Intel Xeon 7460: Six Cores to Bulldoze Opteron
by Johan De Gelas on September 23, 2008 12:00 AM EST- Posted in
- IT Computing
ESX 3.5 Update 2 Virtualization Results
Disclaimer: Do not try to interpret these results if you are in a hurry!
We apologize for this warning to our astute readers, for whom it will be obvious that you cannot simply take the following graphs at face value. Unfortunately, many people tend to skip the text and just look at the pictures, which could lead to many misinterpretations. We want to make it clear that when you combine three different software layers - Hypervisor, OS or "Supervisor", and Server Application - on top of different hardware, things get very complex.
In our very first virtualization benchmark, we give each VM four virtual CPUs. With two and four VMs, we do not "oversubscribe", i.e. each virtual CPUs corresponds at least one physical CPU. In the case of six VMs, we oversubscribe some of the servers: the Xeon 73xx (Tigerton) and Opteron (Barcelona) platforms only have 16 physical CPUs, and we allocate 24. Oversubscribing is a normal practice in the virtualization world: you try to cut your costs by putting as many servers as is practical on one physical server. It's rare that all your servers are running at 100% load simultaneously, so you allow one VM to use some of the CPU power that another VM is not currently using. That is the beauty of virtualization consolidation after all: making the best use of the resources available.
The virtual CPUs are not locked to physical cores; we let the hypervisor decide which virtual CPU corresponds to which physical CPU. There is one exception: we enable NUMA support for the Opteron of course. For now, we limit ourselves to six VMs as several non-CPU related (probably storage) bottlenecks kick in as we go higher. We are looking at how we can test with more VMs, but this will require additional research.
This limit is a perfect example for understanding how complex virtualization testing can get. We could disable flushing the logs immediately after commit, as this would reduce the stress on our disk system,and make it a more CPU limited benchmark even with more than six VMs. However, this would mean that our test loses ACID compliance, which is important for an OLTP test. In a native test, this may be acceptable if you are just looking to test the CPU performance; it's probably just a matter of adding a few more spindles. However, this kind of reasoning is wrong when you work with virtualized servers. By disabling the immediate flushing of logs, you are lowering the impact on the hypervisor in several ways. Your hypervisor has to do less work, hence the impact on the CPU is lowered, and the objective of this test is to see how well a CPU copes with a virtualized environment.
Consolidation courtesy of virtualization is a compromise between performance per VM and total throughput of the physical machine. You want to put as many virtual servers as possible on one physical server to maximize throughput and cost reduction, but you do not want to see individual VM performance decrease below a certain threshold. If you sacrifice too much individual virtual server performance in order to get more VMs on one server, your CFO will be happy but your users will complain. It is therefore important to look at both the performance per virtual server and total throughput of the physical machine. The first graph shows you the number of transactions per Virtual Server. For those interested, this is an average and individual virtual servers show +/-5% compared to this average.
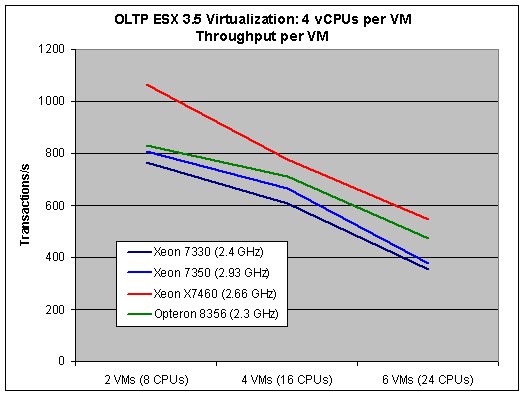
As expected, the highest result per virtual server is achieved if we only run two VMs. That is normal, since it means that the physical server has eight CPUs left to handle the console and hypervisor overhead. Nevertheless, those two factors cannot explain why our results fall so much once we activate four VMs and all 16 CPUs cores are busy.
