for power there will likely be some real competition but so far ARM has not demonstrated that they can provide equivalent power for the same power budget at the high end and Intel has had difficulty matching the lower power budget and performance on the low end (though this is likely due to them wishing to avoid cannibalizing higher end products with performant low power versions).
As ARM tries to enter the server market we'll finally see if they can provide something equivalent, but it's not been a hopeful showing given that all but one ARM server design has been canceled and it's not equivalent to an x86 server processor of the same character in either power or performance.
Wilco1 - Thursday, February 21, 2019 - link
Today you can buy Arm-based servers like Operon A1100, Centriq, ThunderX, ThunderX2, eMAG and HiSilicon. The first Arm supercomputer entered the TOP500 list recently, and Fujitsu has prototypes of their Post-K computer. You can buy Arm compute time from several cloud vendors today, including AWS. That all adds up to one Arm server in your book?rahvin - Thursday, February 21, 2019 - link
ThunderX is gone, displaced by the ThunderX2 which is the Centriq processor after it was abandoned by it's creator. eMAG, A1100 and the HiSilicon Last I saw are all canceled.Commercially you can buy one ARM server, the ThunderX2. Go ahead, TRY to buy one.
Wilco1 - Thursday, February 21, 2019 - link
How could you be so clueless? ThunderX2 is based on Vulcan made by Broadcomm, no relation with Centriq at all. ThunderX is still being used and sold. Centriq is still being sold, a few months ago Gigabyte announced a brand new motherboard for it. eMAG is just announced. HiSilicon/Huawei has 2 generations of Arm servers already and is working on several more. That's the only one that isn't for sale outside of China according to AnandTech.What's next? Are you going to tell us that Arm servers did not beat Xeon and SkyLake in various benchmarks, eventhough the evidence was published in an article on AnandTech?
rahvin - Thursday, February 21, 2019 - link
Your right I confused the Vulcan and the Centriq. The Centriq is dead, the design teams gone,and there is no plan to even spin the silicon from what I've seen. Qualacom abandoned the product under threat from an activist investor. Yea there was a motherboard at CES but that doesn't mean anything at all and there is literally no way to buy one.ThunderX is depreciated (show me where you can buy one, they depreciated the silicon over a year ago, there may still be some inventory out there but I seriously doubt it), ThunderX2 is available, and from everything I saw it's awful. The best work case was as a nginx master server because the compute capacity was so awful. Basically you need a workload with a lot of threads and no actual work to even make it worth anything at all, especially considering the price.
The Huawei junk is a nonstarter, you can't buy it anywhere but China that I've seen and it's not exactly flying off the shelves either. I've seen more ARM servers announced and canceled a year later than any that made it off the shelves into an actual product. So there is an eMag, that's great show me where you can buy it.
That's my point, you can't buy them, other than the ThunderX2 or the Huawei if you want to go to china to get it. The Arm server has been a flash in the pan and I have no doubt it will continue to be so.
FunBunny2 - Wednesday, February 20, 2019 - link
one has to wonder: given the existence of C compilers for any ISA, and thus *nix OS for said ISA, when (or already?) will the maths dictate both the 'optimal' ISA and underlying microarch? both, after all, are just maths optimization problems. to some delta, there is a unique solution.zmatt - Wednesday, February 20, 2019 - link
Baring any major design flaws there shouldn't really be a difference in theoretical performance between ISAs. Its important to note that the ISA isn't the actual logic of the chip, its better thought of as a paper standard a given chip needs to conform to if it wants to be binary compatible. The real determination in performance is the microarchitecture. People conflate this with ISA a lot because they are both architectures but the Micro arch is what describes the actual logic design in the circuit. That is what Intel and AMD apply codenames to. So things like Skylake, Thunderbird, Cortex A53 etc are micro architectures.Wilco1 - Wednesday, February 20, 2019 - link
There certainly are differences between ISAs which cannot be overcome with micro-architecture no matter how much money, power or transistors you throw at it. Given equal resources, the best possible implementations of various ISAs will exhibit major performance differences.