| Performance loss from 2 VMs to 4 VMs | |
| Xeon 7330 (2.4GHz) | -21% |
| Xeon 7350 (2.93GHz) | -17% |
| Xeon X7460 (2.66GHz) | -27% |
| Opteron 8356 (2.3GHz) | -15% |
Our internal tests show that you should expect the Hypervisor to require about 12% of the CPU power per VM and the impact of the console should be minimal. In the first test (two VMs) there is more than enough CPU power available as we use only half (Opteron 8356, Xeon 73xx servers) to one third (X7460 server) of what is available. The real performance losses however are in the range of 15% (Opteron) to 27% (Xeon X7460). So where is the other bottleneck?
The database is 258MB per VM, and therefore runs almost completely in our INNODB buffer pool. We suspect the extra performance comes from the extra bandwidth that two extra VMs demand. Notice how the Opteron - the server with the highest bandwidth - has the lowest loss. That gives us our first hint, as we know that more VMs also result in higher bandwidth demands. Secondly, we see that the Xeon X7350 loses a little less than the E7330 (percentagewise) when you fire up two extra VMs. The slightly bigger cache on the X7350 (2x4MB) reduces the pressure on the memory a bit.
Next, we compare the architectures. To do this, we standardize the Xeon E7330 (2.4GHz) result to 100%.
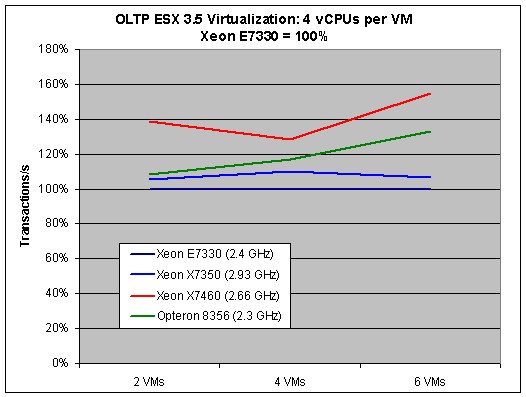
This graph is worth a very close investigation, since we can study the impact of the CPU core architecture. As we are using only eight CPUs and 4GB if we run two VMs, the Xeon 7460 cannot leverage its most visible advantage: the two extra cores. With two VMs, performance is mostly determined - in order of importance - by:
- (Futex) Thread synchronization (we have up to 32 threads working on the database per VM)
- Raw integer crunching power
- VM to Hypervisor switching time (to a lesser degree)
The X7460 is based on the Penryn architecture. This 45nm Intel core features slightly improved integer performance but also significantly improved "VM to Hypervisor" switching time. On top of that, synchronization between CPUs is a lot faster in the X74xx series thanks to the large inclusive L3 cache that acts as filter. Memory latency is probably great too, as the VMs are probably running entirely in the L2 and L3 caches. That is the most likely reason why we see the X7460 outperform all other CPUs.
Once we add two more VMs, we add 4GB and eight CPUs that the hypervisor has to manage. Memory management and latency become more important, and the Opteron advantages come into play: the huge TLB ensures that TLB misses happen a lot less. The TLB is also tagged, making sure "VM to Hypervisor" switching does not cause any unnecessary TLB flushes. As we pointed out before, the complex TLB of the Barcelona core - once the cause of a PR nightmare - now returns to make the server platform shine. We measured that NPT makes about a 7-8% difference here. That might not seem impressive at first sight, but a single feature capable of boosting the performance by such a large percentage is rare. The result is that the Opteron starts to catch up with the Xeon 74xx and outperforms the older 65nm Xeons.
The impact of memory management only gets worse as we add two more VMs. The advantages described above allow the Opteron to really pull away from the old Xeon 73xx generation. However, in this case the Xeon X7460 can leverage its eight remaining cores, while the Opteron and older Xeon servers do not have that luxury. The hypervisor has to juggle six VMs that are demanding 24 cores, while there are only 16 cores available on the Opteron and Xeon 73xx servers. That is why in this case the Xeon X7460 is again the winner here: it can consolidate more servers at a given performance point than the rest of the pack.
To appreciate what the 6-core Xeon is doing, we need to look at the total throughput.
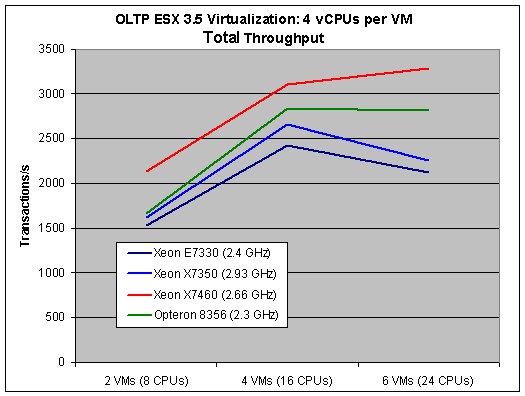
Notice how the Opteron is able to keep performance more or less stable once you demand 24 virtual CPUs, while the performance of Xeon 73xx takes a nosedive. The winner is of course the Intel hex-core, which can offer 24 real cores to the hypervisor. The Dunnington machine is capable of performing almost 3300 transactions per second, or no less than 45% more than its older brother that is clocked 11% higher. The Opteron does remarkably well with more than 2800 transactions per second, or about 24% better than the Xeon that has twice the cache and a 27% better clock speed (X7350 at 2.93GHz).








34 Comments
View All Comments
JarredWalton - Tuesday, September 23, 2008 - link
Heh... that's why I love the current IBM commercials."How much will this save us?"
"It will reduce our power bills by up to 40%."
"How much did we spend on power?"
"Millions."
[Cue happy music....]
What they neglect to tell you is that in order to achieve the millions of dollars in energy savings, you'll need to spend billions on hardware upgrades first. They also don't tell you whether the new servers are even faster (it's presumed, but that may not be true). Even if your AC costs double the power bills for a server, you're still only looking at something like $800 per year per server, and the server upgrades cost about 20 times as much every three to five years.
Now, if reduced power requirements on new servers mean you can fit more into your current datacenter, thus avoiding costly expansion or remodeling, that can be a real benefit. There are certainly companies that look at density as the primary consideration. There's a lot more to it than just performance, power, and price. (Support and service comes to mind....)
Loknar - Wednesday, September 24, 2008 - link
Not sure what you mean: "reduced power requirements means you can fit more into your DC". You can fill your slots regardless of power, unless I'm missing something.Anyway I agree that power requirement is the last thing we consider when populating our servers. It's good to save the environment, that's all. I don't know about other companies, but for critical servers, we buy the most performing systems, with complete disregard of the price and power consumption; because the cost of DC rental, operation (say, a technician earns more than 2000$ per year, right?) and benefits of performance will outweigh everything. So we're so happy AMD and Intel have such a fruitful competition. (And any respectable IT company is not fooled by IBM's commercial! We only buy OEM (Dell in my case) for their fast 24-hour replacement part service and worry free feeling).
JarredWalton - Wednesday, September 24, 2008 - link
I mean that if your DC has a total power and cooling capacity of say 100,000W, you can "only" fit 2000 500W servers in there, or you could fit 4000 250W servers. If you're renting rack space, this isn't a concern - it's only a concern for the owners of the data center itself.I worked at a DC for a while for a huge corporation, and I often laughed (or cried) at some of their decisions. At one point the head IT people put in 20 new servers. Why? Because they wanted to! Two of those went into production after a couple months, and the remainder sat around waiting to be used - plugged in, using power, but doing no actual processing of any data. (They had to use up the budget, naturally. Never mind that the techs working at the DC only got a 3% raise and were earning less than $18 per hour; let's go spend $500K on new servers that we don't need!)